This article introduces four technologies in the ChatGPT model: prompt tuning, instruct tuning, in-context learning, and chain-of-thoughts. By applying these technologies, ChatGPT can interact more intelligently with humans, not only performing natural language understanding and generation but also optimizing and training for specific tasks, thereby achieving a more intelligent and personalized conversational experience.
Prompt tuning is a technique used to optimize dialogue generation by altering the beginning of the dialogue, allowing ChatGPT to generate more natural and fluent conversations.
A prompt is a form or template designed by researchers for downstream tasks, converting downstream prediction tasks into language model tasks. It helps the model “recall” what it learned during pre-training and transforms the language model’s predictions into predictions for the original downstream tasks.
In practical research, prompts should have placeholders for answers, usually positioned in the middle or at the end of sentences. If placed in the middle, such prompts are generally called cloze prompts; if at the end, they are referred to as prefix prompts.
Cloze prompt: the answer placeholder is in the middle of the sentence;
Prefix prompt: the answer placeholder is at the end of the sentence.
Translate English to French: /* task description */
sea otter => loutre de mer /* example */
cheese => ___ /* prompt */
Prompt Tuning vs Fine Tuning
Prompt tuning is inspired by GPT-3. The idea of Prompt Tuning is to insert a task-specific tunable prompt token into the prompt. Since this token varies for each task, it helps the machine identify what the task is. Moreover, as the machine learns (tunes) this prompt token itself, it results in very effective outcomes. Prompt tuning requires input-output to be within a template, inevitably necessitating a reformatting of the original task to achieve optimal performance.
The essence of prompt tuning is to change the task format to cater to the performance of large models. In other words, the premise of prompt tuning is that the pre-trained model’s performance is already very good; we only need to convert the task format during inference to achieve excellent performance, while fine-tuning involves changing the model to adapt to downstream tasks.
Instruct tuning is a self-supervised learning technique that trains and optimizes based on task-specific guidance information, achieving better results on specific tasks.
Introduction to Instruct Tuning
Instruction learning was proposed by the Google DeepMind team in a 2021 paper titled “Finetuned Language Models Are Zero-Shot Learners.” The titles of their papers are quite interesting; OpenAI’s 2020 paper on GPT-3 was called “Language Models are Few-Shot Learners.” Google discovered that large-scale language models like GPT-3 could learn few-shot very well, but were less successful in zero-shot scenarios. For example, GPT-3’s performance on tasks like reading comprehension, question answering, and natural language reasoning was quite average. Google believed a potential reason was that without a few examples, in zero-shot conditions, the model struggles to maintain consistency with the pre-training data format (mainly prompt formats).
If that’s the case, why not just use natural language instructions as input? Thus, this paper proposed a method based on instruction-tuning called FLAN (Finetuned LAnguage Net). For all NLP tasks, it clusters them based on task types and goals, randomly selecting all tasks within a cluster for evaluation, while using tasks from other clusters for instruction-tuning.
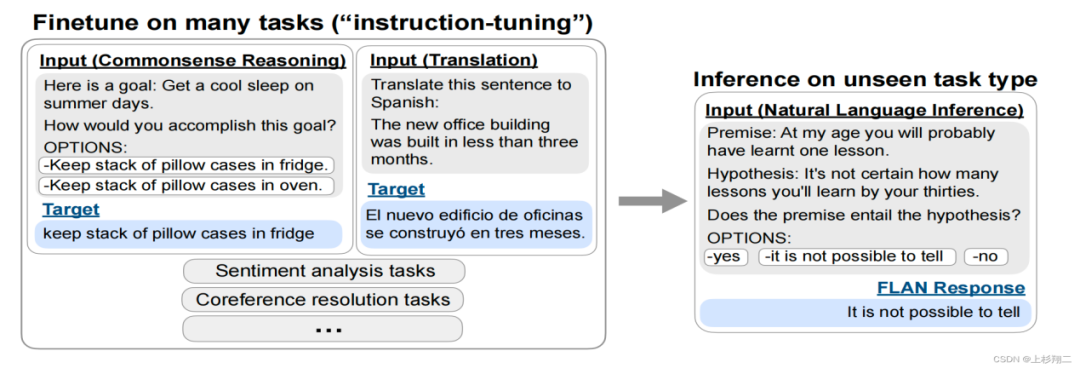
Figure 1 Example of Instruction Tuning
As shown in Figure 1, the model can first fine-tune on tasks like commonsense reasoning, machine translation, and sentiment analysis, which can all be transformed into instruct forms for learning with large models. In this way, when an unseen task arises, such as natural language inference, it can easily achieve zero-shot extension by understanding its natural language semantics.
Instruct Tuning vs Prompt Tuning
The similarities and differences between instruction learning and prompt learning: both aim to uncover the knowledge inherent in the language model. The difference is that a prompt stimulates the language model’s completion ability, such as generating the second half of a sentence based on the first half, or fill-in-the-blank tasks. Instruct, on the other hand, stimulates the language model’s understanding ability by providing clearer instructions for the model to take the correct actions.
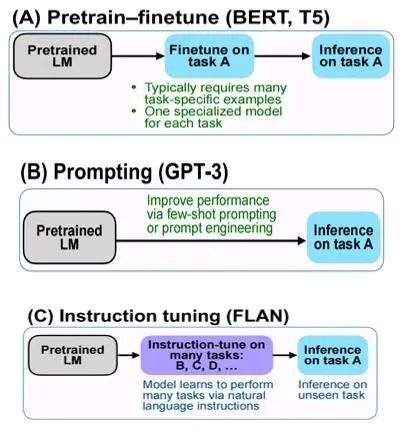
Figure 2 Comparison Example of Fine-tuning/Prompt-tuning/Instruction-tuning
Fine-tuning: first pre-train on large-scale corpora, then fine-tune on a specific downstream task, such as BERT, T5;
Prompt-tuning: first select a general large-scale pre-trained model, then generate a prompt template for a specific task to adapt the large model for fine-tuning, such as GPT-3;
Instruction-tuning: still based on pre-trained language models, first fine-tune on multiple known tasks (in natural language form), and then infer on a new task for zero-shot.
The advantage of instruction learning is that after multi-task fine-tuning, it can perform zero-shot on other tasks, while prompt learning is task-specific and has less generalization ability compared to instruction learning. Both InstructGPT and ChatGPT use instruction fine-tuning.
In-context learning is a technique that utilizes contextual information for dialogue generation, helping ChatGPT better understand the context and semantics of conversations. In-context learning, abbreviated as ICL, is also known as analogy learning or situational learning. It was initially proposed in GPT-3. It avoids modifying the large model itself by inducing GPT to generate better results through the addition of examples (sentence1, answer1).
A review by Peking University titled “A Survey for In-context Learning” suggests that the key idea of In Context Learning (ICL) is learning from analogy.
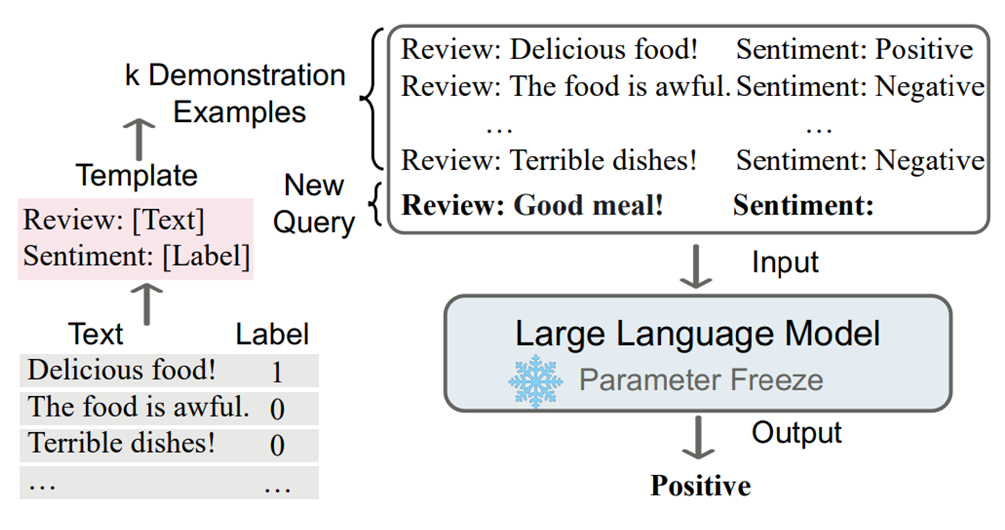
Figure 3 Example of Sentiment Analysis Using In-context Learning
Figure 3 shows how a language model uses ICL for sentiment analysis. First, ICL requires some examples to form a demonstration context. These examples are usually written in natural language templates. Then, ICL connects the query question (the input needing a predicted label) with a contextual demonstration (some relevant cases), forming a prompt input to be fed into the language model for prediction. Notably, unlike supervised learning during the training phase, which requires using backpropagation to update model parameters, ICL does not require parameter updates and directly predicts using the pre-trained language model (this is different from prompts and traditional demonstration learning; ICL does not need downstream prompt-tuning or fine-tuning). We hope the model learns the patterns hidden in the contextual demonstration and makes the correct predictions accordingly.
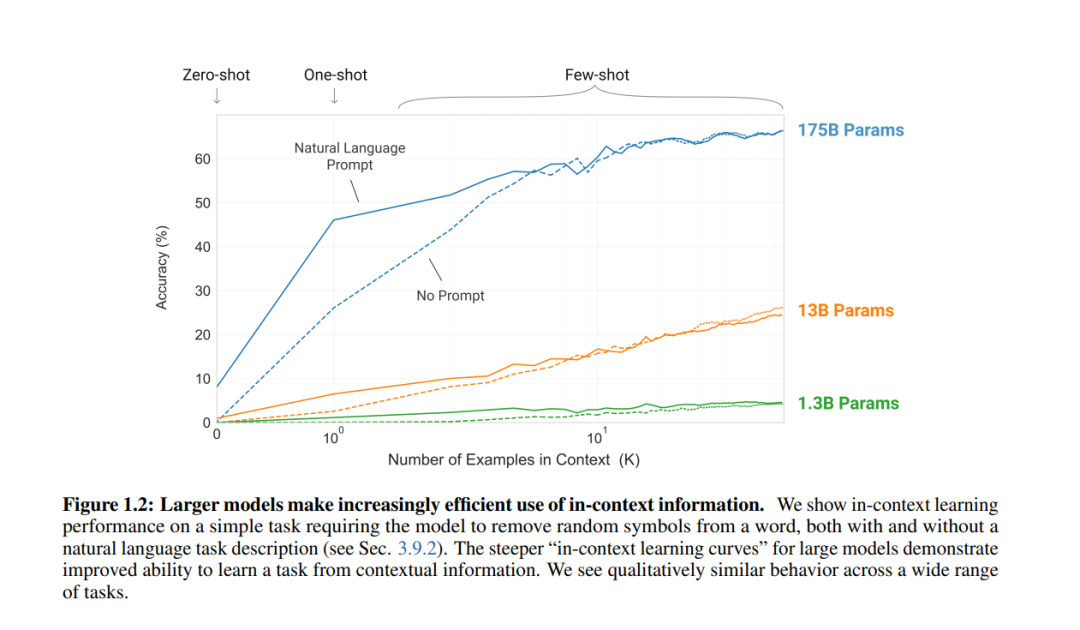
At that time, GPT-3 proposed the concept of In-Context Learning based on the existing zero-shot of GPT-2, with one-shot and few-shot schemes corresponding to different enhanced prompt construction methods. As the model’s parameter scale increases, the effects of few-shot and one-shot become more significant.
Figure 4 Effect Improvement Curve of Different In-Context Learning Schemes on Large Models
In ChatGPT, this method can also be used to communicate with it by providing a few examples for it to learn from and respond.
Chain-of-thoughts is a technique for automatically constructing a continuous dialogue flow by continuously generating new topics and ideas during the conversation, achieving smoother and more natural dialogue interactions.
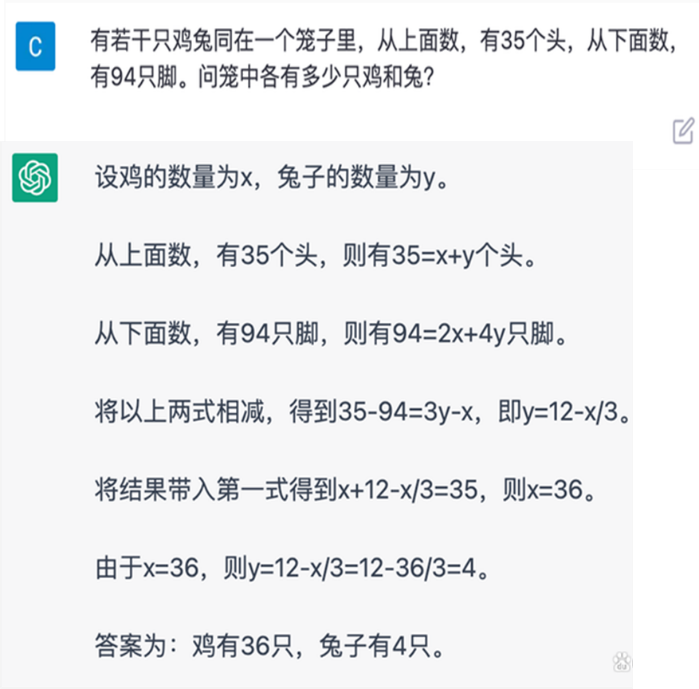
As mentioned earlier, both prompt learning and instruction learning perform well in large model language modeling, but they struggle with logical reasoning and numerical calculation tasks (referred to as second-order tasks, system-2 tasks). Even the largest models at the time found it difficult to handle certain reasoning tasks, such as mathematical word problems, symbolic operations, and commonsense reasoning. Even now, ChatGPT can discuss the history of modern physics for 20 minutes, but it makes mistakes starting from the fourth line when faced with basic elementary school math problems (as shown in Figure 5). So how can we enhance the reasoning capabilities of large models? This is where the concept of the chain of thought was proposed.
Figure 5 ChatGPT Makes Mistakes in Solving the Chicken and Rabbit Problem
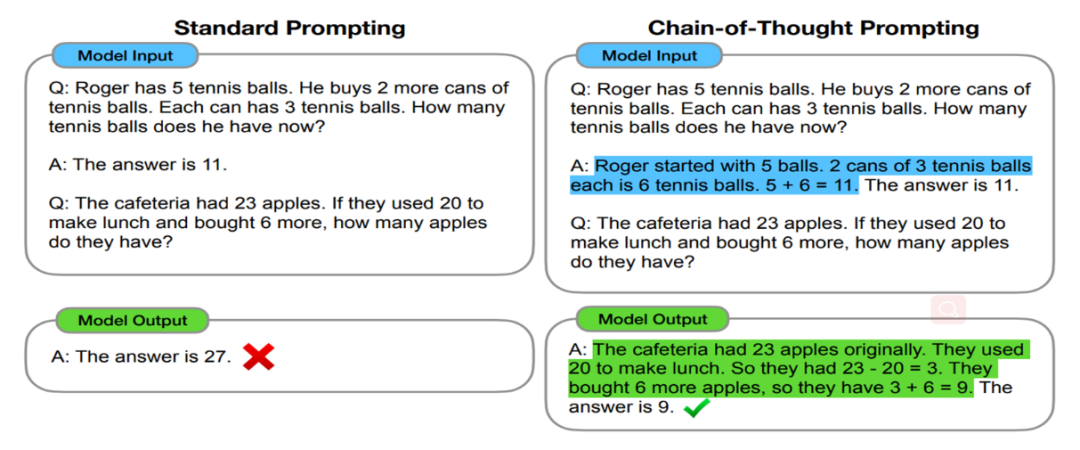
The pioneering work on the concept of the chain of thought is the paper “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models.” This paper was published by Jason Wei, a current researcher at Google Brain, on arXiv in January 2022. In simple terms, the chain of thought can be considered a discrete form of prompt learning. More specifically, in the traditional context learning mentioned earlier, the chain of thought includes some intermediate reasoning processes (as shown in Figure 6).
Figure 6 Comparison Example of Chain of Thought Method
So how effective is this? This paper conducted experiments on datasets for arithmetic reasoning, commonsense reasoning, and symbolic reasoning.
Dataset (Arithmetic Reasoning): GSM8K, SVAMP, ASDiv, AQuA, MAWPS
Dataset (Commonsense Reasoning): CSQA, StrategyQA, Date, Sports, SayCan
Baseline: standard prompting
LLM: based on 5 LLMs (GPT-3, LaMDA, PaLM, UL2 20B, Codex)
Experimental Conclusions:
(1) Chain-of-thought is helpful for large-scale models, but small-scale models produce fluent yet illogical reasoning chains, resulting in poorer performance than standard prompting;
(2) The more complex the problem, the better the improvement from chain-of-thought;
(3) Some dataset results are state-of-the-art;
(4) Randomly sampled final answers that were correct were manually checked, and the reasoning chains were almost all correct; for samples with incorrect final answers, most reasoning chains had only minor detail errors.
This section tested three variations of the chain of thought to examine the reasons for its success.
(1) Equation only: the prompt contains only mathematical formulas, without natural language. It performs poorly on complex problems but well on simple problems (with only one or two steps), indicating the necessity of natural language expression.
(2) Variable only: the prompt contains only a dot sequence (…), equal to the number of characters needed for calculating the final answer. Its performance is the same as the baseline (standard prompting), again indicating the necessity of natural language expression.
(3) Reasoning after answer: placing the reasoning process after the answer to test whether the reasoning chain helps the model extract relevant information during pre-training to arrive at the final answer. Its performance is the same as the baseline (standard prompting), indicating that the order of the reasoning chain and the answer is crucial, with the answer derived from the reasoning chain.
First, we focus on the GPT-3.5 series, which is the foundation of ChatGPT.Code-davinci-002 and text-davinci-002 are the first versions of the GPT-3.5 model, one for code and the other for text.They exhibit four important capabilities that differ from the original GPT-3:
1. Responding to human instructions: Previously, GPT-3’s outputs were mainly common sentences from the training set. The current model generates more reasonable answers based on instructions/prompts (rather than relevant but useless sentences).
2. Generalizing to unseen tasks: When the number of instructions used to adjust the model exceeds a certain scale, the model can automatically generate effective responses to new instructions it has never seen before. This ability is crucial for deployment, as users will always ask new questions, and the model must be able to respond.
3. Code generation and understanding: This ability is evident, as the model has been trained on code.
4. Utilizing chain-of-thought for complex reasoning: The original GPT-3 model had weak or no reasoning capability through chain-of-thought. Code-davinci-002 and text-davinci-002 are two models with sufficiently strong chain-of-thought reasoning capabilities.
In terms of training methods, ChatGPT and InstructGPT are almost identical; the difference is that InstructGPT is based on GPT-3, while ChatGPT is based on GPT-3.5, and their training data also differs slightly.
In summary: The original GPT-3 model gained generative ability and in-context learning through pre-training; then the instruction-tuning model branch acquired the ability to follow instructions and generalize to unseen tasks; the code-trained branch model gained code understanding ability; and through the chain of thought, the model gained complex reasoning ability; sacrificing the ability to learn from context to gain the ability to model dialogue history.
Combining these capabilities, code-davinci-002 seems to be the most powerful GPT-3.5 model with all strong abilities. Next, through supervised instruction tuning and RLHF, it sacrifices some model capabilities to align with humans. RLHF enables the model to generate more detailed and fair answers while refusing questions beyond its knowledge range, allowing ChatGPT to gain a good reputation for its user experience.
[1] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.
[2] Qngxiu D, Lei L, Damai D, et al. A Survey for In-context Learning[J]. arXiv preprint arXiv:2301.00234, 2023.
[3] Or Honovich, Thomas Scialom, Omer Levy, Timo Schick. Unnatural Instructions: Tuning Language Models with (Almost) No Human Labor[J]. arXiv preprint arXiv:2212.09689, 2022.
[4] Brown T B, Mann B, Ryder N, et al. Language Models are Few-Shot Learners[J]. arXiv preprint arXiv:2005.14165, 2021.
[5] Jason W, Maarten B, Vincent Y, et al. Finetuned Language Models Are Zero-Shot Learners[J]. arXiv preprint arXiv:2109.01652, 2021.
[6] How OpenAI “Devilishly Trained” GPT? – Interpretation of InstructGPT Paper https://cloud.tencent.com/developer/news/979148
[7] In-Context Learning Related Sharing https://zhuanlan.zhihu.com/p/603650082
[8] Instruction-Tuning Paper List: https://github.com/SinclairCoder/Instruction-Tuning-Papers
[9] Chain-of-Thought Paper List: https://github.com/Timothyxxx/Chain-of-ThoughtsPapers
[10] Overview of Prompt Column https://zhuanlan.zhihu.com/p/464825153
China Confidentiality Association
Science and Technology Branch
Long press to scan the code to follow us
Author: Zhang Wanyue, University of Chinese Academy of Sciences
Editor: Gao Qi
Cross-network attacks: Overview of breakthrough physical isolation network attack techniques
Thoughts on the top-level design of smart city security
Revisiting some new issues facing the development of digital forensics technology
Development and challenges of low-orbit satellite interconnect networks
Overview of LaserShark non-contact attack implantation technology
ChatGPT Special (I) Evolution of the GPT Family
Overview of searchable encryption technology
Security analysis of electric vehicle charging station management systems
Summary of common cybersecurity threats and their protection technologies
Analysis of security algorithm and protocol verification issues