Excerpt from Medium
Author: Camron Godbout
Translated by: Machine Heart
Contributors: Duxiade
What are Recurrent Neural Networks (RNNs) and how do we use them? This article discusses the basics of RNNs, which are increasingly popular deep learning models. The intention of this article is not to delve into the obscure mathematical principles but to provide readers with a conceptual understanding of RNNs.
General Information on RNNsRecurrent Neural Networks emerged in the 1980s and have become increasingly popular recently due to advancements in network design and the computational power of Graphics Processing Units (GPUs). These networks are particularly useful for sequential data, as each neuron or unit can retain relevant information from previous inputs in its internal storage. In the case of language, the meaning of “I had washed my house” is different from “I had my house washed.” This allows the network to gain a deeper understanding of the expression. It is important to note this because when reading a sentence or even a person, one must derive the context of each word from its preceding words.
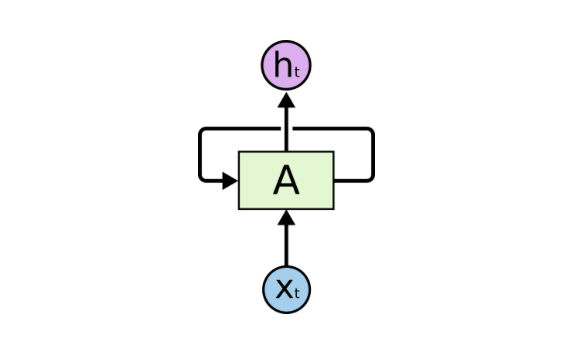
A Rolled Recurrent Neural Network
An RNN consists of many loops that allow information to pass through neurons while reading them from the input.
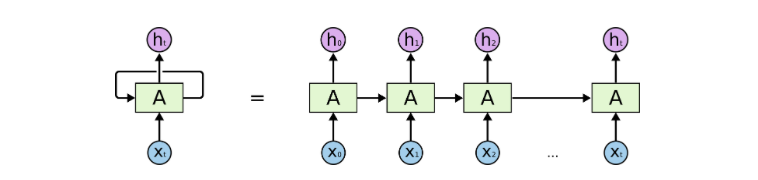
An Unrolled Recurrent Neural Network
In these diagrams, xt represents certain inputs, A is part of the RNN, and ht is the output. Essentially, you can input words from a sentence or even characters from a string like xt, and the RNN will produce a ht. The goal is to use ht as the output and compare it with your test data (usually a small subset of the original data). You will then derive your error rate. After comparing, with the error rate, you can use a technique called Backpropagation Through Time (BPTT). BPTT checks the network and adjusts the weights based on the error rate. This also adjusts the network and allows it to learn to perform better. Theoretically, RNNs can process context from the beginning of a sentence, allowing for more precise predictions of words at the end of a sentence. In practice, this is not genuinely required for vanilla RNNs. This is why RNNs faded from the research scene for a while until Long Short-Term Memory (LSTM) units achieved some impressive results and brought them back into the spotlight. The networks with LSTM added act like they have a memory unit, capable of remembering the context of the initial content of the input.
These few memory units allow RNNs to be more accurate, which is the recent reason for the popularity of this model. These memory units allow for context retention across inputs. Among these units, LSTM and Gated Recurrent Units (GRU) are two of the most widely used today, with the latter being more computationally efficient as they consume less computer memory.
Applications of Recurrent Neural Networks
RNNs have many applications. A notable application is their collaboration with Natural Language Processing (NLP). Many individuals online have demonstrated RNNs, creating astonishing models capable of representing a language model. These language models can accept a large amount of input, such as Shakespearean poetry, and generate their own Shakespearean-style poetry after training, which can be difficult to distinguish from the original.
Below is a Shakespearean-style poem.
PANDARUS:
Alas, I think he shall be come approached and the day
When little srain would be attain’d into being never fed,
And who is but a chain and subjects of his death,
I should not sleep.
Second Senator:
They are away this miseries, produced upon my soul,
Breaking and strongly should be buried, when I perish
The earth and thoughts of many states.
DUKE VINCENTIO:
Well, your wit is in the care of side and that.
Second Lord:
They would be ruled after this chamber, and
my fair nues begun out of the fact, to be conveyed,
Whose noble souls I’ll have the heart of the wars.
Clown:
Come, sir, I will make did behold your worship.
VIOLA:
I’ll drink it.
This poem was entirely written by an RNN. Here is a good article that delves deeper into Char RNNs.
This special type of RNN is fed on a text dataset, reading the input character by character. The surprising aspect of this approach, compared to feeding one word at a time, is that the network can create its own unique words that are not in the training vocabulary.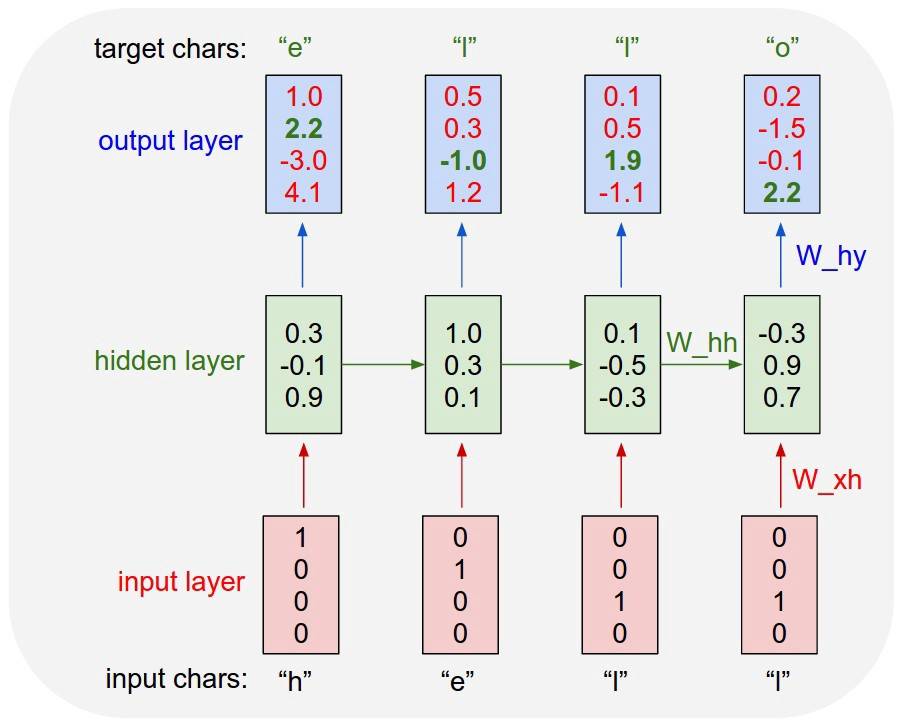
An Example of a Char RNN
This chart, extracted from the above reference article, illustrates how the model will predict the word “Hello.” This diagram visualizes how the network adopts each word character by character and predicts the likelihood of the next character.
Another surprising application of RNNs is machine translation. This method is intriguing because it requires training two RNNs simultaneously. In these networks, the input consists of paired sentences in different languages. For example, you can input a pair of sentences in English and French that have the same meaning, where English is the source language and French is the target language. After sufficient training, you can give this network an English sentence, and it will translate it into French! This model is known as a Sequence to Sequence model or Encoder-Decoder model.
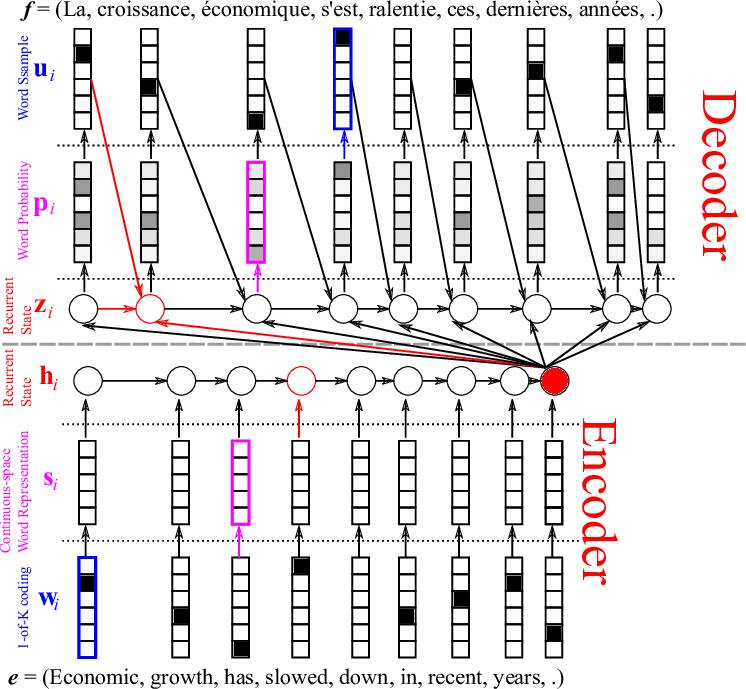
Example of English-French Translation
This chart illustrates how information flows through the Encoder-Decoder model, utilizing a word embedding layer to achieve better word representations. A word embedding layer is typically GloVe or Word2Vec algorithms that can batch process words and create a weight matrix that connects similar words together. Using an embedding layer typically makes your RNN more accurate as it better represents what similar words are like, reducing the network’s inference.
Conclusion
RNNs are now very popular. They are one of the most effective models in Natural Language Processing. New applications for these models continue to emerge.
© This article is translated by Machine Heart, for reprint, please contact this public account for authorization.
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submissions or Reporting Requests: [email protected]
Advertising & Business Cooperation: [email protected]