This article is extracted from the “Engineering” journal of the Chinese Academy of Engineering, 2019, Issue 2.
Authors: Liu Shengfeng, Wang Yi, Yang Xin, Lei Baiying, Liu Li, Li Xiang, Ni Dong, Wang Tianfu
Source: Deep Learning in Medical Ultrasound Analysis: A Review[J]. Engineering, 2019, 5(2): 261-275.
Editor’s Note
As one of the most commonly used imaging modalities, ultrasound has become an indispensable tool for scanning and diagnosis in clinical practice. Ultrasound is a rapidly developing technology with advantages such as painless, non-ionizing radiation, economical, practical, and real-time imaging; however, it also has unique disadvantages such as poor image quality and significant variability. For image analysis, it is necessary to develop advanced automated ultrasound image analysis methods to assist doctors in ultrasound diagnosis, which can alleviate the burden on doctors and reduce the subjectivity of diagnosis, thereby making diagnoses more objective and accurate.
The article published in the “Engineering” journal of the Chinese Academy of Engineering aims to comprehensively and systematically summarize the applications of deep learning in medical ultrasound image analysis, focusing mainly on typical tasks and their applications in different anatomical structures. The article points out that deep learning demonstrates enormous application potential in medical ultrasound image analysis, briefly introduces some popular deep learning architectures, and discusses the applications of deep learning methods in various specific tasks of ultrasound image analysis (such as image classification, object detection, and target segmentation). The article also outlines the challenges faced by deep learning in medical ultrasound image analysis applications and potential development trends.
1.
Introduction
As one of the most commonly used imaging modalities, ultrasound (US) has become an indispensable tool for scanning and diagnosis in clinical practice. Due to its relative safety, lower cost, non-invasive nature, real-time imaging, and comfortable operation, ultrasound imaging is especially widely used in prenatal screening worldwide. Decades of clinical practice have confirmed that compared to other medical imaging modalities such as X-ray, magnetic resonance imaging (MRI), and computed tomography (CT), ultrasound imaging has some obvious advantages, such as no ionizing radiation, portability, ease of access, and cost-effectiveness. In current clinical practice, medical ultrasound has been applied in various specialties, such as electrocardiograms, breast ultrasound, abdominal ultrasound, transrectal ultrasound, cardiovascular ultrasound, and prenatal diagnostic ultrasound, especially widely used in obstetrics and gynecology (OB-GYN).
However, ultrasound also presents unique challenges, such as low image quality caused by noise and artifacts, high dependence on the experience of the operator or diagnostic physician, and significant variability between institutions and manufacturers’ ultrasound systems, either within the same observer or between different observers. For instance, a study using ultrasound images for prenatal anomaly detection indicated that the sensitivity range between different medical institutions was 27.5% to 96%. To address these challenges, developing advanced automated ultrasound image analysis methods can make ultrasound diagnosis and/or evaluation, as well as image-guided interventions and/or treatments, more objective, accurate, and intelligent.
Deep learning is a branch of machine learning and a representation learning method that can directly process raw data (such as ultrasound images) and automatically learn mid-level and high-level abstract features from it. It has the potential for automatic analysis of various ultrasound image tasks, such as lesion/nodule classification, tissue segmentation, and object detection. Since AlexNet—a deep convolutional neural network (CNN) and a representative of deep learning methods—won the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC), deep learning has begun to attract attention in the machine learning field. A year later, deep learning was selected as one of the top ten breakthrough technologies, further solidifying its position as the primary machine learning tool in various research fields, especially in general image analysis (including natural images and medical images) and computer vision (CV) tasks. To date, deep learning has rapidly developed in terms of network structures or models, such as deeper network structures and deep generative models. At the same time, deep learning has also been successfully applied in various research fields such as CV, natural language processing (NLP), speech recognition, and medical image analysis, indicating that deep learning can achieve significant performance improvements in various automatic analysis tasks and achieve optimal performance.
Currently, deep learning has been applied to various tasks in medical image analysis, including traditional diagnostic tasks such as classification, segmentation, detection, registration, biological measurement, and quality control/evaluation, as well as emerging tasks such as image-guided interventions and treatments (Figure 1). Among these tasks, classification, detection, and segmentation are the three most basic tasks. They are widely applied in the analysis of medical ultrasound images of different anatomical structures (organs or body parts), such as breast, prostate, liver, heart, brain, carotid artery, thyroid, cardiovascular, fetus, lymph nodes, kidneys, spine, bones, skin, neural structures, tongue, etc. Various deep networks are applied to these tasks. CNN is one of the most popular deep structures that has achieved great success in various tasks, such as image classification, object detection, and target segmentation. The most commonly used method is to use a CNN model to automatically learn from the collected raw data (such as ultrasound images), generating hierarchical abstract representations, and then producing one or more probability maps or class labels through a softmax layer or other linear classifiers [such as support vector machines (SVM)]. In this case, image labeling or tagging is essential. This is known as “supervised learning.” Unsupervised learning can also learn representations from raw data. Autoencoders (AE) and restricted Boltzmann machines (RBM) are the most commonly used unsupervised neural networks in medical ultrasound image analysis, achieving good performance improvements. Compared to supervised learning, unsupervised learning has a significant advantage as it does not require time-consuming, tedious, and expensive manual labeling.
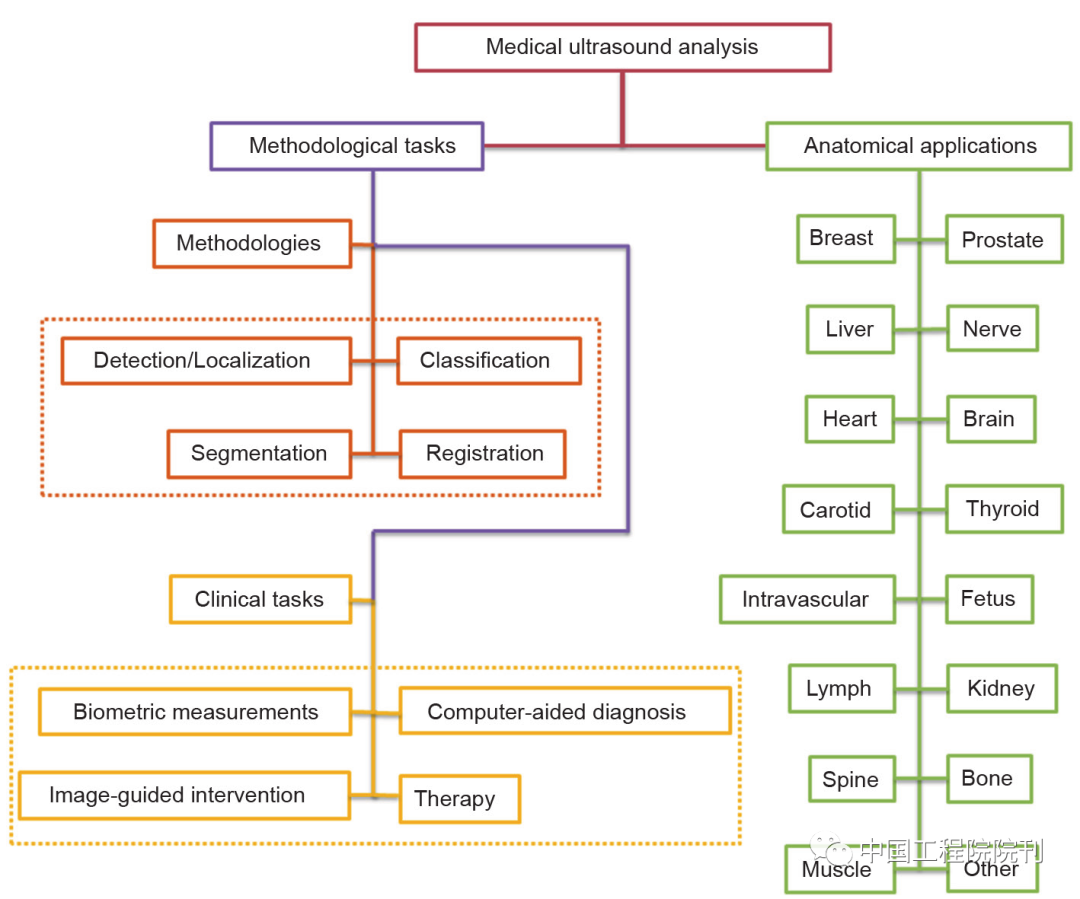
Figure 1 Applications of deep learning in medical ultrasound image analysis
Although current medical ultrasound image analysis mainly focuses on two-dimensional (2D) ultrasound image processing, the application of deep learning in three-dimensional (3D) medical ultrasound image analysis is also showing a growing trend. Over the past 20 years, commercial companies and researchers have greatly promoted the development of 3D ultrasound imaging technology. A 3D image (often referred to as a “3D volume”) typically contains richer information than a 2D image, thus using 3D volumes can yield more robust results.
More specifically, 2D ultrasound images have some unavoidable limitations:
1. Although ultrasound images are 2D, anatomical structures are 3D, so the detector or diagnostic physician must have the ability to integrate multiple images in their mind (this process can often be ineffective and time-consuming); the lack of this ability can lead to significant discrepancies or even misdiagnosis.
2. Diagnostic (such as obstetrics) and treatment (such as staging and planning) decisions often require accurate estimation of the volume of organs or tumors; however, 2D ultrasound measures volume by assuming the measurement target to be an ideal shape (such as an ellipsoid) based on simple measurements of length, width, height, etc. This can lead to low accuracy, significant variability, and dependence on the experience of the operator.
3. A 2D ultrasound image presents a plane at any angle in the body, making it difficult to re-localize and reproduce these planes for follow-up studies.
To overcome the limitations of 2D ultrasound, various 3D ultrasound scanning, reconstruction, and display technologies have been developed, providing a solid foundation for 3D ultrasound image analysis. In addition, the development of 3D ultrasound imaging technology has also supported the current application of deep learning in medical ultrasound image analysis.
So far, there have been some reviews regarding the application of deep learning in medical image analysis, either covering the entire medical image analysis field or focusing only on a single imaging modality, such as magnetic resonance imaging (MRI) and microscopic imaging. However, very few documents summarize the application of deep learning in medical ultrasound image analysis, except for a few that involve specific tasks, such as breast ultrasound image segmentation.
By specifying keywords (such as “ultrasound” or “ultrasound examination” or “ultrasound imaging” and “convolution” or “deep learning”), all relevant literature in this field before February 1, 2018, was retrieved from major databases (such as PubMed and Google Scholar) and some important conferences (such as MICCAI, SPIE, ISBI, and EMBC).
To screen all retrieved literature, each abstract was meticulously reviewed, retaining relevant literature, resulting in nearly 100 articles, summarized in Table 2 and Appendix A’s Table S1. This article aims to comprehensively and systematically summarize the applications of deep learning in medical ultrasound image analysis, focusing mainly on typical tasks and their applications in different anatomical structures. The remainder of this article is arranged as follows: Section 2 briefly introduces the basic theories and structures of commonly used deep learning methods in medical ultrasound image analysis; Section 3 discusses in detail the applications of deep learning in medical ultrasound image analysis, mainly focusing on traditional tasks including classification, detection, and segmentation; finally, Section 4 points out the future trends and development directions of deep learning applications in medical ultrasound image analysis.
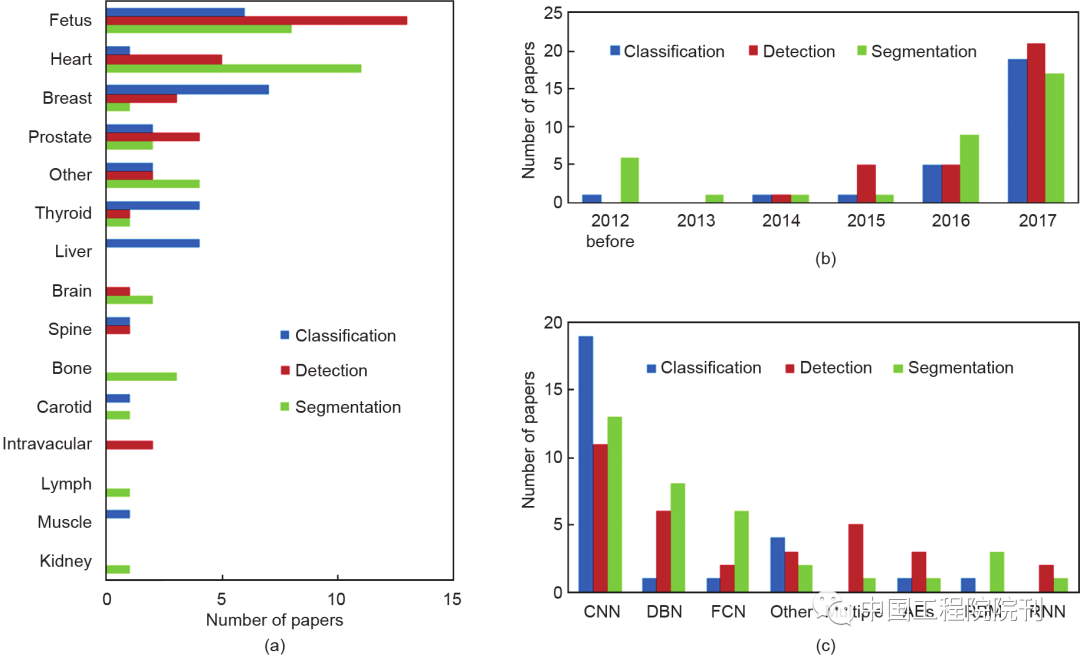
Figure 2 Statistics on the applications of deep learning in medical ultrasound image analysis. (a) Anatomical structure; (b) Year of publication; (c) Network structure. DBN: Deep Belief Network; FCN: Fully Convolutional Network; Multiple: Combination of various network structures; RNN: Recurrent Neural Network; AE: Autoencoder including its variants: Sparse Autoencoder (SAE) and Stacked Denoising Autoencoder; RBM: Restricted Boltzmann Machine
2.
Common Deep Learning Structures
This section mainly introduces the deep learning structures commonly used in medical ultrasound image analysis. As a branch of machine learning, deep learning essentially forms hierarchical features or representations of sample data, where high-level abstract features are defined by combining them with low-level features.
Based on the discussed deep learning structures and techniques (such as classification, segmentation, or detection), the most commonly used deep learning structures in this field can be divided into three categories: 1) Supervised deep networks or deep discriminative models; 2) Unsupervised deep networks or deep generative models; and 3) Hybrid deep networks. The most basic models or structures currently used in medical ultrasound image analysis applications are CNN, Recurrent Neural Networks (RNN), RBM/Deep Belief Networks (DBN), AE, and variants of these deep learning structures, as shown in Figure 3. The “Multiple” in the third category refers to either a combination of generative and discriminative model components or fully utilizing the models they generate; therefore, this category will not be specifically discussed further. Instead, this section will continue to introduce the challenges encountered in training deep models commonly found in medical ultrasound image analysis and their coping strategies. For convenience, some commonly used deep learning frameworks are also summarized.
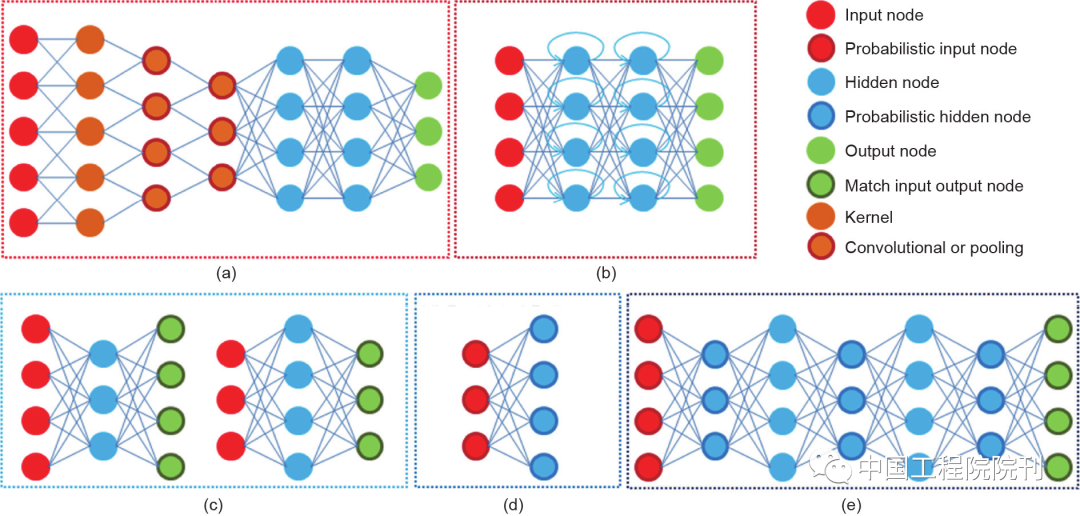
Figure 3 Five typical neural network structures, mainly divided into two categories: (1) Supervised deep learning models, including (a) CNN and (b) RNN; (2) Unsupervised deep learning models, including (c) AE/SAE, (d) RBM, and (e) DBM
(1) Supervised Deep Learning Models
Currently, supervised deep learning models are widely used in medical image analysis for the classification, segmentation, and detection of anatomical structures. In these tasks, CNN and RNN are the two most commonly used structures. Below is a brief introduction to these two deep models.
1. Convolutional Neural Networks
CNN is a discriminative deep structure that includes several modules, each typically consisting of a convolutional layer and a pooling layer. If necessary, there may be additional layers, such as Rectified Linear Units (ReLU) and Batch Normalization (BN). The last part of the network is typically a fully connected layer, forming a standard multi-layer neural network. Structurally, these modules are usually stacked in blocks to form a deep model, which can fully utilize the spatial and configuration information of the input 2D or 3D images.
By performing convolution operations on the input images, the convolutional layer shares all weights. In fact, the role of the convolutional layer is to detect local features at different positions in the input image/feature map (such as medical ultrasound images), obtaining a set of k kernel weights W={W1, W2, …, Wk} and biases b={b1, b2, …, bk}, thus producing a new feature map 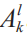 . Mathematically, the convolution process of each convolutional layer can be expressed as:
. Mathematically, the convolution process of each convolutional layer can be expressed as:
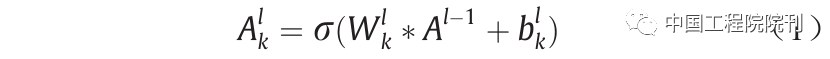
where σ(·) is a nonlinear activation function; 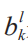 is the bias parameter; * denotes the convolution operation.
is the bias parameter; * denotes the convolution operation.
In a typical CNN model, determining the hyperparameters in the convolutional layer is crucial to overcoming the reduction caused by the convolution process. This mainly involves three hyperparameters: depth, stride, and padding. The depth of the output volume corresponds to the number of filters, each learning to find local differences in the input. Specifying the stride controls how the filter convolves over the input volume. In practice, smaller strides always work better because small strides in some of the earlier layers of the network (i.e., those closer to the input data) can generate larger activation maps, leading to better performance. In a CNN with many convolutional layers, the reduction in output dimensions may become problematic because each convolution operation loses some area, especially at the boundaries. Padding (usually zero padding) around the boundaries of the input volume is a common strategy to eliminate the effects of dimensionality reduction during the convolution process. One of the main benefits of padding is that it makes it possible to design deeper networks. Additionally, padding prevents the loss of boundary information in the input volume, thus effectively improving the overall performance of the model. Therefore, under limited computational and time costs, it is necessary to balance multiple factors (i.e., the number of filters, filter size, stride, network depth, etc.) for specific tasks in practice.
The output of the convolutional layer is resampled by the subsequent pooling layer to reduce the data rate for the layers below. Along with appropriately selected pooling schemes, the shared weights in the convolutional layer give CNN certain invariances, such as translational invariance. This also significantly reduces the number of parameters, as the number of weights no longer completely depends on the size of the input image. It is worth noting that fully connected layers are generally placed behind the convolutional stream in the network, usually without shared weights. In a standard CNN model, activations are produced through the softmax function at the last layer of the network to obtain a distribution over class labels. However, some traditional machine learning methods, such as voting strategies or linear SVM, are sometimes also used.
With increasing popularity and practicality, many classic and CNN-based deep learning structures have been developed and applied in (medical) image analysis, natural language processing, and speech recognition, such as AlexNet (or CaffeNet suitable for the Caffe deep learning framework), LeNet, faster R-CNN, GoogLeNet, ResNet, and VGGNet.
2. Recurrent Neural Networks
In practice, RNN is generally applied as a supervised deep learning network for various tasks in medical ultrasound image analysis. In RNN, the depth of the network can be as long as the length of the input sample data sequence (such as a medical ultrasound video sequence). A typical RNN contains a hidden state ht, which is the output at time t obtained from a nonlinear mapping of the network input xt and the previous state ht–1, which can be expressed as:
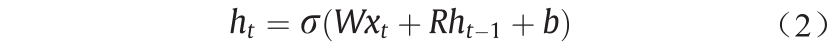
where weights W and R are shared over time; b is the bias parameter.
Due to structural characteristics, RNN has inherent advantages in modeling sequential data (such as medical ultrasound video sequences). However, so far, RNN has not been widely applied in various research tasks involving sequence modeling. Part of the reason is that it is difficult to train RNNs to capture long-term dependencies, which often leads to gradient explosion or vanishing, a problem identified as early as the 1990s. Therefore, some special memory units have been developed, the earliest and most commonly used being Long Short-Term Memory (LSTM) cells and their simplified gated recurrent units. To date, RNNs are mainly applied in the fields of speech or text recognition, with less application in medical image analysis and even less in medical ultrasound image analysis.
RNN can also serve as an unsupervised deep model. In unsupervised models, RNN typically uses previous data samples to predict subsequent data sequences. It does not require additional classification information (such as target category labels) to assist learning, whereas in supervised learning models, category sequence labels are fundamental.
(2) Unsupervised Deep Learning Models
Unsupervised learning means that task-specific supervisory information (such as labeled category labels) is not required during the learning process. In practical applications, various unsupervised deep learning models are utilized to generate data samples through network sampling, such as AE, RBM/DBN, and generalized denoising AE. From this perspective, unsupervised deep models are usually applied as generative models in various tasks. Below, I will briefly introduce the three most commonly used basic unsupervised deep learning models in medical ultrasound image analysis.
1. Autoencoders (AE) and Their Variants
Simply put, AE is a nonlinear feature extraction method that does not involve target category labels. This method is often used for representation learning or effectively encoding the original input data (such as in the form of input vectors) in hidden layers. Therefore, the extracted features focus on preserving and better representing information rather than performing specific tasks (such as classification), although these two goals are not always mutually exclusive.
AE is typically a simple network that contains at least three layers: an input layer x, representing the original data or input feature vector (such as blocks/pixels in an image or spectra in speech); one or more hidden layers h, representing transformed features; and an output layer y, which activates the hidden layer through a nonlinear function to match the input layer x for reconstruction:
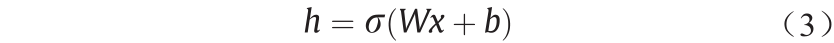
So far, many variants of AE have been developed, such as Sparse Autoencoders (SAE) and Denoising Autoencoders (DAE) and their stacked versions. In the SAE model, regularization and sparsity constraints are employed to enhance the solving process in network training, while “denoising” is a solution to prevent the network from learning ineffective solutions. These stacked versions are typically generated by placing AE layers on top of each other.
2. Restricted Boltzmann Machines and Deep Belief Networks
RBM is a special type of Markov random field with a two-layer structure. Structurally, it is a type of single-layer undirected graphical model that contains a visible layer and a hidden layer, which are symmetrically connected, while there are no connections between units in the same layer. Therefore, RBM is essentially an AE. In practical applications, RBM is rarely used alone; it is usually stacked one by one to generate deeper networks, which become the common single probability model called DBM.
A DBM consists of a visible layer and several hidden layers, with the top two layers forming an undirected bipartite graph (like RBM), while the lower layers form a directed sigmoid belief network with top-down connections. Since unlabeled data can be used for layer-wise pre-training (typically using a small amount of labeled data in practice), DBM has good generalization capabilities. Because DBM is trained in an unsupervised manner, it is necessary to fine-tune for a specific task in practice, and a common option for achieving supervised optimization is to add a linear classifier (such as SVM) at the last layer of the network. For unsupervised learning models, a fine-tuning step often accompanies the final representation learning, which is also a common practice for solving specific tasks (such as image classification, object detection, or tissue segmentation).
(3) Challenges in Model Training and Coping Strategies
The tremendous success of deep learning stems from its need for large labeled training samples to achieve excellent learning performance. However, in current medical ultrasound image analysis, this requirement is difficult to meet, as expert labeling is expensive, and data for some diseases (such as lesions or nodules) is scarce. Therefore, how to train deep models using limited training samples has become an open challenge in medical ultrasound image analysis. A common issue when using limited training samples is the risk of model overfitting.
To address the issue of model overfitting, there are two main approaches: model optimization and transfer learning. For model optimization, many productive strategies have been proposed in recent years, such as well-designed initialization strategies, stochastic gradient descent and its variants (such as momentum and Adagrad), effective activation functions, and other powerful intermediate regularization strategies (such as batch normalization), specifically as follows:
(1) Well-designed initialization/momentum strategies, including the use of reasonably random initialization and a special scheme to slowly increase the momentum parameter during the iterative training process of the model.
(2) Effective activation functions, such as ReLU, usually perform nonlinear operations after convolutional layers. Additionally, Maxout is also an activation function, especially suitable for training without dropout.
(3) Dropout randomly deactivates units/neural nodes in the network at a certain rate (such as 0.5) during each training iteration.
(4) Batch normalization standardizes each mini-batch of data during training and backpropagates gradients through standardization parameters during each training iteration.
(5) Stacking/denoising, mainly used for AE, to make the model deeper and reconstruct the original “clean” data from corrupted inputs.
Another key solution is transfer learning, which has also been widely adopted and has shown excellent performance improvement capabilities without requiring large sample training data. This method avoids the expensive data labeling work in specific application fields. According to the research by Pan et al., transfer learning can be divided into three main categories: inductive transfer learning, where the target and source tasks are different regardless of whether the target and source domains are the same; transductive transfer learning, where the target task is the same as the source task, while the target and source domains are different; and unsupervised transfer learning, which is similar to inductive transfer learning but with different target tasks and source tasks that are related to the source task. Based on the transfer content, the methods adopted for the aforementioned three types of transfer learning configurations can be divided into four cases: instance-based, representation-based, parameter transfer-based, and relational knowledge-based. However, this article is most concerned with how to transfer knowledge from other fields (where large sample training data can be easily collected, such as CV, speech, and text) to the medical ultrasound field to improve performance. This process involves two main strategies: 1) using pre-trained networks as feature extractors (i.e., learning features from scratch); and 2) fine-tuning pre-trained networks on medical ultrasound images or video sequences, a method widely applied in current medical ultrasound image analysis. In some specific tasks, both strategies have achieved good performance.
Some other strategies also require attention, such as data preprocessing and data augmentation.
(4) Common Deep Learning Frameworks
With the rapid development of related hardware (such as GPUs) and software (such as open-source software libraries), deep learning technology has become popular in various research tasks worldwide. The following are the five most popular open-source deep learning frameworks (or software libraries):
(1) Caffe: https://github.com/BVLC/caffe;
(2) Tensorflow: https://github.com/tensorflow/tensorflow;
(3) Theano: https://github.com/Theano/Theano;
(4) Torch7/PyTorch: https://github.com/torch/torch7 or https://github.com/pytorch/pytorch;
(5) MXNet: https://github.com/apache/incubatormxnet.
Most frameworks provide multiple interfaces, such as C/C++, Matlab, and Python. In addition, some packages also provide higher-level libraries written based on these frameworks, such as Keras. For the pros and cons of these open-source frameworks, please refer to the literature. In practical applications, researchers can choose any framework according to their actual needs and personal preferences or use their own written frameworks.
3.
Applications of Deep Learning in Medical Ultrasound Image Analysis
As mentioned earlier, the current applications of deep learning technology in medical ultrasound image analysis mainly involve three major tasks: classification, detection, and segmentation of various anatomical structures (such as breast, prostate, liver, heart, and fetus). This section will discuss each task’s applications in different anatomical structures. Moreover, in clinical practice, 3D ultrasound offers a promising direction for improving ultrasound imaging diagnosis, which will be discussed as a separate section.
(1) Classification
Image classification is a fundamental cognitive task in diagnostic radiology, achieved by identifying certain anatomical or pathological features that can distinguish a particular anatomical structure or tissue from others. Although current computers are far from replicating the entire reasoning chain required for interpreting medical images, the automatic classification of targets of interest (such as tumors/lesions, nodules, fetuses) is a hot research topic in computer-aided diagnosis systems. Traditional machine learning methods often utilize various handcrafted features extracted from ultrasound images, combined with multiple linear classifiers (such as SVM) to achieve specific classification tasks. However, these methods are susceptible to image distortion due to deformations caused by internal or external environments or imaging process conditions. Due to its ability to learn mid-level or high-level abstract features directly from raw data (or images), deep neural networks (DNN) have some significant advantages. Furthermore, DNN can directly output an individual prediction label for each image, thereby achieving classification of targets of interest. There are some unique challenges in different anatomical application areas, which will be discussed separately below.
1. Tumors or Lesions
According to the latest statistics from the Centers for Disease Control and Prevention, breast cancer has become the most common cancer among women worldwide and the second leading cause of cancer death. Although mammography remains the primary imaging modality for screening or diagnosing in clinical practice, ultrasound has also become an important screening tool for breast cancer diagnosis. In particular, the application of ultrasound-based computer-aided diagnosis (CADx) systems in tumor disease classification provides effective decision support and a second tool choice for radiologists or diagnosticians. In traditional CADx systems, feature extraction forms the basis for subsequent steps, including feature selection and classification, which are integrated to achieve the final classification of tumors or nodules. Traditional machine learning methods in breast or nodule CADx systems often rely on handcrafted and heuristic features extracted from lesions. In contrast, deep learning can automatically learn features directly from images.
As early as 2012, Jamieson et al. conducted an initial study on the use of deep learning for the classification task of breast tumors or nodules. As shown in Figure 4(a), the Adaptive Deconvolutional Network (ADN) is an unsupervised and generative hierarchical deep model used for learning image features and generating feature maps from diagnostic ultrasound images of breast tumors or nodules, followed by post-processing steps including establishing image descriptors and spatial pyramid matching (SPM) algorithms.
Because the model was trained in an unsupervised manner, the learned high-level features (such as SPM kernel outputs) were used as inputs to train supervised classifiers (such as linear SVM), achieving binary classification between malignant and benign breast nodules. Experimental results indicated that its performance had reached the level of traditional CADx systems that employed manually designed features. Following this success, many similar studies have applied deep learning methods to breast tumor diagnosis. Liu et al. and Shi et al. both used a supervised deep learning algorithm called Deep Polynomial Network (DPN), or its stacked version, Stacked Deep Polynomial Network (S-DPN), on two small ultrasound datasets. With the help of preprocessing based on shear wave transformation for texture feature extraction and region of interest (ROI) extraction and SVM classifiers (or multiple kernel learning), they achieved a maximum classification accuracy of 92.4%, outperforming unsupervised deep learning algorithms (such as Stacked AE and DVM). When using deep learning to learn image representations from block-level ultrasound images, this method is a good choice when local blocks cannot provide rich contextual information. Additionally, Stacked Denoising Autoencoders (SDAE), Point-Gated Boltzmann Machines (PGBM), and combinations of Restricted Boltzmann Machines (RBM), as well as GoogLeNet CNN, have also been applied to breast ultrasound or shear wave elastography to assist in breast cancer diagnosis, achieving better performance than human experts. In the study by Antropova et al., a method that fused mid-level features extracted from pre-trained CNNs with handcrafted features obtained from traditional CADx systems was applied to three clinical imaging modality datasets, confirming significant performance improvements.
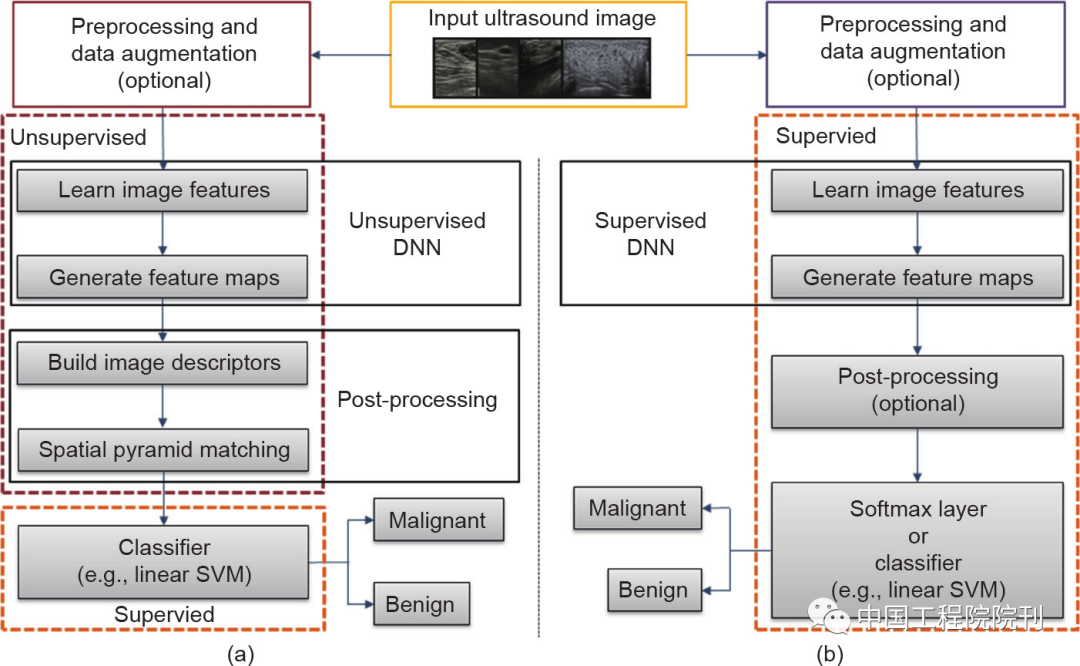
Figure 4 Flowchart for tumor ultrasound image classification: (a) Unsupervised deep learning and (b) Supervised deep learning. Before inputting ultrasound images into deep neural networks, preprocessing and data augmentation (such as extracting ROIs, image cropping, etc.) are typically performed. Although post-processing can also be used in supervised deep learning, it is rarely done; instead, the feature maps are directly input into the softmax classifier for classification.
Another common tumor is liver cancer, which has become the sixth most common cancer and the third leading cause of cancer death worldwide. Early accurate diagnosis is crucial for improving survival rates by providing optimal interventions. Biopsy remains the gold standard for current liver cancer diagnosis and heavily relies on traditional CADx methods. However, biopsy is invasive and uncomfortable, and it can easily cause other adverse effects. Therefore, ultrasound-based diagnostic techniques have become one of the most important non-invasive methods for detecting, diagnosing, intervening, and treating liver cancer.
Wu et al. applied a three-layer DBN to achieve good benign and malignant classification of focal liver lesions from contrast-enhanced ultrasound (CEUS) video sequences based on time-intensity curves (TIC). They achieved a maximum accuracy of 86.36%, outperforming traditional machine learning methods [such as Linear Discriminant Analysis (LDA), k-Nearest Neighbors (k-NN), SVM, and Backpropagation Networks (BPN)]. To reduce the computational complexity of using TIC-based feature extraction methods, Guo et al. adopted Deep Canonical Correlation Analysis (DCCA), a variant of Canonical Correlation Analysis (CCA), combined with multiple kernel learning classifiers (MKL, a typical multi-view learning method) to distinguish between benign and malignant liver cancer. Experimental results indicated that fully utilizing these two methods can achieve high classification accuracy (90.41%) with very low computational complexity. Additionally, transfer learning strategies are also commonly applied in liver cancer ultrasound image diagnosis.
2. Nodules
Thyroid nodules have become one of the most common nodular lesions among adults worldwide. Current diagnosis of thyroid nodules mainly relies on non-surgical [mainly fine-needle aspiration (FNA) biopsy] and surgical (i.e., excisional biopsy) methods. However, both methods are time-consuming and labor-intensive for large-scale screening and may cause patient anxiety and increase costs.
With the rapid development of ultrasound technology, ultrasound has become an alternative tool for diagnosing and prognosing thyroid nodules due to its real-time and non-invasive characteristics. To reduce operator dependence and improve diagnostic performance, ultrasound-based CADx systems are easily developed for detecting and classifying thyroid nodules. Ma et al. integrated two pre-trained CNNs in a fused framework for thyroid nodule diagnosis: one is a shallow network more suitable for learning low-level features, while the other is a deep network adept at learning high-level abstract features. More specifically, both CNNs were trained separately on a large thyroid nodule ultrasound image dataset, and the resulting two feature maps were fused and input into the softmax layer for diagnosing thyroid nodules. Integrating high-level features learned from CNNs with traditional handcrafted low-level features is also an option, which has been confirmed in Liu et al.’s research. To overcome redundancy and irrelevance issues in the integrated feature vector and avoid overfitting, it is necessary to select a subset of features. The results indicated that this method improved accuracy by 14% compared to methods using only traditional features. Furthermore, effective preprocessing and data augmentation strategies have been shown to enhance diagnostic performance for specific tasks.
3. Fetuses and Newborns
In prenatal ultrasound diagnosis, fetal biological measurements are essential examinations, including estimating abdominal circumference (AC). However, due to low and uneven contrast, as well as irregular shapes, accurately measuring AC is more challenging than other parameters. In clinical checks and diagnoses, incorrect fetal AC measurements can lead to inaccurate fetal weight estimates, further increasing the risk of misdiagnosis. Therefore, quality control of fetal ultrasound images is crucial.
Recently, Wu et al. proposed a fetal ultrasound image quality assessment scheme, mainly consisting of two steps: 1) a CNN for locating ROIs; and 2) based on the ROI, another CNN for classifying standard fetal abdominal planes. To improve performance, Wu et al. employed data augmentation strategies such as local phase analysis and image cropping. Similarly, Jang et al. used a specially designed CNN structure to classify image blocks from ultrasound images into key anatomical structures, and then estimated fetal AC through an ellipse detection method based on Hough transform for acceptable fetal abdominal planes (i.e., standard planes). Gao et al. explored the transferability of learning features from large-scale natural images to small-scale ultrasound images through a multi-label classification problem of fetal anatomical structures. The results indicated that the transferred CNN outperformed networks directly learning features from small-scale ultrasound data (91.5% vs. 87.5%).
Locating the fetal heart and classifying heart planes are crucial for recognizing congenital heart diseases. Due to the small size of the fetal heart, these tasks are challenging in clinical practice. To address these issues, Sundaresan et al. proposed a solution treating it as a semantic segmentation problem. More specifically, a Fully Convolutional Network (FCN) was used to segment the fetal heart plane in ultrasound image frames, achieving detection of the heart and classification of heart planes in one step. Some post-processing steps were also employed to address the potential inclusion of different non-background areas in the predicted images. Additionally, Perrin et al. directly trained a CNN on ultrasound echocardiographic datasets from five different pediatric populations to identify congenital heart diseases. In a specific fetal standard plane recognition task, a deep CNN with a global average pooling (GAP) strategy achieved significant performance improvements on limited training data.
(2) Detection
In ultrasound image analysis, detecting targets of interest (such as tumors, lesions, and nodules) in ultrasound images or videos is extremely important. In particular, the detection of tumors or lesions can provide strong support for object segmentation and classification of benign and malignant tumors. Localization of anatomical objects (such as fetal standard planes, organs, tissues, or feature points) is also regarded as a prerequisite for segmentation tasks or clinical diagnostic processes based on image interventions and treatments.
1. Tumors or Lesions
Detection or localization of tumors/lesions is crucial in clinical workflows for treatment planning and intervention, and it is also one of the most time-consuming tasks. The detection of lesions in different anatomical structures shows some obvious differences. This task typically involves locating and identifying small lesions across the entire image space. Recently, Azizi et al. successfully achieved prostate cancer detection and grading by combining high-level abstract features extracted from time-enhanced ultrasound images using DBN with tissue structures extracted from digital pathology images. To make a comprehensive comparison, Yap et al. compared three different deep learning methods: block-based LeNet, U-net, and transfer pre-trained FCN-AlexNet for breast cancer detection, finding that all these deep learning methods improved performance on two breast ultrasound image datasets, but no single deep learning model achieved the best performance across true positive rates (TPF), false positives (FP) per image, and F-measure metrics. Similarly, Cao et al. comprehensively compared four optimal CNN-based object detection deep models: Fast R-CNN, Faster R-CNN, You Only Look Once (YOLO), and Single Shot MultiBox Detector (SSD) for breast cancer detection, finding that SSD achieved the best performance in both accuracy and recall.
2. Fetuses
As a routine obstetric examination, fetal ultrasound screening plays a vital role in confirming fetal viability, accurately determining gestational age, and discovering anomalies affecting prenatal care. In the workflow of fetal ultrasound diagnosis, obtaining standard planes is a prerequisite step, crucial for subsequent biological measurements and diagnoses. Besides using traditional machine learning methods to detect fetal ultrasound standard planes, the application of deep learning methods for detecting fetal standard planes is also increasing. Baumgartner et al. and Chen et al. respectively achieved detection of 13 fetal standard planes (such as kidneys, brain, abdomen, spine, femur, and heart sections) in 2D ultrasound images through transferred deep models. To leverage temporal and spatial information, a deep model based on RNN was also transferred for automated detection of multiple fetal standard planes (such as abdominal, facial, and four-chamber heart planes) in ultrasound videos. Additionally, Chen et al. proposed a hybrid universal framework based on convolution and RNN for detecting different standard planes in ultrasound videos.
3. Heart
Accurately identifying the end-diastolic (ED) and end-systolic (ES) phases of the cardiac motion cycle in echocardiographic images is a necessary prerequisite for estimating some cardiac parameters (such as stroke volume, ejection fraction, and maximum diastolic volume). Dezaki et al. proposed a deep residual recurrent neural network (RRN) capable of automatically identifying the phases of the cardiac motion cycle. RRN consists of a residual neural network (ResNet), two blocks of LSTM units, and a fully connected layer, thus combining the advantages of residual neural networks, which can handle the gradient vanishing or explosion problem that arises as the network deepens, and recurrent neural networks, which can model temporal relationships between sequential image frames. Similarly, Sofka et al. proposed a fully convolutional regression network for detecting measurement points in the cardiac parasternal long-axis view, which includes an FCN for regressing measurement point positions and LSTM units for optimizing estimated point positions. Notably, reinforcement learning has also been integrated with deep learning for detecting anatomical key points in cardiac ultrasound images.
(3) Segmentation
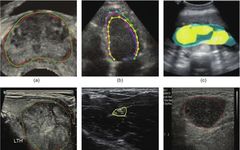
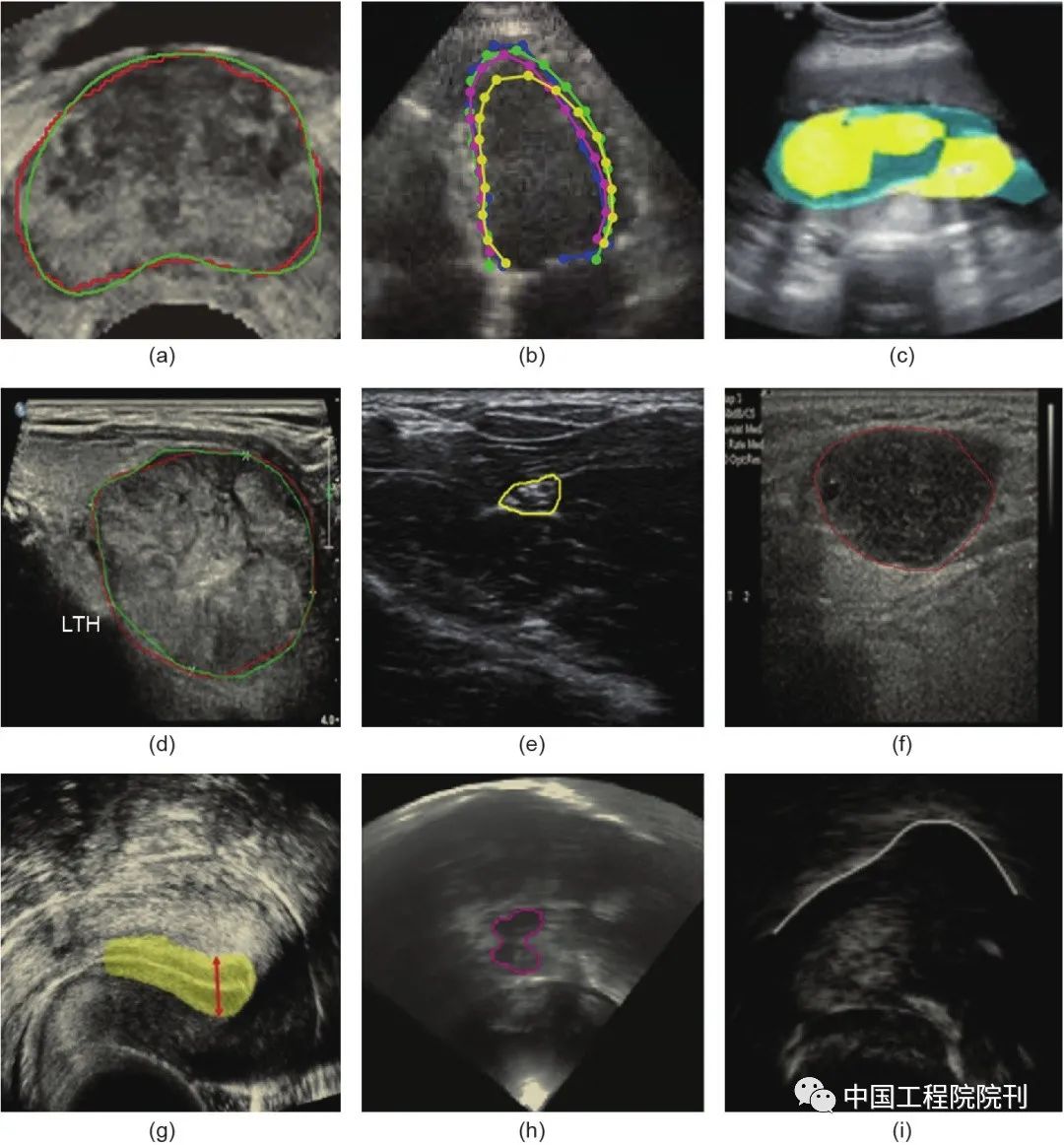
Segmentation of anatomical structures and lesions is a prerequisite for quantifying clinical parameters related to volume and shape in cardiac or brain analyses, and it also plays a crucial role in detecting and classifying lesions (such as breast, prostate, thyroid nodules, and lung nodules) and generating ROIs for subsequent analysis in CADx. Due to the low contrast between targets and backgrounds in ultrasound images, accurately segmenting most anatomical structures, especially lesions (nodules), remains a challenging task. Furthermore, it is well-known that manual segmentation methods are very time-consuming, labor-intensive, and subject to significant individual variability. Therefore, it is necessary to develop more advanced automatic segmentation methods to address these issues. Some results of using deep learning for anatomical structure segmentation are shown in Figure 5.
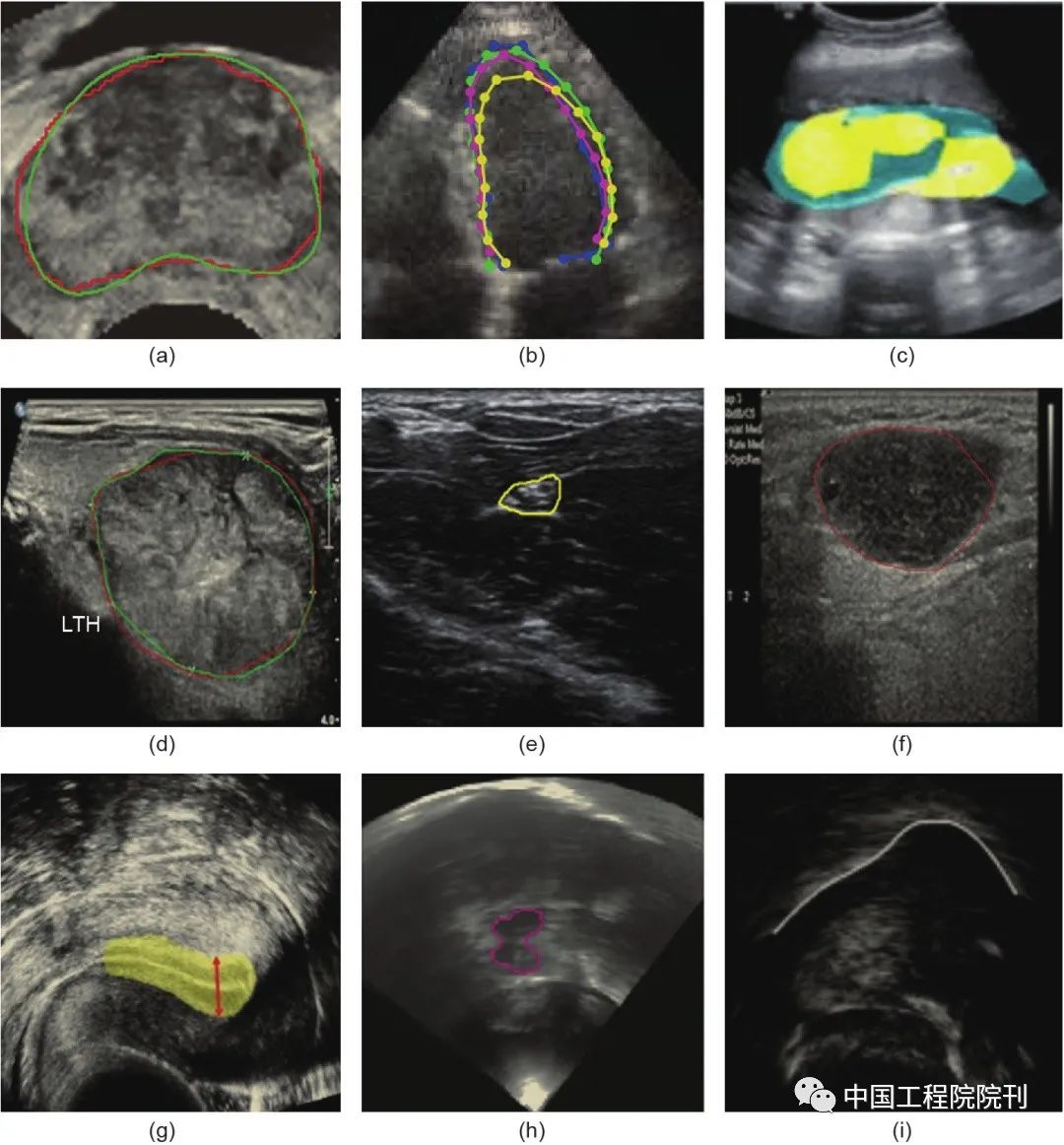
Figure 5 Examples of segmentation results using deep learning for common anatomical structures. (a) Prostate; (b) Left ventricle; (c) Amniotic fluid and fetal body; (d) Thyroid nodule; (e) Central neural structure; (f) Lymph nodes; (g) Endometrium; (h) Midbrain; (i) Tongue contour. All these results demonstrate segmentation performance comparable to that of human radiologists. Different colored lines or points indicate the corresponding segmentation contours or areas.
1. Non-Rigid Organs
Ultrasound echocardiography has become one of the most commonly used imaging modalities for visualizing and diagnosing the left ventricle (LV) due to its low cost, availability, and portability. To diagnose heart disease, cardiologists must perform quantitative functional analyses of the heart, which often requires accurate segmentation of the LV in end-systolic and end-diastolic phases. Clearly, manual segmentation of the LV is tedious, time-consuming, and subjective, while automatic LV segmentation systems have the potential to solve these problems. However, due to significant shape and morphology variations, low signal-to-noise ratios, shadows, and incomplete edges, fully automatic segmentation of the LV remains a challenging task. To address these issues, various traditional machine learning methods, such as active contours and deformable templates, have been widely used for automated segmentation of the LV, which often requires prior knowledge related to the shape and morphology of the LV. Recently, deep learning-based methods have also been frequently adopted. Carneiro et al. utilized DNNs capable of learning high-level features from raw ultrasound images to automatically segment the LV. To enhance performance, several other strategies were also employed, such as efficient search methods, particle filters, online collaborative training methods, and multiple dynamic models.
Typical non-rigid segmentation methods usually divide the segmentation problem into two steps: 1) Rigid detection and 2) Non-rigid segmentation or contour delineation. The first step is crucial as it can reduce search time and lower training complexity. To reduce the training and inference complexity in rigid detection while maintaining high segmentation accuracy, Nascimento and Carneiro utilized sparse manifold learning methods combined with DBN for non-rigid object segmentation. Experimental results indicated that using the combination of sparse manifold learning and DBN in rigid detection achieved performance as accurate as the current optimal results but with lower training and search complexity. Unlike typical non-rigid segmentation methods, Nascimento and Carneiro directly performed non-rigid segmentation through explicit contour sparse low-dimensional manifold mapping, but with limited generalization capabilities. Although most studies indicate that using deep learning can achieve better performance than traditional machine learning methods, a recent study showed that in LV segmentation of 2D ultrasound images, handcrafted features outperformed CNNs, and the computational cost during training was lower. A reasonable explanation is that the supervised descent (SDM) regression method for handcrafted features is more flexible in iteratively optimizing the estimated LV contours.
Compared to adult LV segmentation, fetal LV segmentation is more challenging due to characteristics such as unevenness, artifacts, low contrast, and excessive inter-subject variability in fetal ultrasound images; additionally, because fetuses move randomly in the uterus, the LV and left atrium (LA) are often connected. To address these issues, Yu et al. proposed a dynamic CNN method based on multi-scale information and fine-tuning for fetal LV segmentation. This dynamic CNN performs deep fine-tuning and shallow fine-tuning for the first frame and remaining frames of each ultrasound image sequence, respectively, to adapt to each fetus. Additionally, matching methods were used to separate the connecting regions between the LV and LA. Experimental results indicated that the dynamic CNN achieved significant performance improvements, from 88.35% to 94.5% in average Dice coefficients, compared to fixed CNNs.
2. Rigid Organs
In medical ultrasound images, the incomplete boundaries of many anatomical structures/objects (such as prostate, breast, kidneys, fetuses, etc.) pose significant challenges for their automatic segmentation. Currently, there are two main approaches to address this issue: 1) bottom-up methods, which classify each pixel as foreground (target) or background under supervision; and 2) top-down methods, which utilize prior shape information to guide segmentation. Through an end-to-end, fully supervised learning approach to classify every pixel in the image, many studies have achieved pixel-level segmentation tasks for different anatomical structures (such as fetal body and amniotic fluid, lymph nodes, and bones). For specific tasks, the deep learning methods proposed in these studies have outperformed state-of-the-art methods in terms of performance and speed.
A significant advantage of bottom-up methods is that they provide predictions for every pixel in the image; however, due to a lack of prior shape information, they may not be able to handle the issue of boundary information loss. In contrast, top-down methods can provide strong shape guidance for segmentation tasks by modeling shapes, although appropriate shape modeling is often difficult. To achieve simultaneous learning of key point descriptors and shape inference, Yang et al. represented boundary completeness as a sequential problem, namely dynamically modeling shapes. To simultaneously leverage both bottom-up and top-down methods, Ravishankar et al. utilized shapes learned from shape regularization networks to optimize the predicted segmentation results obtained from FCN segmentation networks. Experimental results on a kidney ultrasound dataset indicated that utilizing prior shape information improved the performance of kidney segmentation by approximately 5%. Furthermore, Wu et al. embedded FCN network kernels into automatic context models to leverage local context information, significantly improving segmentation accuracy.
Another approach to solving segmentation tasks is to frame the segmentation problem as a block-level classification problem, as described in the literature. This method can significantly reduce computational costs and memory requirements.
(4) 3D Ultrasound Image Analysis
Due to the difficulties in applying 3D deep learning, most deep learning methods applied in medical ultrasound image analysis are primarily used on 2D images, even though the inputs may be 3D.
In fact, due to the following limitations, 3D deep learning remains a challenging task: 1) training a deep network on large volumes of data may incur too high computational costs (e.g., significantly increased memory and computation requirements) for practical clinical applications; 2) deep networks that take 3D image blocks as input require more training samples because the parameters contained in 3D networks increase exponentially compared to 2D networks. In the case of limited training data, this may significantly increase the risk of overfitting. Conversely, due to difficulties in generating and sharing images of shared lesions or diseases, the medical ultrasound image analysis field often collects limited training samples (even after data augmentation, the number of samples is typically only in the hundreds or thousands). However, an increasing number of researchers are attempting to tackle these challenging 3D deep learning tasks in the medical ultrasound image analysis field.
In routine gynecological ultrasound examinations and screening for endometrial cancer in postmenopausal women, thickness measurement is typically used to assess the endometrium. Singhal et al. proposed a two-step algorithm based on FCN to achieve fully automated measurement of endometrial thickness. First, they proposed a hybrid variational curve-propagation model called the Deep Learning Snake (DLS) segmentation model to detect and segment the endometrium from 3D transvaginal ultrasound volume data. This model integrates the endometrial probability map of deep learning into the segmentation energy function, which is predicted through the U-net-based endometrial localization on the sagittal plane. After segmentation, the maximum distance between the two contact surfaces (the basal layer) in the segmentation mask is used as the measured thickness.
To address the problem of automatically locating needle-like targets during ultrasound-guided epidural needle injections in obstetrics and chronic pain treatment, Pesteie et al. proposed a convolutional network structure and feature enhancement techniques. This method includes two steps: 1) classifying planes from 3D ultrasound volume data using Local Directed Hadamard (LDH) features and a forward feedback neural network; 2) achieving target localization by classifying each pixel in the identified target plane through CNN.
Nie et al. proposed a method for automatically detecting the mid-sagittal plane from complex 3D ultrasound data. To avoid unnecessary large-scale searches and the corresponding massive computational load, they cleverly transformed the mid-sagittal plane detection problem into a symmetry plane and axis search problem. More specifically, this method involves three steps: 1) establishing a DBN to detect images that fully contain the fetal head from the intermediate sections of 3D ultrasound data based on the literature; 2) determining the position and size of the fetal head in the image block using an enhanced circular detection method; 3) finally, determining the mid-sagittal plane based on a model and the prior knowledge of the fetal head’s position and size determined in the previous two steps.
It should be noted that these three methods are essentially based on 2D deep learning slice-by-slice methods, although they can be applied to 3D ultrasound volume data. The advantages of this approach are high speed, low memory consumption, and the ability to directly utilize pre-trained networks either directly or through transfer learning. However, the downside is that this approach cannot leverage the structural contextual information from orthogonal directions of the image planes. To overcome these drawbacks, Milletari et al. proposed a multi-slice method called Hough-CNN for detecting and segmenting multiple deep brain regions. This method employs a similar Hough voting strategy as proposed in earlier studies, with the distinction that structure-specific features are obtained through CNN rather than SAE. To fully utilize contextual information in 3D ultrasound volume data, Pourtaherian et al. directly trained a 3D CNN to detect needle-like voxels in 3D ultrasound volume data, with each voxel classified based on raw data extracted from three orthogonal planes centered around it. To address the highly imbalanced dataset issue, a new updating strategy was employed, namely resampling non-needle-like voxels during the training phase to enhance detection performance and robustness.
Typical non-rigid object segmentation schemes widely applied to 2D ultrasound images are also applicable to the segmentation of 3D ultrasound volumes. Ghesu et al. employed this typical non-rigid segmentation method to achieve segmentation of the aortic valve in 3D ultrasound volumes, which includes two steps: rigid target localization and non-rigid target boundary estimation. To address the problem of 3D target detection, edge-space deep learning methods (MSDL) were employed, which combine edge-space learning (MSL) with deep learning. Based on the detected targets, an initial estimate of the non-rigid shape is made, followed by guiding shape deformation using a sparse adaptive DNN-based active shape model. Experimental results on a large 3D transesophageal echocardiographic dataset confirmed the efficiency and robustness of MSDL in the 3D detection and segmentation tasks of the aortic valve, with its performance improved by 42.5% over the previously state-of-the-art methods. Using only Central Processing Units (CPUs), the aortic valve can be successfully segmented in less than 1 second, with accuracy higher than the original MSL.
Segmentation of fetal structures is more challenging than that of general anatomical structures or organs. For example, the placenta’s height can vary significantly as its position depends on the implantation site within the uterus. While manual segmentation and semi-automatic segmentation methods have been shown to be accurate and acceptable, they are particularly time-consuming and reliant on the operator’s experience. To address these issues, Looney et al. employed DeepMedic to segment the placenta from 3D ultrasound volumes. The training dataset did not use manually annotated data but rather utilized outputs from a semi-automatic random walk (RW) method as labeling results. DeepMedic is a dual-channel 3D CNN structure initially proposed for lesion segmentation in brain MRI data. However, the successful segmentation of the placenta from 3D ultrasound volumes indicates that DeepMedic is a versatile 3D deep learning structure applicable to different modal 3D medical volume data. Recently, Yang et al. incorporated RNN into a customized 3D FCN to simultaneously segment multiple targets in ultrasound volumes, including the fetus, gestational sac, and placenta. To address the common issue of boundary uncertainty, an effective serialization strategy was employed. Moreover, they proposed a hierarchical deep supervision mechanism to promote information flow in the recurrent neural network, further enhancing segmentation performance.
4.
Challenges and Application Prospects
As can be seen from the examples above, deep learning has been applied to various application areas in medical ultrasound image analysis. However, despite the continuous updates of deep learning methods in different application aspects of medical ultrasound image analysis, there is still room for improvement. This section will summarize the challenges commonly encountered when applying deep learning to medical ultrasound image analysis and discuss its future development prospects.
Clearly, the significant performance improvements that deep learning can achieve largely depend on large sample training datasets. However, compared to large-scale and publicly available datasets in other fields (such as the ImageNet dataset with over 1×106 labeled multi-category natural images), publicly available datasets in the current medical ultrasound field remain limited. Limited datasets have become a bottleneck for further applications of deep learning methods in medical ultrasound image analysis.
To address the issue of small sample datasets, one of the most commonly used methods by researchers is to conduct cross-dataset (intra-modal or inter-modal) learning, namely transfer learning. As mentioned earlier, the use of transfer learning is mainly divided into two categories: directly utilizing pre-trained networks as feature extractors and fine-tuning partial weights in fixed networks.
Transfer learning can be classified into two categories based on whether the target domain and source domain are the same: cross-modal and cross-domain transfer learning. Cross-domain transfer learning is the most commonly used method for various tasks in medical ultrasound image analysis. In any case, the current model pre-training is always performed on large sample datasets. This ensures excellent performance, but this is definitely not the best choice in the field of medical imaging. When using small sample training datasets, deep models specifically designed for medical imaging tasks can outperform transfer learning from large sample datasets in other fields (such as natural images) when appropriately selecting model sizes. The fundamental reason for this phenomenon may be that the mapping from raw input image pixels to feature vectors for specific tasks in medical image analysis becomes more complex under pre-training conditions, thus requiring large sample training datasets to have good generalization capabilities. Conversely, specially designed small networks may be more suitable for the small-scale training datasets commonly present in medical imaging. Therefore, developing deep learning models specifically for the medical imaging field can not only improve performance on specific tasks with lower computational complexity but also promote the technological development of CADx in the medical imaging field.
Moreover, models trained on natural images may not be the best models for medical images, which are typically single-channel, low-contrast, and rich in texture features. In medical imaging, especially breast imaging, various imaging modalities such as MRI, X-ray, and ultrasound are often used in diagnostic workflows, with ultrasound or mammography typically serving as the first-line screening tools, making it easier to collect large training datasets. However, mammography, which is often used to screen high-risk populations, is a more expensive and time-consuming method, making it even more challenging to collect sufficient training datasets and perform labeling. In this case, cross-modal transfer learning may be a viable option. Experiments have shown that in the absence of sufficient training datasets, cross-modal transfer learning outperforms cross-domain transfer learning for specific tasks. This is because it is rare to collect large sample datasets from a single site (i.e., institution or hospital), and they are usually collected from multiple different sites (or machines), so attempts can be made for cross-site (or cross-machine) transfer learning within the same imaging modality.
Finally, other issues with current transfer learning algorithms must also be addressed, including how to avoid negative transfer, how to handle feature space inconsistencies between source and target domains or source and target tasks, and how to improve the generalization capabilities of different tasks. The goal of transfer learning is to utilize the knowledge learned from the source task to enhance the learning performance of the target task. However, inappropriate transfer learning can sometimes lead to reduced performance, resulting in negative transfer.
Ignoring the inherent differences between different methods, the effectiveness of any transfer learning for specific target tasks mainly depends on two aspects: the source task and its relationship to the target. Ideally, transfer methods will produce positive transfer across sufficiently related tasks while avoiding negative transfer, though these tasks may not be perfectly matched. However, achieving these goals in practice is often challenging. To avoid negative transfer, the following strategies can be employed: 1) identify and reject harmful knowledge from source tasks; 2) select the best source task from a set of candidate source tasks (if possible); 3) model the task similarity of multiple candidate source tasks. Furthermore, when the representations of source and target tasks are inconsistent, mappings can be used for the transfer between task representations.
It is worth emphasizing again that 3D ultrasound is an important imaging modality in the field of medical imaging, and 3D ultrasound image analysis shows enormous potential for clinical applications based on ultrasound, although some issues remain to be resolved. It is foreseeable that more novel 3D deep learning algorithms will be developed for various tasks in medical ultrasound image analysis, achieving greater performance improvements in the future. However, without support from other fields, especially CV, the current development of 3D deep learning algorithms in the medical ultrasound image analysis field will be relatively challenging.
Note: The content of this article has been slightly adjusted; the original article can be referred to for further details.
Adapted from:
Shengfeng Liu, Yi Wang, Xin Yang, Baiying Lei, Li Liu, Shawn Xiang Li, Dong Ni, Tianfu Wang. Deep Learning in Medical Ultrasound Analysis: A Review[J]. Engineering, 2019, 5(2): 261-275.
☟ If you need to read the full text, please click on “Read the Original” at the end of the article.
☟ For more readings, please click the links below to view.

Click the image to read丨Cutting-edge Research: AI-Assisted COVID-19 Imaging Recognition—AI Technology from Laboratory to Clinic
Click the image to read丨Strategic Research: Discussion on Rapid Layout and Development Strategy of AI in Hospitals under the Background of COVID-19 Pandemic

Click the image to read丨Cutting-edge Research: Information Science Should Lead Future Biomedical Research

Journal of the Chinese Academy of Engineering
Engineering Benefits Humanity
Technology Creates the Future
WeChat Public Account ID: CAE-Engineering
Note: The paper reflects the progress of research results and does not represent the views of the “Journal of Chinese Engineering Science”.