

Big Data Digest Works
Compiled by: Wan Jun, Da Jie Qiong, Qian Tian Pei
Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) networks, which have been incredibly popular, it’s time to abandon them!
LSTM and RNN were invented in the 1980s and 1990s, resurrected in 2014. In the following years, they became the go-to solutions for sequence learning and sequence transformation (seq2seq), dramatically enhancing capabilities in speech-to-text recognition and voice assistants like Siri, Cortana, Google Assistant, and Alexa.
Additionally, let’s not forget machine translation, which includes translating documents into different languages, or neural network machine translation that can translate images into text, text into images, and subtitle videos, etc.
In the following years, ResNet emerged. ResNet is a residual network, designed to train deeper models. In 2016, a group of researchers from Microsoft Research Asia won the ImageNet image recognition challenge with an astonishing 152-layer deep residual network, dominating all three major tasks of image classification, image localization, and image detection. Following that, the Attention model appeared.
Although it has only been two years, today we can confidently say:
“Stop using RNN and LSTM, they are no longer effective!”
Let’s speak with facts. Companies like Google, Facebook, and Salesforce are increasingly adopting networks based on Attention models.
All these companies have replaced RNNs and their variants with Attention-based models, and this is just the beginning. Compared to Attention-based models, RNNs require more resources to train and operate. RNNs are on their way out.
Why?
Remember that RNN and LSTM primarily process sequences over time. Refer to the horizontal arrows in the diagram below:
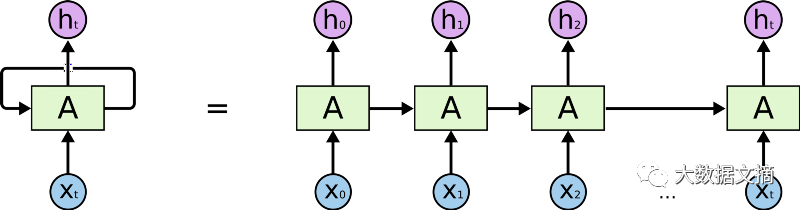
Sequential processing in RNNs
The horizontal arrows indicate that long-term information must sequentially traverse all units before entering the current processing unit. This means it can easily be multiplied by many times a small decimal <0, which can corrupt it. This is the cause of the vanishing gradients problem.
To address this, the LSTM model, which is now considered a savior, emerged. Similar to the ResNet model, it can bypass units to remember longer time steps. Therefore, LSTM can alleviate some of the vanishing gradient issues.
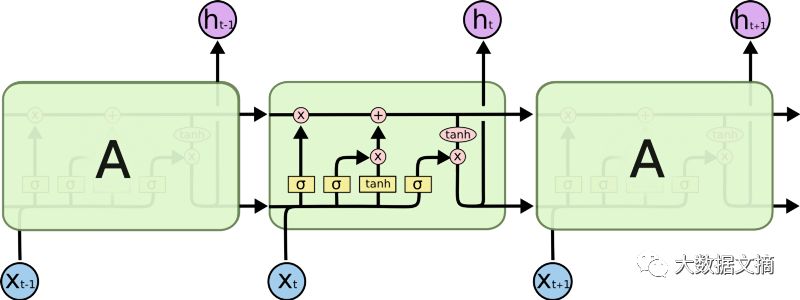
Sequential processing in LSTM
From the above diagram, it can be seen that this does not solve all the problems. We still have a sequential path from past units to the current unit. In fact, this path is now more complex because it has additional components and ignores branches belonging to it.
Undoubtedly, LSTM and GRU (Gated Recurrent Unit, a derivative of LSTM) and their derivatives can remember a lot more long-term information! However, they can only remember sequences on the order of 100, not 1000 or longer sequences.
Another problem with RNNs is that training them has very high hardware requirements. Furthermore, even when we do not need to train these networks quickly, they still require a lot of resources. Similarly, running these models in the cloud also demands significant resources.
Given the rapidly growing demand for speech-to-text, the cloud is not scalable. We need to process at the edge, like processing data on Amazon Echo.
What to Do?
If we want to avoid sequential processing, we can find “forward” or better “backward” units, because most of the time we deal with real-time causal data, we “look back” and want to know its impact on future decisions (“influence the future”). This is not the case when translating sentences or analyzing recorded videos, for example, we have complete data and enough processing time. Such backward/forward units are groups of Neural Attention models.
To achieve this, by combining multiple Neural Attention models, the “Hierarchical Neural Attention Encoder” emerged, as shown in the diagram below:
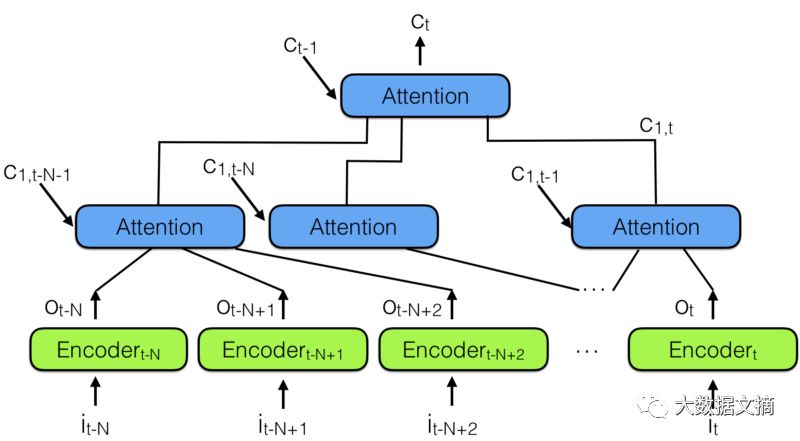
Hierarchical Neural Attention Encoder
A better way to “look back” is to use Attention models to aggregate past encoded vectors into the context vector CT.
Note that there is a hierarchical Attention model structure above, which is very similar to the neural network hierarchy. This is also similar to the Temporal Convolutional Network (TCN) mentioned in note 3 below.
In the Hierarchical Neural Attention Encoder, multiple Attention layers can look at a small portion of the recent past, say 100 vectors, while the upper layers can view these 100 Attention modules, effectively integrating the information of 100 x 100 vectors. This will extend the capability of the Hierarchical Neural Attention Encoder to 10,000 past vectors.
This is the right way to “look back” and be able to “influence the future”!
But more importantly, consider the path length required for representation vectors to propagate to the network output: in hierarchical networks, it is proportional to log(N), where N is the number of hierarchical layers. This contrasts with the T steps that RNNs need to do, where T is the maximum length of the sequence to be remembered, and T >> N.
Skipping 3-4 steps to retrieve information is much easier than skipping 100 steps!
This architecture resembles a Neural Network Turing Machine, but allows the neural network to decide what to read from memory through Attention. This means a practical neural network will determine which past vectors are important for future decisions.
But how about storing in memory? The above architecture stores all previous representations in memory, which is different from the Neural Network Turing Machine (NTM). This could be quite inefficient: consider storing the representation of each frame in a video—most of the time, the representation vectors do not change from frame to frame, so we indeed store too much of the same content!
What we can do is add another unit to prevent similar data from being stored. For example, not storing vectors that are too similar to previously stored vectors. But this is really just a hack, and the best approach is to let the application guide which vectors should be saved or not. This is the focus of current research.
Seeing so many companies still using RNN/LSTM for speech-to-text conversion, I am really surprised. Many people do not realize how inefficient and unscalable these networks are.
The Nightmare of Training RNN and LSTM
Training RNNs and LSTMs is difficult because they require storage bandwidth-bound computations, which is the worst nightmare for hardware designers, ultimately limiting the applicability of neural network solutions. In short, LSTMs require four linear layers (MLP layers) to run at each sequence time step.
Linear layers require a lot of storage bandwidth to compute, and in fact, they cannot use many computation units, often because the system does not have enough storage bandwidth to meet the computational units. It is easy to add more computation units, but it is hard to increase more storage bandwidth (note that there are enough lines on the chip, such as long wires from the processor to storage, etc.).
Thus, RNN/LSTM and their variants are not a good match for hardware acceleration, as we have discussed here and here before. One solution would be to compute in the storage device, as we are working on at FWDNXT.
In summary, abandon RNNs. Attention models are truly everything you need!
Related Reports:
https://towardsdatascience.com/the-fall-of-rnn-lstm-2d1594c74ce0
【Today’s Machine Learning Concept】
Have a Great Definition

Volunteer Introduction
Reply“Volunteer” to Join Us



