
Source: Graph Science Lab
This article is about 4000 words long and is recommended to be read in 8 minutes.
This article introduces the transition states in multimodal learning—Latent Modal.
Background
With the advancement of large models, single-modal large models can no longer adequately meet the needs of real-world work. Many research teams and institutions have begun to study multimodality. Several multimodal architectures have been introduced in previous articles, and this part will not be elaborated further. The ideal multimodal system would be one without modality, where a single model can input various data indiscriminately and generate any desired output based on control needs. In other words, we can align the relationships between all modalities using one model. To achieve this goal, there are at least three architectures:
1. Pull various modality inputs/outputs horizontally, design each part corresponding to the modality in blocks, and through task design, let one type of input data predict the output data values. By training with enough data, the model learns the correspondence between modalities;
2. During training, only one type of modality data is input/output, allowing the model to learn the correspondence between modalities;
3. Map various modalities into a unified space and align the mapping relationships between modalities in that unified space.
The first two architectures are one-stage training methods, meaning that data between various modalities does not need to go through the step of mapping to latent space. Directly aligning information across various modalities and granularities theoretically provides a stronger expression capability for one-stage models, provided there is enough data. However, challenges such as data collection difficulty, data processing difficulty, training costs, and computation requirements for downstream tasks have led to a mainstream preference for two-stage alignment training architectures. That is:
1. First, map each modality’s data into a space separately;
2. Then, through task design for aligning multiple modal data, achieve modality alignment.
However, during the modality alignment process, task design can be further subdivided based on whether to consider data sequences, training task difficulty, and training task generality. The performance of models produced under different task designs can vary significantly.
The differences between the three models introduced below: clip, blip2, and mini-chatgpt4 are as follows:
1. clip: Training data does not consider the sequence between data, and task design involves similar calculations between images and text;
2. blip2: Training data does not consider sequences, task design includes similar calculations, modality fusion tasks, VQA, and image-to-text generation;
3. mini-chatgpt4: Considers data sequences (single image multi-turn dialogues) and generates image multi-turn dialogue.
Transition State Models
2.1 clip
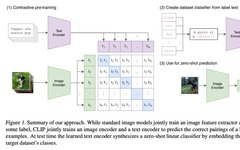
CLIP (Contrastive Language-Image Pre-Training) is a neural network trained on pairs of (image, text). It can predict the most relevant text segments based on given images using natural language instructions, possessing zero-shot prediction capabilities similar to GPT-2 and 3. CLIP performs comparably to the original ResNet50 on the ImageNet zero-shot task, even predicting samples not included in the original training set of 128 million labeled data.
CLIP’s training tasks include: 1. Calculating similarity between image-text pairs 2. Given image embeddings, predicting the categories of objects in the image through text instructions.
Training data: 400M image-text pairs collected from web scraping, using weak supervision (presumably multiple rounds of boosting). 500,000 internet queries, each recalling 20,000 data points, with image embeddings extracted using both resnet and VIT architectures, and text embeddings using a transformer with 63M parameters, 12 layers, 512 input length, and 8 attention heads for masked self-attention. The amount of data, the transformation to prompt, and the zero-shot performance of image-text classification pairs significantly enhance the information representation capability. (Task design and data selection should be very important)
2.2 BLIP-2
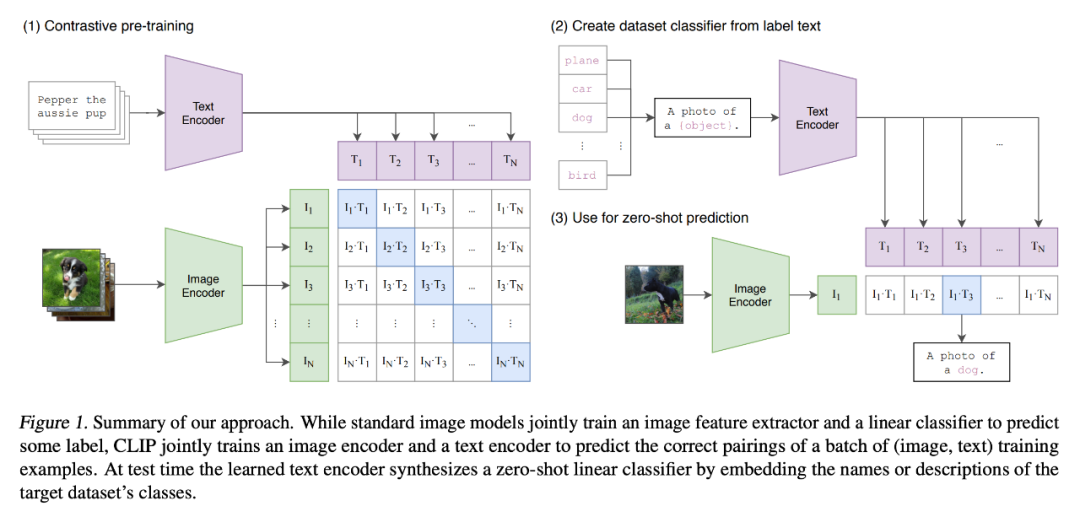
The cost of end-to-end training for large-scale models in visual and language pre-training has become increasingly high. To address the expensive training of large models, BLIP-2 proposes a universal and efficient pre-training strategy that can bootstrap visual and language pre-training from existing frozen pre-trained image encoders and frozen large language models.
BLIP-2 bridges the modality gap using a lightweight query transformer that is pre-trained in two phases. The first phase bootstraps visual-language representation learning from the frozen image encoder. The second phase bootstraps visual-to-language generation learning from the frozen language model. BLIP-2 achieves state-of-the-art performance across various visual-language tasks, despite requiring significantly fewer training parameters than existing methods.
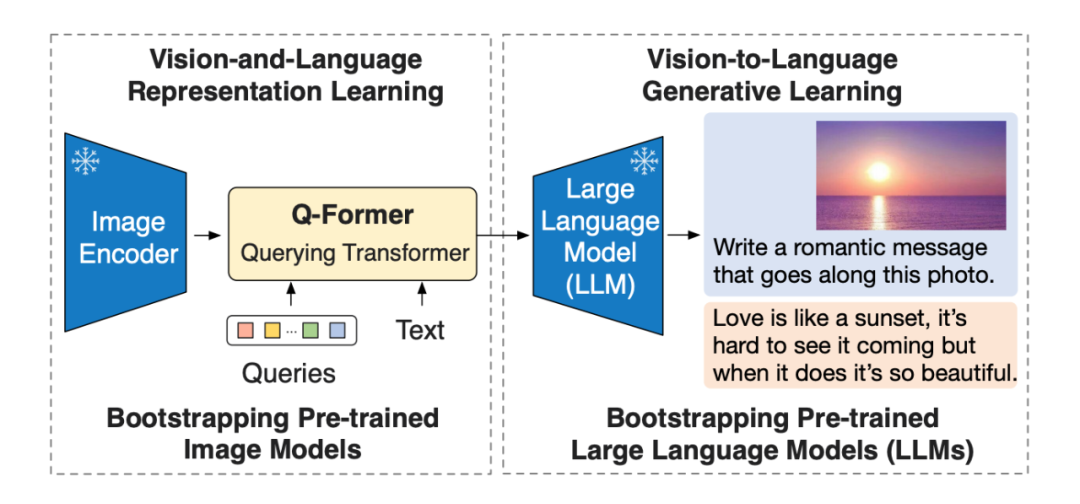
Overview of the BLIP-2 framework. It employs a two-stage strategy to preprocess a lightweight query transformer to address the differences between two modalities. The first stage bootstraps visual-language representation learning from a frozen image encoder. The second stage bootstraps visual-to-language generation learning from a frozen LLM, enabling zero-shot image-to-text generation.
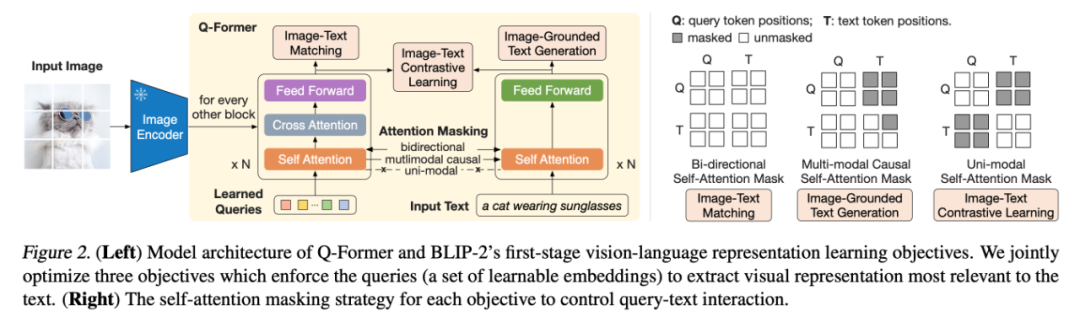
A fixed visual pre-training model trains a Q-Former to encode the semantics from image input into a feature space similar to that of text features. Specifically, the model retrieves features from images based on K learnable query embeddings and a cross-attention mechanism. The three tasks include:
1. Image-text matching: Classifying the input (image, text) pair to determine if they are related;
2. Image-based text generation: Given an image input, generate the corresponding text description;
3. Image-text contrastive learning: Reducing the distance between image features and corresponding text features while increasing the distance to unrelated text features.
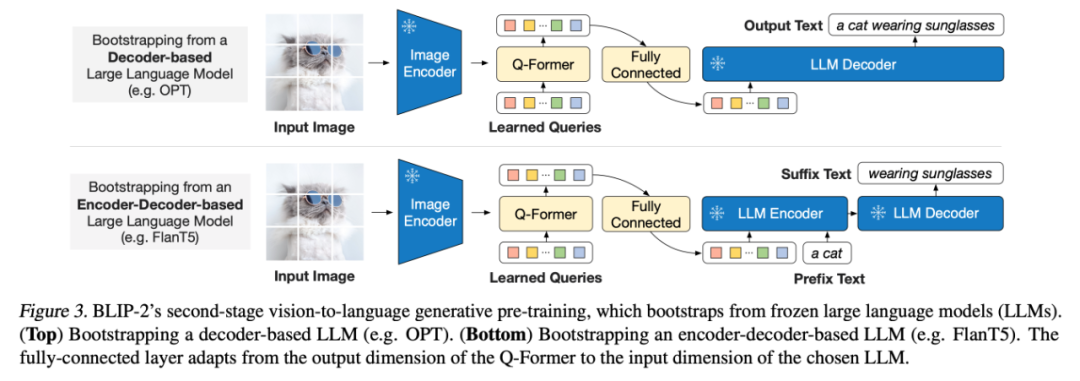
The output of the Q-Former is fed into a fixed large language model through a fully connected network, further encoding the visual features that have been preliminarily aligned with text features into inputs that the large language model can understand through the image-based text generation task.
Advantages:
By using fixed unimodal pre-trained models, BLIP-2 significantly reduces the computational and data resources required for pre-training;
It only took 129M image-text pairs, and a machine with 16 A100 (40G) GPUs can complete training of the largest BLIP-2 in less than 9 days;
By fixing the parameters of the large language model, BLIP-2 retains the instruction-following capabilities of the large language model.
Disadvantages:
The model lacks multimodal in-context learning capabilities.
2.3 MiniGPT-4
From blip2, we can see the two-stage training method: the first stage is for learning image-text representation capabilities, and the second stage uses image-text embeddings as soft prompts for prefix generation. This approach goes a step further than clip, which only learns image-text representation capabilities, by guiding the text generation method through generated prompts to better align the image and text in the mapping space.
The goal of MiniGPT-4 is to align a trained visual encoder with an advanced large language model (LLM), using Vicuna as the language decoder, which is built on LLaMA and capable of performing various complex language tasks. For visual perception, we use the same visual encoder as BLIP-2 and combine it with its trained Q precursor. Both the language and visual models are open source. Using a linear projection layer, a designed dialogue template aligns the visual encoder and LLM via a single path. A two-stage training method is proposed:
1. The initial stage involves pre-training the model on a large number of aligned image-text pairs to acquire visual-language knowledge;
2. In the second stage, a smaller but high-quality image-text dataset is used to fine-tune the pre-trained model with a designed dialogue template to enhance the model’s generation reliability and usability.
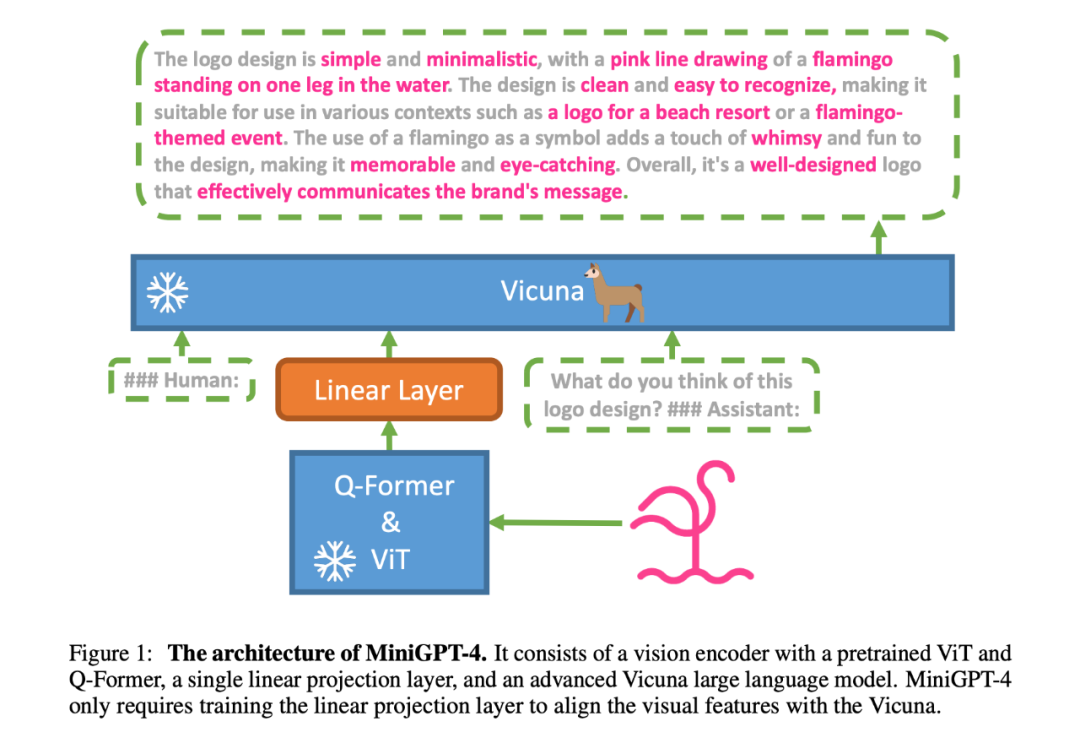
2.4 First Pre-training Stage
In the first pre-training stage, tasks are designed to allow the model to acquire visual-language knowledge from aligned image-text pairs. The output of the injected projection layer is used as a soft prompt for the LLM, prompting it to generate corresponding real text.
Throughout the pre-training process, both pre-trained visual encoders and LLMs remain frozen, with only the linear projection layer being trained. Public datasets such as Conceptual Captions, SBU, and LAION are used to train the model. The process involves around 20,000 training steps with a batch size of 256, covering approximately 5 million image-text pairs. It uses 4 A100 (80GB) GPUs, taking about 10 hours in total. The task design involves embedding images as soft prompts for text generation:
<Img><ImageFeature></Img> Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
After the first pre-training stage, MiniGPT-4 demonstrates the ability to possess rich knowledge and provide reasonable answers to human questions. However, it is observed that it sometimes struggles to generate coherent linguistic outputs, such as repeating words or sentences, producing fragmented sentences, or generating irrelevant content. These issues hinder MiniGPT-4’s ability to engage in smooth visual dialogues with humans.
Similar issues are also present in GPT-3. Despite being pre-trained on extensive language datasets, GPT-3 cannot directly generate linguistically appropriate outputs that align with user intentions. Through learning from human feedback, instruction fine-tuning, and reinforcement learning, GPT-3 gradually evolved into GPT-3.5, capable of generating more human-like outputs. This phenomenon is similar to MiniGPT-4’s state after the first pre-training stage. The model may struggle to produce smooth and natural linguistic outputs at this stage. To enhance the naturalness of generated language and improve model usability, a second alignment process is required. While instruction fine-tuning and dialogue datasets are readily available in the NLP field, similar datasets are lacking in the visual-language domain. To address this, a high-quality image-text dataset specifically designed for alignment needs to be carefully crafted. This dataset will subsequently be used for fine-tuning MiniGPT-4 during the second alignment process.
Initial aligned image-text generation. In the initial stage, the model generates a detailed description of a given image using the model derived from the first pre-training stage. To prompt the model to generate more detailed image descriptions, a prompt following the Vicuna language model dialogue format is designed as follows:
###Human: <Img><ImageFeature></Img> Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
In this prompt, the visual features generated by the linear projection layer are represented.
To identify incomplete sentences, it is necessary to check whether the generated sentences exceed 80 words. If not, another prompt can be added, ###Human: Continue ###Assistant: , prompting MiniGPT-4 to continue generating sentences. By merging the outputs of the two steps, a more comprehensive image description can be created. This approach enables the model to generate more detailed and informative image descriptions. A random selection of 5,000 images from the Conceptual Captions dataset is used, and this method generates corresponding language descriptions for each image.
Data preprocessing: The generated image descriptions still contain many noise and errors, such as repeated words or sentences, and issues with unreasonable statements. To mitigate these issues, ChatGPT is utilized to optimize descriptions through subsequent prompts.
Post-processing: After preprocessing, each image description is manually checked for correctness to ensure quality. Specifically, each generated image description is checked for adherence to the desired format, and generated titles are manually optimized by removing repeated words or sentences that ChatGPT cannot detect. Ultimately, only about 3,500 image-text pairs meet my requirements, and these pairs are subsequently used for the second alignment process.
2.5 Second Hyperparameter Tuning Stage
In the second hyperparameter tuning stage, we use curated high-quality image-text pairs for hyperparameter tuning. During hyperparameter tuning, we utilize predefined prompts within the following template:
###Human: <Img><ImageFeature></Img> <Instruction> ###Assistant:
In this prompt, represents our randomly sampled instruction set, which includes variations of instructions such as “Describe this image in detail” or “Can you describe the content of this image for me?” It is important to note that we do not use the regression loss of this specific text-image prompt.
As a result, MiniGPT-4 is now capable of producing more natural and reliable responses. Furthermore, we observe that the hyperparameter tuning process for the model is very efficient, requiring only 400 training steps, a batch size of 12, and completing in a brief 7 minutes on a single A100 GPU.
Advantages:
1. Research shows that aligning a frozen visual encoder with an advanced large language model Vicuna can yield emerging visual-language capabilities;
2. By using pre-trained visual encoders and large language models, MiniGPT-4 achieves higher computational efficiency. Research results indicate that training only a projection layer can effectively align visual features with large language models. MiniGPT-4 only requires about 10 hours of training on 4 A100 GPUs;
3. Merely using raw image-text pairs from public datasets to align visual features with large language models does not yield a well-performing MiniGPT-4 model. It may produce inconsistent outputs (including repeated and fragmented sentences). Addressing this issue requires using high-quality, well-aligned datasets, which significantly improves usability.
Conclusion
Currently, multimodal large models primarily focus on image-text alignment and text generation, and cannot yet generate images and text together.
From clip to blip2 to minichatgpt4, unifying input formats and task designs has become a trend.
mini-chatgpt4 also fails to achieve true in-context image-text generation; it only aligns the first and second stage learning tasks, where the input is: image, text softmax to unify representation and generation tasks. The second stage maintains the same data format but requires longer sequences and higher quality human-filtered data for alignment.
From the trend of image-text multimodality, task design should involve inputs of: instruct, image, text, content==> output: image, text, content, annotate; this approach is essential to achieve true in-context image-text multimodality, solving in-context image-text tasks by introducing time series variables from the human physical world.
Whether latent modal learning will eventually merge with raw text, pixel-level data, or more fine-grained image-text features remains to be seen. Addressing fine-grained image-text controllable generation is a direction worth paying attention to (though doing so will impose high requirements on training data, training techniques, and computational power).
Editor: Yu Tengkai
Proofreader: Lin Yilin