I originally planned to write an article titled “A Two-Year Review of ChatGPT” to echo last year’s summary article on the first anniversary of ChatGPT. However, I’ve been too busy lately, and now that it’s almost mid-January, this topic no longer seems appropriate. So, I’ve decided to change the subject and discuss the developments over the past year in the ecosystem of foundational models and middleware tools from a developer’s perspective. The article will be divided into three parts:
Foundational Models: Summarizing the developments in foundational models over the past year, which is fundamental.
Developer Tool Ecosystem: Discussing the development of the large model developer tool ecosystem, covering foundational model service providers, middleware products, and notable open-source projects.
Focus Areas for 2025: Finally, I will briefly discuss the AI development directions I will focus on in 2025.
Feel free to jump around based on your interests. If you find the content helpful, please follow, share, and engage~ Enjoy 🫡
Foundational Models
Multimodal Models
During the Spring Festival, the release of Sora marked the beginning of the competition among large models in 2024, with rapid advancements and breakthroughs in multimodal models throughout the year. However, before we begin, it’s important to clarify what is meant by multimodal models here. Current multimodal models are primarily divided into two categories: one is specialized multimodal models, such as text-to-image models and text-to-video models, which I prefer to call AIGC models; the other is general-purpose multimodal large language models, which have capabilities in natural language understanding and generation, image recognition, as well as voice and video interaction. However, as multimodal applications gradually enter ordinary users’ lives, some manufacturers exploit users’ lack of related background knowledge and claim to support multimodality. Therefore, multimodal applications can be categorized into three types based on implementation (definitions from Microsoft Research Asia’s “Crossing Modal Boundaries: Exploring Native Multimodal Large Language Models”[1]):
-
Multimodal Interfaces: Developing a unified user interface at the system level that supports various modal data inputs and outputs, but the implementation can be achieved by invoking different modal models or even APIs to achieve multimodal capabilities at the terminal. -
Multimodal Alignment and Fusion: Connecting language models, visual models, audio models, etc., at the technical framework level. These models learn independently, using different modal data for training, and then the combined model continues pre-training on cross-modal data and fine-tuning on different task data. -
Native Multimodal Large Language Models: From the training stage, the model uses a large amount of data from different modalities for pre-training, achieving tight coupling technically, allowing for multimodal input and output, as well as strong multimodal reasoning and cross-modal transfer capabilities. (For further understanding, refer to Why is GPT-4o Native Multimodal? Isn’t GPT-4V Native Multimodal?[2])
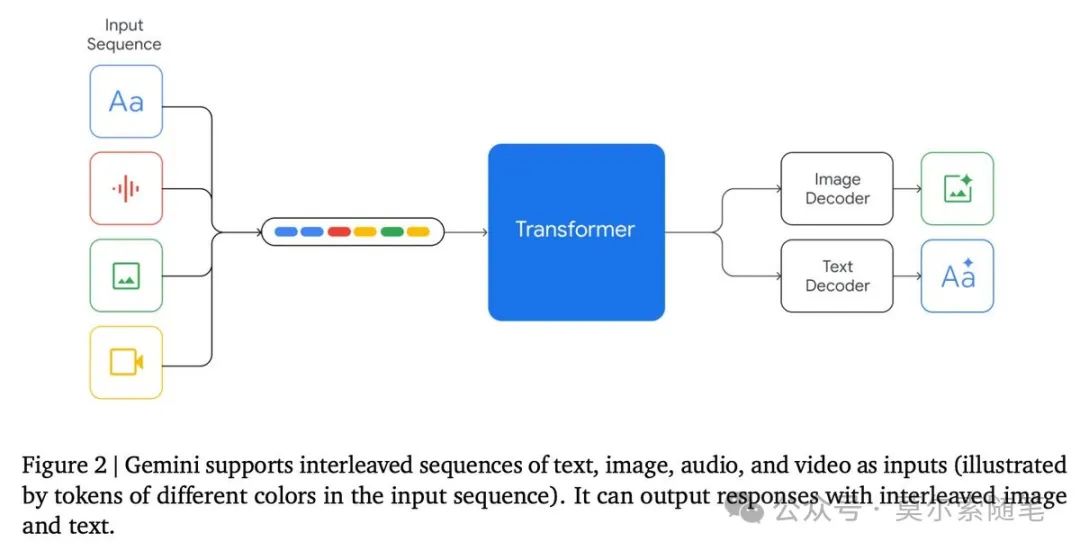
True native multimodal models are mainly OpenAI’s GPT-4o and Google’s Gemini, integrating all modalities into a single end-to-end model. GPT-4o supports any combination of text, audio, and image inputs and outputs, while the ChatGPT client allows for real-time video calls similar to using FaceTime. Gemini can understand and generate data across multiple modalities, and developers can achieve low-latency bidirectional voice and video interaction through the Multimodal Live API, combining various tools to handle dynamic tasks.
In terms of multimodal interfaces, Kimi from Moonlight is a typical representative, supporting the upload of images and various file types as well as voice interaction. Personally, I feel Kimi’s long text understanding capability still ranks among the top domestic models. Additionally, it has launched the k0-math model focused on mathematical reasoning, the k1 model based on reinforcement learning technology for visual thinking, and the Kimi Exploration version to enhance AI’s autonomous search capabilities. However, this company focuses on the C-end, and the API interface is quite limited in usability.
Since the release of Claude 2, models from Anthropic have been my primary choice for use (I will write a detailed article about this later)[3].
MiniMax’s Conch AI, Zhiyuan’s Zhiyuan Qingyan, and Step Star’s Yuewen also belong to the multimodal interface type, but some models adopt alignment and fusion solutions, such as image understanding through image-text alignment and fusion, and real-time speech through speech-text alignment and fusion. However, these companies provide rich API support.
| Modal Type | Step Star | Zhiyuan | MiniMax | ByteDance |
|---|---|---|---|---|
| Text Generation/Understanding | step-2 | GLM-4 | abab7-chat | Doubao-pro |
| Image Understanding | step-1v | GLM-4V | abab7-chat | Doubao-vision |
| Image Generation | step-1x-medium | CogView-3-Plus | – | Doubao-Text-to-Image Model |
| Video Understanding | step-1.5v-mini | GLM-4V-Plus | – | Doubao-vision |
| Video Generation | Step-Video | CogVideoX | video-01 | Doubao-Video Generation |
| Voice Cloning and Generation | step-tts-mini | – | speech-02 | Doubao-Voice Cloning/Speech Synthesis |
| Speech Recognition | step-asr | – | – | Doubao-Speech Recognition |
| Real-time Voice (End-to-End) | Step-1o | GLM-4-Voice | Realtime API | – |
Regarding the products from Zero One and Baichuan Intelligence, I will refrain from commenting as I have not used them. ByteDance’s Text-to-Image model performs excellently, especially strong in Chinese semantic understanding, but its price is relatively high (0.2 RMB per use). Tongyi Qianwen’s open-source base model is quite powerful, but the C-end product feels excessively stripped down and is basically unusable.
Open-source Models
The main forces in open-source models are Llama, Qwen, Mistral AI, and DeepSeek, focusing on enhancing the foundational capabilities of models. The Qwen series, including Qwen 1.5, Qwen 2, and Qwen 2.5, offers various model sizes and has made rapid progress in performance, multilingual capabilities, context length, and safety. Additionally, Qwen has launched models specifically targeting visual language, multimodal reasoning, and audio processing, such as Qwen2-VL, QVQ-72B-Preview, and Qwen2-Audio, further expanding the application range of the models. The Llama series, starting from Llama 3, continues to break through in parameter size, context length, and performance, particularly the Llama 3.1 405B version, which has become one of the largest open-source large language models. DeepSeek has released models including DeepSeek LLM, DeepSeek-Coder, DeepSeekMath, DeepSeek-VL, DeepSeek-V2, DeepSeek-Coder-V2, DeepSeek-VL2, and DeepSeek-V3, demonstrating outstanding capabilities in multilingual, code generation, and mathematical reasoning, achieving significant improvements in performance and efficiency while balancing cost and performance. Mistral AI has also open-sourced models like Mistral Large, Mistral Small, Pixtral Large, Mixtral 8x22B, Mistral NeMo, Codestral Mamba, and Mathstral, excelling in multimodal processing, programming tasks, and mathematical problems. (For details, you can read my blog Year-End Review of Open-source Large Models: Comprehensive Analysis of Llama, Qwen, Mistral AI, and DeepSeek[4])
The ecosystems of Qwen and Llama series are particularly prosperous, with multimodal exploration focusing on alignment and fusion solutions, which combine different individual models to enable multimodal capabilities. For instance, Qwen-VL is structured as Qwen-7B + Openclip ViT-bigG (2.54B), where the former serves as the foundational language model and the latter as the visual model, allowing Qwen-VL to support multimodal inputs of images and text.
AIGC Models
In the field of specialized multimodal models, Suno V3 is hailed as the