
MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and corporate researchers. The vision of the community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners. Reprinted from | ZHUANZHI

Abstract—Artificial Intelligence (AI) has rapidly developed due to the enhancement of computational power and the growth of massive datasets. However, this progress has intensified the challenges of explaining the “black box” nature of AI models. To address these issues, Explainable Artificial Intelligence (XAI) has emerged, focusing on transparency and explainability to enhance human understanding and trust in AI decision-making processes. In the context of multimodal data fusion and complex reasoning scenarios, the introduction of Multimodal Explainable Artificial Intelligence (MXAI) integrates various modalities for prediction and explanation tasks. Meanwhile, the emergence of Large Language Models (LLMs) has driven significant breakthroughs in natural language processing, but their complexity further exacerbates the MXAI challenges. To gain a deeper understanding of the development of MXAI methods and provide important guidance for building more transparent, fair, and trustworthy AI systems, we review the historical perspective of MXAI methods and categorize them into four development stages: traditional machine learning, deep learning, discriminative foundational models, and generative large language models. We also review the evaluation metrics and datasets used in MXAI research and discuss future challenges and development directions. Related projects have been created at https://github.com/ShilinSun/mxai_review.
Keywords—Large Language Models (LLMs), Multimodal Explainable Artificial Intelligence (MXAI), Historical Perspective, Generative.
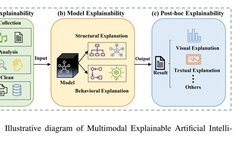
Advancements in Artificial Intelligence (AI) have significantly impacted computer science, with models like Transformer [1], BLIP-2 [2], and ChatGPT [3] excelling in natural language processing (NLP), computer vision, and multimodal tasks by integrating various data types. The development of these related technologies has propelled advancements in specific applications. For instance, in autonomous driving, systems need to integrate data from different sensors, including vision, radar, and LiDAR, to ensure safe operation in complex road environments [4]. Similarly, health assistants need to have transparency and trustworthiness so that both doctors and patients can easily understand and verify [5]. Understanding how these models combine and explain different modalities is crucial for enhancing model credibility and user trust. Additionally, the continuous increase in model scale has brought challenges such as computational costs, explainability, and fairness, driving the demand for Explainable Artificial Intelligence (XAI) [6]. As models, including generative large language models (LLMs), become increasingly complex and data modalities more diverse, single-modality XAI methods can no longer meet user needs. Therefore, Multimodal Explainable Artificial Intelligence (MXAI) addresses these challenges by utilizing multimodal data in the model’s prediction or explanation tasks, as shown in Figure 1. We categorize MXAI into three types based on the order of data processing: data explainability (pre-model), model explainability (in-model), and post-hoc explainability (post-model). In multimodal prediction tasks, models process multiple data modalities, such as text, images, and audio; in multimodal explanation tasks, various modalities are used to explain results, providing a more comprehensive final output explanation.
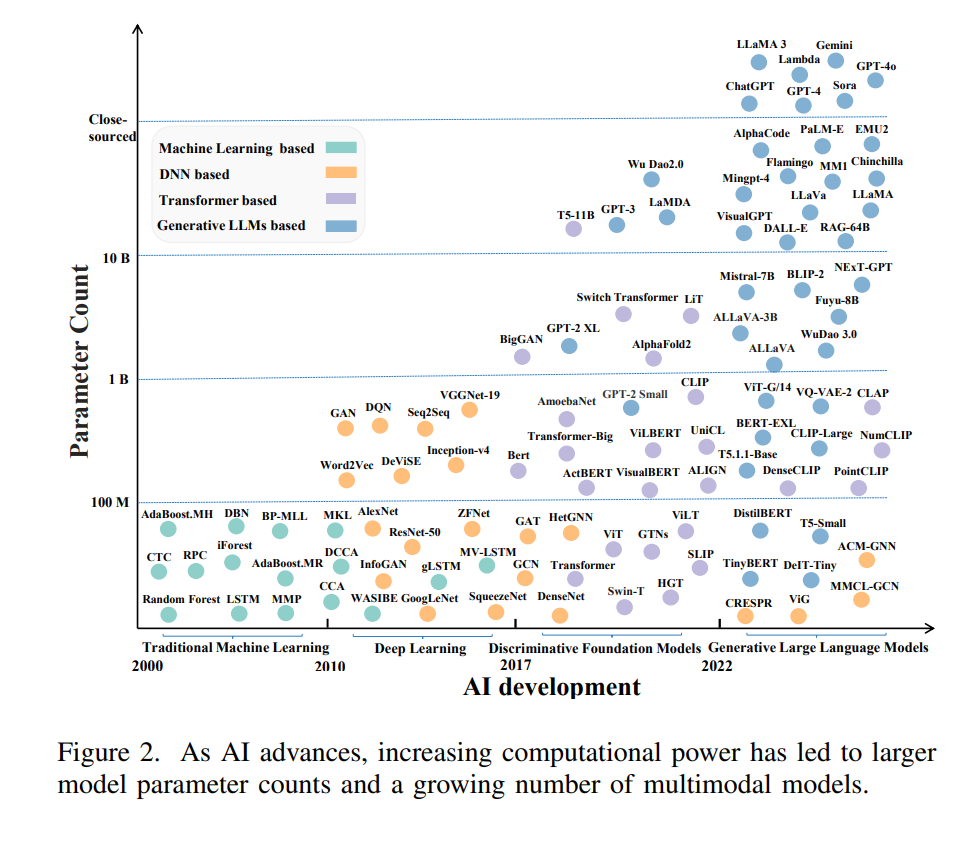
To review the history of MXAI and predict its development, we first categorize different stages and retrospectively analyze various models (as shown in Figure 2). In the era of traditional machine learning (2000-2009), the limited availability of structured data facilitated the emergence of interpretable models like decision trees. In the deep learning era (2010-2016), the advent of large annotated datasets (such as ImageNet [7]) and enhanced computational power brought complex models and explainability research to the forefront, including the visualization of neural network kernels [8]. During the discriminative foundational model era (2017-2021), the emergence of Transformer models, leveraging large-scale text data and self-supervised learning, revolutionized natural language processing (NLP). This shift sparked research into the explainability of attention mechanisms [1],[9]–[11]. In the generative large language model era (2022-2024), the integration of vast multimodal data has driven the development of generative large language models (LLMs), such as ChatGPT [3], and multimodal fusion technologies. These advancements provide comprehensive explanations, enhancing the transparency and credibility of models. This evolution has led to increased attention to MXAI, which explains models that handle diverse data types [6].
However, recent reviews on XAI often overlook historical developments, focusing mainly on single-modality methods. For example, although [6] classifies MXAI methods by modality count, explanation stages, and method types, it neglects the explainability techniques for LLMs. While Ali et al. [12] proposed a comprehensive four-axis classification, it lacks a summary on multimodality and LLMs. However, reviews like [13], [14], and [15] focus solely on the explainability of LLMs. Our study addresses these shortcomings by providing a historical perspective on MXAI, categorizing MXAI methods into four eras (traditional machine learning, deep learning, discriminative foundational models, and generative large language models) and subdividing each era into three categories (data, model, and post-hoc explainability). The main innovative contributions of this paper are summarized as follows:
-
We provide a historical summary and analysis of MXAI methods, including traditional machine learning methods and current MXAI methods based on LLMs.
-
We analyze cross-era methods, covering data, model, and post-hoc explainability, as well as related datasets, evaluation metrics, future challenges, and development directions.
-
We review existing methods, summarize current research approaches, and provide insights and a comprehensive perspective on future developments from a historical evolution standpoint.
The Era of Generative Large Language Models
This era focuses on advancing generative tasks based on the foundations laid by discriminative models (2017-2021). Unlike their predecessors, these models, such as GPT-4 [240], BLIP-2 [2], and their successors, enhance explainability by generating coherent and contextually relevant text, providing natural language explanations for outputs. This advancement bridges the gap between human understanding and machine decision-making, making interactions with models more nuanced and providing greater insight into model behavior. We summarize related work in Table V.
A. Data Explainability
-
Explaining Datasets: Large Language Models (LLMs) can effectively explain datasets through interactive visualization and data analysis. LIDA [241] helps understand the semantics of data by generating syntax-independent visual charts and infographics, listing relevant visualization targets, and generating visualization specifications. Other methods [242]–[245] enhance dataset explainability by analyzing datasets. By integrating multimodal information and powerful natural language processing capabilities, LLMs can provide comprehensive, in-depth, customized, and efficient data explanations [13]. Bordt et al. [246] explore the capabilities of LLMs in understanding and interacting with “glass box” models, identifying anomalous behaviors and proposing fixes or improvements. The focus is on leveraging the explainability of multimodal data to enhance these processes.
-
Data Selection: Data selection is crucial in this era. It improves model performance and accuracy, reduces bias, enhances model generalization capabilities, saves training time and resources, and increases explainability, making the decision-making process more transparent and aiding model improvement [302]. Multimodal C4 [247] enhances dataset quality and diversity by integrating multiple sentence-image pairs and implementing rigorous image filtering, excluding small, irregularly proportioned images and images containing faces. This method emphasizes the relevance of text-image relationships, enhancing the robustness and explainability of multimodal model training. A new paradigm of generative AI based on heuristic mixed data filtering is also proposed, aimed at enhancing user immersion and improving the interaction level between video generation models and language tools (e.g., ChatGPT [3]). This method enables the generation of interactive environments from a single text or image prompt. In addition to the above, some efforts aim to improve model robustness to distribution changes and out-of-distribution data [249],[250].
-
Graph Modeling: Although Multimodal Large Language Models (MLLMs) can process and integrate data from different modalities, they often implicitly capture relationships. In contrast, graph modeling provides a more intuitive understanding of complex data relationships by explicitly representing data nodes (e.g., objects in images, concepts in text) and their relationships (e.g., semantic associations, spatial relationships). Some methods [251]–[253] combine graph structures with LLMs to enhance performance and explainability in complex tasks through multimodal integration.
B. Model Explainability
-
Process Explanation: In this era, the process explanation of MXAI emphasizes In-context Learning (ICL) and Multimodal Chain of Thought (CoT). The highlight of ICL is its ability to avoid extensive updates to large model parameters by using human-understandable natural language instructions [303]. Emu2 [254] enhances task-agnostic ICL by extending multimodal model generation. Link context learning (LCL) [304] focuses on causal reasoning to enhance the learning capabilities of Multimodal Large Language Models (MLLMs). [255] proposes a comprehensive framework for Multimodal ICL (M-ICL), applicable to models like DEFICS [256] and OpenFlamingo [257], covering various multimodal tasks. MM-Narrator [258] utilizes GPT-4 [240] and multimodal ICL to generate audio descriptions (AD). Further advancements in ICL and new variants of multimodal ICL are discussed in [259]. MSIER [260] uses neural networks to select instances that can improve the efficiency of multimodal context learning.
-
Multimodal CoT addresses the limitations of single-modality models in complex tasks, where relying solely on text or images cannot comprehensively capture information. Text lacks visual cues, while images lack detailed descriptions, limiting the model’s reasoning ability [305]. Multimodal CoT resolves this issue by integrating and reasoning over various data types, such as text and images [261]–[264]. For example, image recognition can be broken down into a step-by-step cognitive process, constructing a network chain that generates visual biases, which are added to the input word embeddings at each step [261]. Zhang et al. [262] first generate reasoning evidence from visual and language inputs, then combine it with the original input for reasoning. Mixed reasoning evidence [306] uses text reasoning to guide visual reasoning, providing coherent and transparent answer explanations through feature fusion.
-
Intrinsic Explainability: In this section, we explore the intrinsic explainability of Multimodal Large Language Models (MLLMs), focusing on two main tasks: multimodal understanding and multimodal generation [307]. The multimodal understanding tasks include image-text, video-text, audio-text, and multimodal-text understanding. In image-text understanding, BLIP-2 [2] enhances explainability through a two-stage pre-training process, aligning visual data with textual data to improve the coherence and relevance of image descriptions. LLaVA [308] generates instruction-following data by converting image-text pairs into a format compatible with GPT-4 [240] and fine-tuning by connecting CLIP’s visual encoder with LLaMA’s language decoder. Variants like LLaVA-MoLE [309], LLaVA-NeXT [271], and LLaVA-Med [272] have enhanced this foundation, making improvements for specific fields and tasks.
Conclusion
This paper categorizes Multimodal Explainable Artificial Intelligence (MXAI) methods into four eras based on historical development: traditional machine learning, deep learning, discriminative foundational models, and generative large language models. We analyze the evolution of MXAI from the perspectives of data, model, and post-hoc explainability, and review relevant evaluation metrics and datasets. Looking ahead, the main challenges include scaling explainability techniques, balancing model accuracy with explainability, and addressing ethical issues. The ongoing advancement of MXAI is crucial for ensuring the transparency, fairness, and trustworthiness of AI systems.
Technical Communication Group Invitation

△ Long press to add the assistant
Scan the QR code to add the assistant WeChat
Please note: Name – School/Company – Research Direction(e.g., Xiao Zhang – Harbin Institute of Technology – Dialogue System)to apply for joining technical communication groups such as Natural Language Processing/Pytorch
About Us
MLNLP Community is a grassroots academic community jointly built by scholars in machine learning and natural language processing from both domestic and international backgrounds. It has developed into a well-known machine learning and natural language processing community aimed at promoting progress among the academic and industrial sectors of machine learning and natural language processing, as well as among enthusiasts.The community can provide an open communication platform for practitioners in further education, employment, and research. Everyone is welcome to follow and join us.
