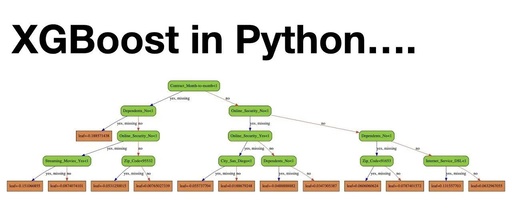
This tutorial showcases the application process and workflow of machine learning algorithms through case studies and code-driven examples, enabling you to master the ability to build scenario modeling solutions and perform effect optimization.This article provides a detailed explanation of the engineering application methods of XGBoost. XGBoost is a powerful boosting algorithm toolkit that is the preferred model for many large companies’ machine learning solutions, demonstrating excellent performance in parallel computing efficiency, handling missing values, and controlling overfitting.
https://www.showmeai.tech/article-detail/204
XGBoost stands for eXtreme Gradient Boosting, and it is a very powerful boosting algorithm toolkit. Its outstanding performance (effectiveness and speed) has kept it at the top of data science competition solutions for a long time. Many large companies still prefer this model in their machine learning solutions. XGBoost excels in parallel computing efficiency, handling missing values, controlling overfitting, and generalization capability.
Installing XGBoost
XGBoost, as a common and powerful Python machine learning toolkit, is relatively easy to install.
Setting Up Python and IDE Environment

For setting up the Python environment and IDE, you can refer to ShowMeAI’s article on Python Installation and Environment Setup [2].
Installing the Toolkit
(1) Linux/Mac Systems
For installing XGBoost on these systems, you can easily complete it using pip by entering the following command in the terminal:
pip install xgboostYou can also choose a domestic pip source for better installation speed.
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xgboost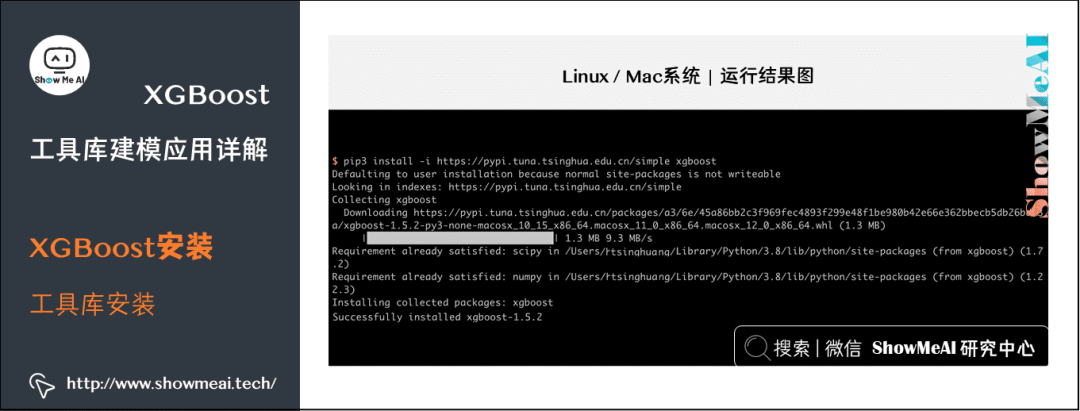
(2) Windows Systems
For Windows systems, a more efficient and convenient installation method is to download the corresponding version of the XGBoost installation package from the websitehttp://www.lfd.uci.edu/~gohlke/pythonlibs/ and then install it using the following command.
pip install xgboost‑1.5.1‑cp310‑cp310‑win32.whlReading Data with XGBoost
The first step in applying XGBoost is to load the required data into a format that the toolkit can support. XGBoost can load data in various formats for training modeling:
- Text data in libsvm format.
- Two-dimensional arrays of Numpy.
- XGBoost’s binary cache files. The loaded data is stored in an object called DMatrix.
The SKLearn interface of XGBoost also supports DataFrame formatted data (refer to ShowMeAI’s article on Python Data Analysis | Core Functions of Pandas [3] for processing).Below are the loading methods for different data formats in XGBoost.
- Loading data in libsvm format
dtrain1 = xgb.DMatrix('train.svm.txt')- Loading binary cache files
dtrain2 = xgb.DMatrix('train.svm.buffer')- Loading numpy arrays
data = np.random.rand(5,10) # 5 entities, each contains 10 features
label = np.random.randint(2, size=5) # binary target
dtrain = xgb.DMatrix( data, label=label)- Converting
<strong>scipy.sparse</strong>format data to<strong>DMatrix</strong>format
csr = scipy.sparse.csr_matrix( (dat, (row,col)) )
dtrain = xgb.DMatrix( csr ) - Saving
<strong>DMatrix</strong>formatted data as XGBoost binary format to improve loading speed next time, as follows:
dtrain = xgb.DMatrix('train.svm.txt')
dtrain.save_binary("train.buffer")- Handling missing values in
<strong>DMatrix</strong>as follows:
dtrain = xgb.DMatrix( data, label=label, missing = -999.0)- When setting sample weights, you can do it as follows:
w = np.random.rand(5,1)
dtrain = xgb.DMatrix( data, label=label, missing = -999.0, weight=w)Different Modeling Methods of XGBoost
Built-in Modeling Method: libsvm Data Source
XGBoost has built-in modeling methods with the following data formats and core training methods:
- Data based on DMatrix format
- Training based on xgb.train interface
Below is a simple official example demonstrating the process of reading libsvm format data (into DMatrix format) and specifying parameters for modeling.
# Import toolkit
import numpy as np
import scipy.sparse
import pickle
import xgboost as xgb
# Read data from libsvm file for binary classification
# The data is in libsvm format, as shown below:
#1 3:1 10:1 11:1 21:1 30:1 34:1 36:1 40:1 41:1 53:1 58:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 105:1 117:1 124:1
#0 3:1 10:1 20:1 21:1 23:1 34:1 36:1 39:1 41:1 53:1 56:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 106:1 116:1 120:1
#0 1:1 10:1 19:1 21:1 24:1 34:1 36:1 39:1 42:1 53:1 56:1 65:1 69:1 77:1 86:1 88:1 92:1 95:1 102:1 106:1 116:1 122:1
dtrain = xgb.DMatrix('./data/agaricus.txt.train')
dtest = xgb.DMatrix('./data/agaricus.txt.test')
# Hyperparameter settings
# Mainly tree depth, learning rate, objective function
param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic' }
# Set watchlist to observe model status during training
watchlist = [(dtest,'eval'), (dtrain,'train')]
num_round = 2
bst = xgb.train(param, dtrain, num_round, watchlist)
# Use the model for prediction
preds = bst.predict(dtest)
# Check accuracy
labels = dtest.get_label()
print('Error rate: %f' %
(sum(1 for i in range(len(preds)) if int(preds[i]>0.5)!=labels[i]) /float(len(preds))))
# Save the model
bst.save_model('./model/0001.model')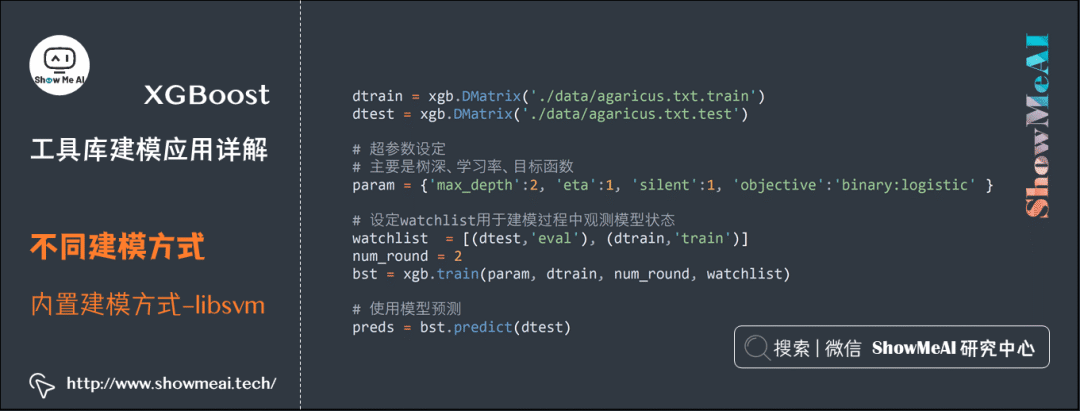
[0] eval-error:0.042831 train-error:0.046522
[1] eval-error:0.021726 train-error:0.022263
Error rate: 0.021726Built-in Modeling Method: CSV Data Source
In the following example, the input data source is a CSV file. We use the familiar Pandas toolkit (refer to ShowMeAI tutorials on Data Analysis Series [4] and Data Science Tools Quick Reference | Pandas User Guide [5]) to read the data into DataFrame format, then construct DMatrix format input, and subsequently train using the built-in modeling method.
# Pima Indian Diabetes dataset contains many fields: Number of Pregnancies, Plasma Glucose Concentration in Oral Glucose Tolerance Test, Diastolic Blood Pressure (mm Hg), Thickness of Triceps Skin Fold (mm),
# 2-hour Serum Insulin (μU/ml), Body Mass Index (kg/(height(m)^2)), Diabetes Pedigree Function, Age (years)
import pandas as pd
data = pd.read_csv('./data/Pima-Indians-Diabetes.csv')
data.head()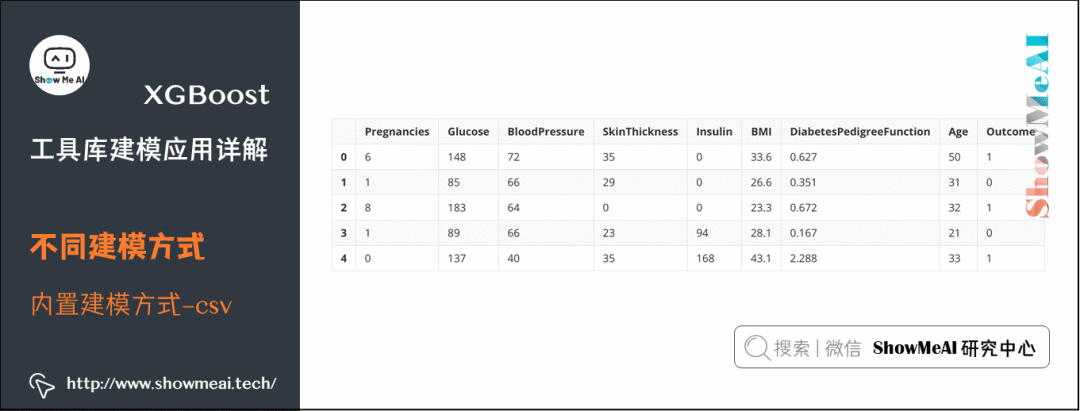
# Import toolkit
import numpy as np
import pandas as pd
import pickle
import xgboost as xgb
from sklearn.model_selection import train_test_split
# Read data with pandas
data = pd.read_csv('./data/Pima-Indians-Diabetes.csv')
# Split the data
train, test = train_test_split(data)
# Convert to DMatrix format
feature_columns = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age']
target_column = 'Outcome'
# Extract numpy array values from DataFrame to initialize DMatrix object
xgtrain = xgb.DMatrix(train[feature_columns].values, train[target_column].values)
xgtest = xgb.DMatrix(test[feature_columns].values, test[target_column].values)
# Parameter settings
param = {'max_depth':5, 'eta':0.1, 'silent':1, 'subsample':0.7, 'colsample_bytree':0.7, 'objective':'binary:logistic' }
# Set watchlist to observe model status
watchlist = [(xgtest,'eval'), (xgtrain,'train')]
num_round = 10
bst = xgb.train(param, xgtrain, num_round, watchlist)
# Use the model for prediction
preds = bst.predict(xgtest)
# Check accuracy
labels = xgtest.get_label()
print('Error rate: %f' %
(sum(1 for i in range(len(preds)) if int(preds[i]>0.5)!=labels[i]) /float(len(preds))))
# Save the model
bst.save_model('./model/0002.model')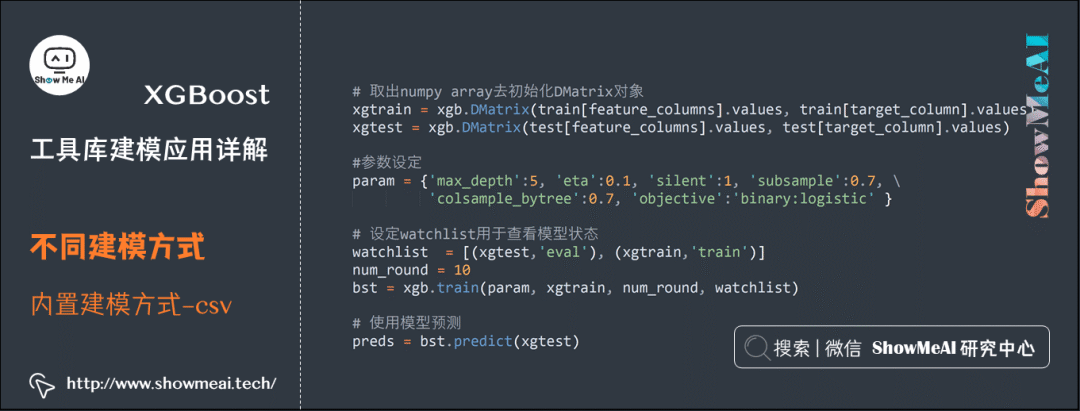
[0] eval-error:0.354167 train-error:0.194444
[1] eval-error:0.34375 train-error:0.170139
[2] eval-error:0.322917 train-error:0.170139
[3] eval-error:0.28125 train-error:0.161458
[4] eval-error:0.302083 train-error:0.147569
Error rate: 0.291667Estimator Modeling Method: SKLearn Interface + DataFrame
XGBoost also supports modeling using the unified estimator interface in SKLearn. Below is a typical reference case for training with a DataFrame formatted training and testing set, where you can directly use XGBoost to initialize XGBClassifier for fitting. The usage method and interface are consistent with other estimators in SKLearn.
# Import toolkit
import numpy as np
import pandas as pd
import pickle
import xgboost as xgb
from sklearn.model_selection import train_test_split
# Read data with pandas
data = pd.read_csv('./data/Pima-Indians-Diabetes.csv')
# Split the data
train, test = train_test_split(data)
# Feature columns
feature_columns = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age']
# Target column
target_column = 'Outcome'
# Initialize model
xgb_classifier = xgb.XGBClassifier(n_estimators=20,\
max_depth=4, \
learning_rate=0.1, \
subsample=0.7, \
colsample_bytree=0.7, \
eval_metric='error')
# Fit model with DataFrame formatted data
xgb_classifier.fit(train[feature_columns], train[target_column])
# Use the model for prediction
preds = xgb_classifier.predict(test[feature_columns])
# Check accuracy
print('Error rate: %f' %((preds!=test[target_column]).sum()/float(test_y.shape[0])))
# Save the model
joblib.dump(xgb_classifier, './model/0003.model')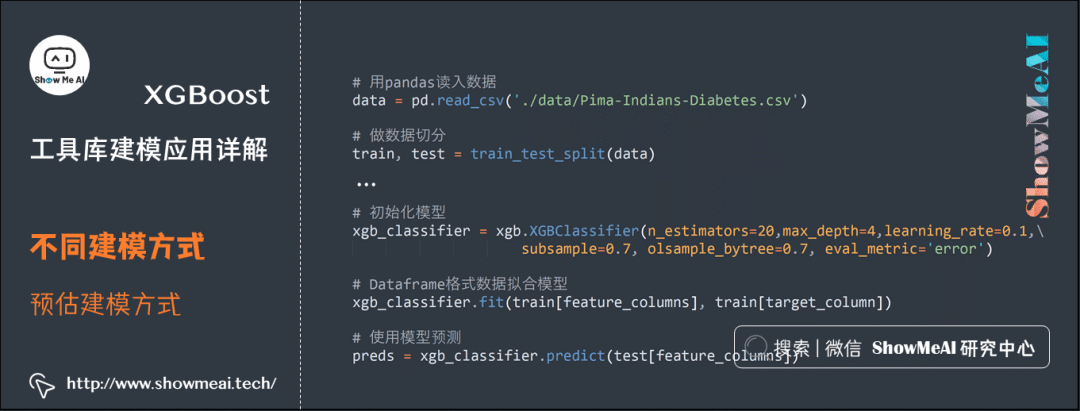
Error rate: 0.265625
['./model/0003.model']Tuning Parameters and Advanced Features
XGBoost Parameter Details
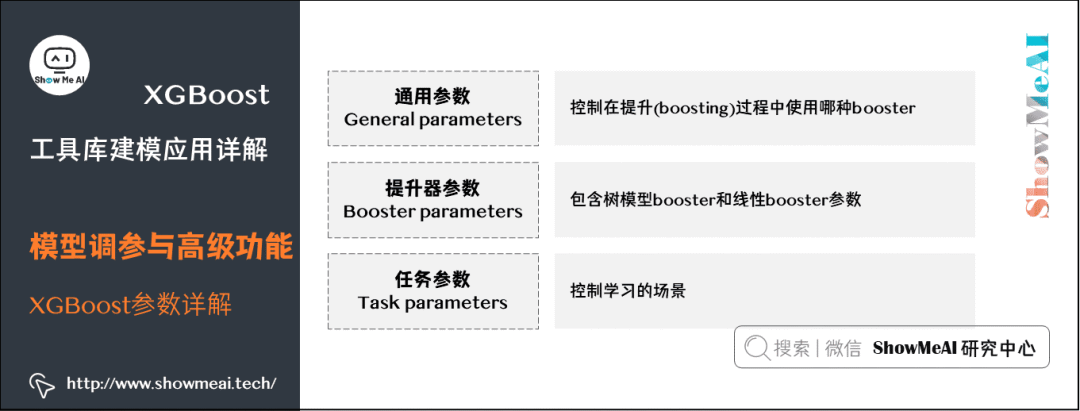
Before running XGBoost, three types of parameters must be set: General parameters, Booster parameters, and Task parameters:
General parameters:
These parameters control which booster is used in the boosting process. Common boosters include tree models (tree) and linear models (linear model).
Booster parameters:
These depend on which booster is used and include parameters for tree model boosters and linear boosters.
Task parameters:
These control the learning scenario, for example, different parameters are used for regression problems.
(1) General Parameters

booster [default=gbtree]
There are two models to choose from: gbtree and gblinear. gbtree uses tree-based models for boosting calculations, while gblinear uses linear models for boosting calculations. The default value is gbtree.
silent [default=0]
When set to 1, it indicates that runtime information will be printed; when set to 0, it indicates that it will run silently without printing runtime information. The default value is 0.
nthread
The number of threads used during XGBoost runtime. The default value is the maximum number of threads available on the current system.
num_pbuffer
The size of the prediction buffer, usually set to the number of training instances. The buffer is used to save the predictions from the last boosting step, and does not need to be set manually.
num_feature
The number of features used during boosting; this is set to the number of features. XGBoost will set this automatically, and it does not need to be set manually.
(2) Tree Model Booster Parameters

eta [default=0.3]
To prevent overfitting, this is the shrinkage step used during the update process. After each boosting calculation, the algorithm directly obtains the weights of the new features.eta makes the boosting calculation process more conservative by reducing the weights of features. The default value is 0.3, and the value range is (0, 1).
gamma [default=0]
The minimum loss reduction required for a tree to further split and grow. The larger the value, the more conservative the algorithm will be. The value range is (0, ∞).
max_depth [default=6]
The maximum depth of the tree. The default value is 6, and the value range is (0, ∞).
min_child_weight [default=1]
The minimum sum of sample weights in a child node. If the sum of sample weights in a leaf node is less than min_child_weight, the splitting process ends.In regression models, this parameter refers to the minimum number of samples required to build each model. The larger this value, the more conservative the algorithm will be. The value range is (0, ∞).
max_delta_step [default=0]
The maximum weight estimation allowed for each tree. If set to 0, it means no constraints; if set to a positive value, it will make the update steps more conservative.This parameter is usually not necessary, but it can help in cases of extreme imbalance in logistic regression. Setting this value between 1-10 may control the updates. The value range is (0, ∞).
subsample [default=1]
The proportion of the subsample used for training the model from the entire sample set. If set to 1, it means that XGBoost will randomly sample 100% of the entire sample set to build the tree model, which can prevent overfitting. The value range is (0, 1).
colsample_bytree [default=1]
The proportion of features sampled when building the tree. The default value is 1, and the value range is (0, 1).
(3) Linear Booster Parameters

lambda [default=0]
L2 regularization penalty coefficient.
alpha [default=0]
L1 regularization penalty coefficient.
lambda_bias
L2 regularization on bias. The default value is 0 (no bias term regularization for L1 since it is not important for L1).
(4) Task Parameters

objective [ default=reg:linear ]
Defines the learning task and the corresponding learning objective.
Optional objective functions include:
-
reg:linear: Linear regression.
-
reg:logistic: Logistic regression.
-
binary:logistic: Binary classification logistic regression problem, output as probability.
-
binary:logitraw: Binary classification logistic regression problem, output results as wTx.
-
count:poisson: Poisson regression for count problems, output results as Poisson distribution. In Poisson regression, the default value for max_delta_step is 0.7 (used to safeguard optimization).
-
multi:softmax: Makes XGBoost use the softmax objective function to handle multi-class problems, while requiring the parameter num_class (number of classes) to be set.
-
multi:softprob: Similar to softmax, but outputs a vector of ndata * nclass, which can be reshaped into a matrix of ndata rows and nclass columns. Each row of data represents the probability of the sample belonging to each class.
-
rank:pairwise: Sets XGBoost to perform ranking tasks by minimizing pairwise loss.
base_score [ default=0.5 ]
-
Initial prediction score for all instances, global bias;
-
Changing this value will not have a significant impact on the number of iterations required.
eval_metric [ default according to objective ]
Evaluation metrics required for validation data. Different objective functions will have default evaluation metrics (rmse for regression, and error for classification, mean average precision for ranking).
Users can add multiple evaluation metrics, and for Python users, parameters should be passed as a list to the program, rather than as a map parameter. List parameters will not overwrite eval_metric.
Available options include:
-
rmse: Root mean square error
-
logloss: Negative log-likelihood
-
error: Binary classification error rate. It is calculated as #(wrong cases)/#(all cases). For the predictions, the evaluation will regard instances with prediction values larger than 0.5 as positive instances, and others as negative instances.
-
merror: Multiclass classification error rate. It is calculated as #(wrong cases)/#(all cases).
-
mlogloss: Multiclass logloss
-
auc: Area under the curve for ranking evaluation.
-
ndcg: Normalized Discounted Cumulative Gain
-
map: Mean average precision
-
ndcg@n, map@n: n can be assigned as an integer to cut off the top positions in the lists for evaluation.
-
ndcg-, map-, ndcg@n-, map@n-: In XGBoost, NDCG and MAP will evaluate the score of a list without any positive samples as 1. By adding – in the evaluation metric, XGBoost will evaluate these scores as 0 to be consistent under some conditions.
seed [ default=0 ]
Random seed. The default value is 0.
Built-in Parameter Optimization
(1) Cross-Validation
XGBoost comes with some methods for experimentation and parameter tuning, as follows for the cross-validation method xgb.cv.
xgb.cv(param, dtrain, num_round, nfold=5, metrics={'error'}, seed = 0)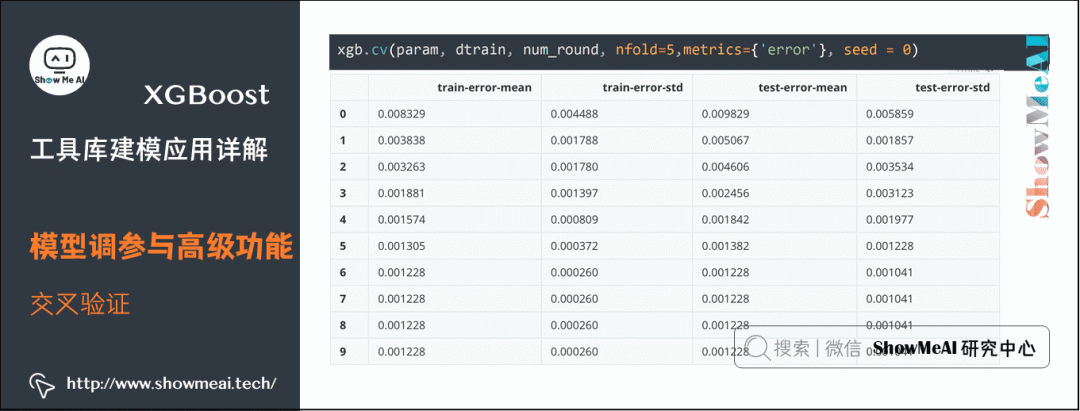
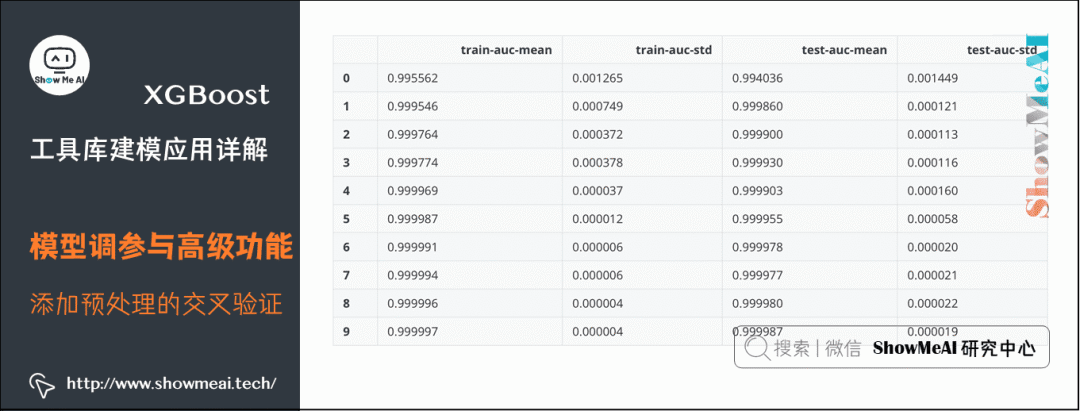
(2) Adding Preprocessing
We can add some settings during the data modeling process into the cross-validation phase. For example, for weighting different categories of samples, refer to the code example below:
# Calculate the ratio of positive to negative samples, adjust sample weights
def fpreproc(dtrain, dtest, param):
label = dtrain.get_label()
ratio = float(np.sum(label == 0)) / np.sum(label==1)
param['scale_pos_weight'] = ratio
return (dtrain, dtest, param)
# First do preprocessing, calculate sample weights, then do cross-validation
xgb.cv(param, dtrain, num_round, nfold=5,
metrics={'auc'}, seed = 0, fpreproc = fpreproc)
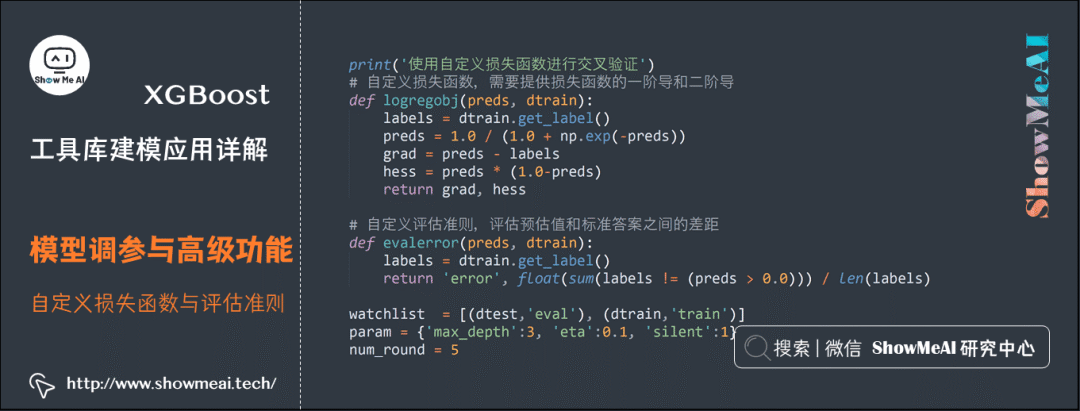
(3) Custom Loss Functions and Evaluation Criteria
XGBoost supports custom loss functions and evaluation criteria during the training process, where the loss function definition needs to return the first and second derivatives of the loss function, and the evaluation criterion needs to compute the difference between the data labels and predicted values. The loss function is used for tree structure learning during training, while the evaluation criterion is often used for effect evaluation on the validation set.
print('Using custom loss function for cross-validation')
# Custom loss function, need to provide the first and second derivatives of the loss function
def logregobj(preds, dtrain):
labels = dtrain.get_label()
preds = 1.0 / (1.0 + np.exp(-preds))
grad = preds - labels
hess = preds * (1.0-preds)
return grad, hess
# Custom evaluation criterion to evaluate the gap between predicted values and true labels
def evalerror(preds, dtrain):
labels = dtrain.get_label()
return 'error', float(sum(labels != (preds > 0.0))) / len(labels)
watchlist = [(dtest,'eval'), (dtrain,'train')]
param = {'max_depth':3, 'eta':0.1, 'silent':1}
num_round = 5
# Training with custom loss function
bst = xgb.train(param, dtrain, num_round, watchlist, logregobj, evalerror)
# Cross-validation
xgb.cv(param, dtrain, num_round, nfold = 5, seed = 0, obj = logregobj, feval=evalerror)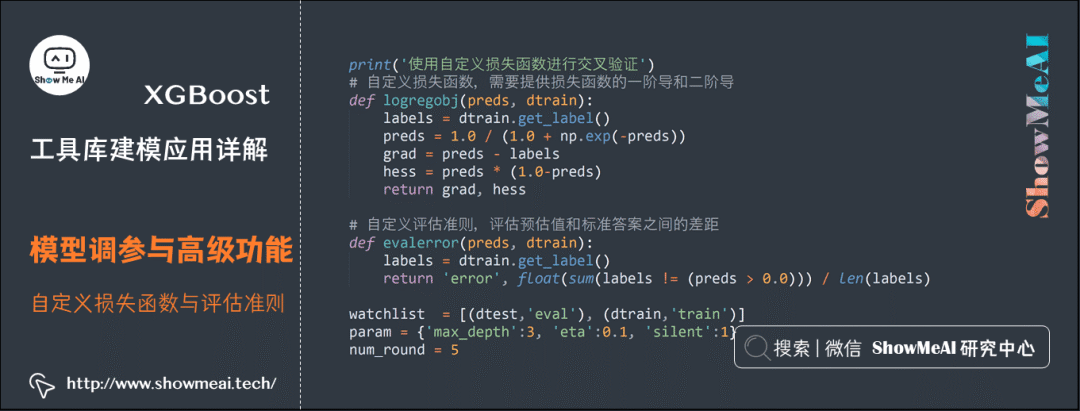
Using custom loss function for cross-validation
[0] eval-rmse:0.306901 train-rmse:0.306164 eval-error:0.518312 train-error:0.517887
[1] eval-rmse:0.179189 train-rmse:0.177278 eval-error:0.518312 train-error:0.517887
[2] eval-rmse:0.172565 train-rmse:0.171728 eval-error:0.016139 train-error:0.014433
[3] eval-rmse:0.269612 train-rmse:0.27111 eval-error:0.016139 train-error:0.014433
[4] eval-rmse:0.396903 train-rmse:0.398256 eval-error:0.016139 train-error:0.014433(4) Using Only the First n Trees for Prediction
For boosting models, many base learners (in XGBoost, this is often many trees) will be trained. You can train completely once and use only the ensemble of the first n trees for prediction.
#!/usr/bin/python
import numpy as np
import pandas as pd
import pickle
import xgboost as xgb
from sklearn.model_selection import train_test_split
# Basic example, read data from a CSV file, perform binary classification
# Read data with pandas
data = pd.read_csv('./data/Pima-Indians-Diabetes.csv')
# Split the data
train, test = train_test_split(data)
# Convert to DMatrix format
feature_columns = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age']
target_column = 'Outcome'
xgtrain = xgb.DMatrix(train[feature_columns].values, train[target_column].values)
xgtest = xgb.DMatrix(test[feature_columns].values, test[target_column].values)
# Parameter settings
param = {'max_depth':5, 'eta':0.1, 'silent':1, 'subsample':0.7, 'colsample_bytree':0.7, 'objective':'binary:logistic' }
# Set watchlist to observe model status
watchlist = [(xgtest,'eval'), (xgtrain,'train')]
num_round = 10
bst = xgb.train(param, xgtrain, num_round, watchlist)
# Use the first tree for prediction
ypred1 = bst.predict(xgtest, ntree_limit=1)
# Use the first 9 trees for prediction
ypred2 = bst.predict(xgtest, ntree_limit=9)
label = xgtest.get_label()
print('Error rate using the first tree: %f' % (np.sum((ypred1>0.5)!=label) /float(len(label))))
print('Error rate using the first 9 trees: %f' % (np.sum((ypred2>0.5)!=label) /float(len(label))))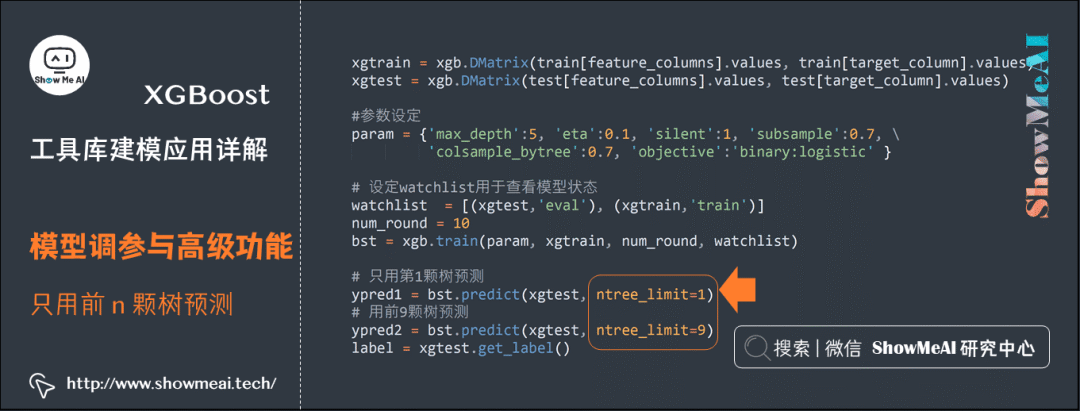
[0] eval-error:0.255208 train-error:0.196181
[1] eval-error:0.234375 train-error:0.175347
[2] eval-error:0.25 train-error:0.163194
[3] eval-error:0.229167 train-error:0.149306
[4] eval-error:0.213542 train-error:0.154514
Error rate using the first tree: 0.255208
Error rate using the first 9 trees: 0.187500Estimator Tuning Optimization
(1) SKLearn Estimator Interface Experiment Evaluation
XGBoost has a SKLearn estimator interface, and the overall usage method is consistent with other estimators in SKLearn. Below is a manual cross-validation on the data, noting that we directly use XGBClassifier to fit and evaluate the DataFrame data.
import pickle
import xgboost as xgb
import numpy as np
from sklearn.model_selection import KFold, train_test_split, GridSearchCV
from sklearn.metrics import confusion_matrix, mean_squared_error
from sklearn.datasets import load_iris, load_digits, load_boston
rng = np.random.RandomState(31337)
# Binary classification: confusion matrix
print("Binary classification problem for digits 0 and 1")
digits = load_digits(2)
y = digits['target']
X = digits['data']
# Data splitting object
kf = KFold(n_splits=2, shuffle=True, random_state=rng)
print("Cross-validation on 2 folds")
# 2-fold cross-validation
for train_index, test_index in kf.split(X):
xgb_model = xgb.XGBClassifier().fit(X[train_index],y[train_index])
predictions = xgb_model.predict(X[test_index])
actuals = y[test_index]
print("Confusion matrix:")
print(confusion_matrix(actuals, predictions))
# Multiclass: confusion matrix
print("\nIris: Multiclass")
iris = load_iris()
y = iris['target']
X = iris['data']
kf = KFold(n_splits=2, shuffle=True, random_state=rng)
print("Cross-validation on 2 folds")
for train_index, test_index in kf.split(X):
xgb_model = xgb.XGBClassifier().fit(X[train_index],y[train_index])
predictions = xgb_model.predict(X[test_index])
actuals = y[test_index]
print("Confusion matrix:")
print(confusion_matrix(actuals, predictions))
# Regression problem: MSE
print("\nBoston Housing Price Regression Prediction Problem")
boston = load_boston()
y = boston['target']
X = boston['data']
kf = KFold(n_splits=2, shuffle=True, random_state=rng)
print("Cross-validation on 2 folds")
for train_index, test_index in kf.split(X):
xgb_model = xgb.XGBRegressor().fit(X[train_index],y[train_index])
predictions = xgb_model.predict(X[test_index])
actuals = y[test_index]
print("MSE:",mean_squared_error(actuals, predictions))Binary classification problem for digits 0 and 1
Cross-validation on 2 folds
Confusion matrix:
[[87 0]
[ 1 92]]
Confusion matrix:
[[91 0]
[ 3 86]]
Iris: Multiclass
Cross-validation on 2 folds
Confusion matrix:
[[19 0 0]
[ 0 31 3]
[ 0 1 21]]
Confusion matrix:
[[31 0 0]
[ 0 16 0]
[ 0 3 25]]
Boston Housing Price Regression Prediction Problem
Cross-validation on 2 folds
MSE: 9.860776812557337
MSE: 15.942418468446029(2) Grid Search Parameter Tuning
As mentioned, XGBoost’s estimator interface has a consistent usage method with other estimators in SKLearn, so we can also use hyperparameter tuning methods in SKLearn for model tuning.Below is a typical grid search tuning example, where we provide a candidate parameter list dictionary and use GridSearchCV for cross-validation experiment evaluation to find the optimal hyperparameters for XGBoost among the candidate parameters.
print("Parameter Optimization:")
y = boston['target']
X = boston['data']
xgb_model = xgb.XGBRegressor()
clf = GridSearchCV(xgb_model,
{'max_depth': [2,4,6],
'n_estimators': [50,100,200]}, verbose=1)
clf.fit(X,y)
print(clf.best_score_)
print(clf.best_params_)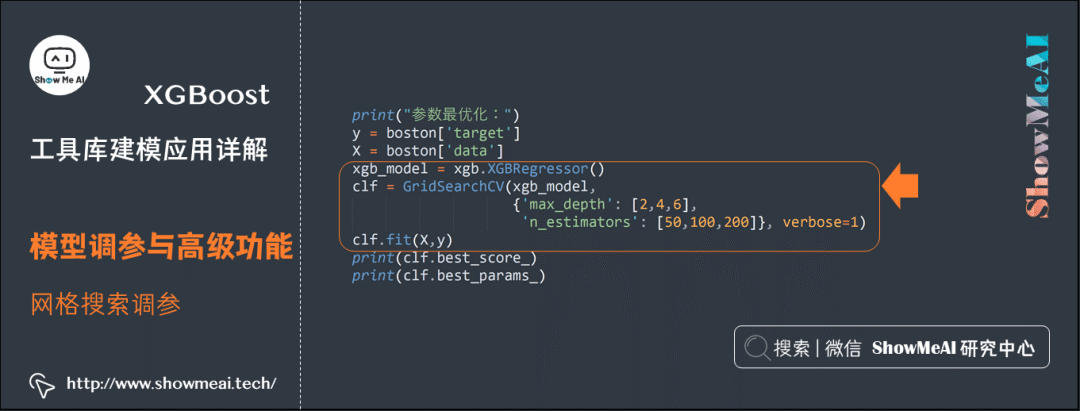
Parameter Optimization:
Fitting 3 folds for each of 9 candidates, totalling 27 fits
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
0.6001029721598573
{'max_depth': 4, 'n_estimators': 100}
[Parallel(n_jobs=1)]: Done 27 out of 27 | elapsed: 1.3s finished(3) Early Stopping
The XGBoost model can sometimes overfit the training set by continuously adding new trees (correcting some samples that are not fitted correctly on the training set). Early stopping is an effective strategy; the specific approach is to monitor the performance on the validation set while continuously adding trees to the training set. If the evaluation criterion does not improve after a certain number of rounds, it will revert to the best point in history on the validation set and save it as the best model.Below is the corresponding code example, where the parameter early_stopping_rounds specifies the maximum number of rounds without improvement acceptable on the validation set, and eval_set specifies the validation dataset.
# Learn the model on the training set, adding one tree at a time, and check the effect on the validation set. When the validation set effect no longer improves, stop adding and growing trees
X = digits['data']
y = digits['target']
X_train, X_val, y_train, y_val = train_test_split(X, y, random_state=0)
clf = xgb.XGBClassifier()
clf.fit(X_train, y_train, early_stopping_rounds=10, eval_metric="auc",
eval_set=[(X_val, y_val)])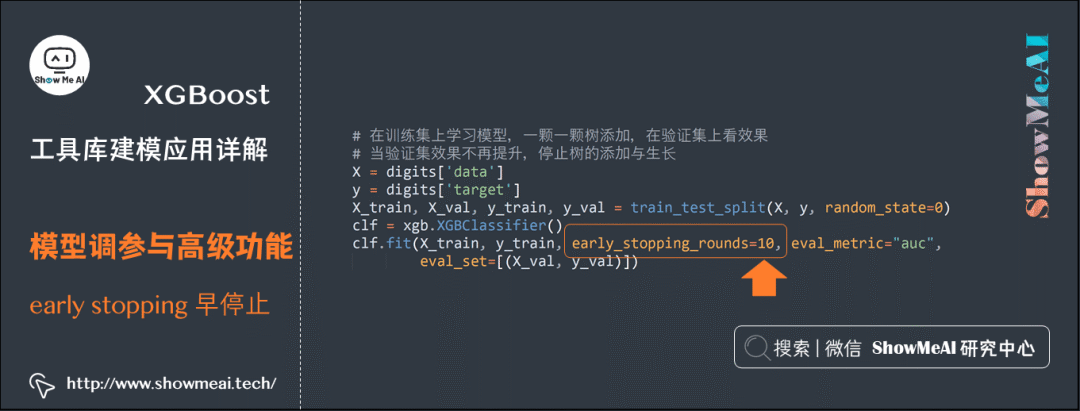
[0] validation_0-auc:0.999497
Will train until validation_0-auc hasn't improved in 10 rounds.
[1] validation_0-auc:0.999497
[2] validation_0-auc:0.999497
[3] validation_0-auc:0.999749
[4] validation_0-auc:0.999749
[5] validation_0-auc:0.999749
[6] validation_0-auc:0.999749
[7] validation_0-auc:0.999749
[8] validation_0-auc:0.999749
[9] validation_0-auc:0.999749
[10] validation_0-auc:1
[11] validation_0-auc:1
[12] validation_0-auc:1
[13] validation_0-auc:1
[14] validation_0-auc:1
[15] validation_0-auc:1
[16] validation_0-auc:1
[17] validation_0-auc:1
[18] validation_0-auc:1
[19] validation_0-auc:1
[20] validation_0-auc:1
Stopping. Best iteration:
[10] validation_0-auc:1(4) Feature Importance
During the modeling process, XGBoost can also learn the corresponding feature importance information, which can be saved in the model’s feature_importances_ attribute. Below is the visualization code for plotting feature importance:
iris = load_iris()
y = iris['target']
X = iris['data']
xgb_model = xgb.XGBClassifier().fit(X,y)
print('Feature ranking:')
feature_names=['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
feature_importances = xgb_model.feature_importances_
indices = np.argsort(feature_importances)[::-1]
for index in indices:
print("Feature %s importance: %f" %(feature_names[index], feature_importances[index]))
%matplotlib inline
import matplotlib.pyplot as plt
plt.figure(figsize=(16,8))
plt.title("Feature Importances")
plt.bar(range(len(feature_importances)), feature_importances[indices], color='b')
plt.xticks(range(len(feature_importances)), np.array(feature_names)[indices], color='b')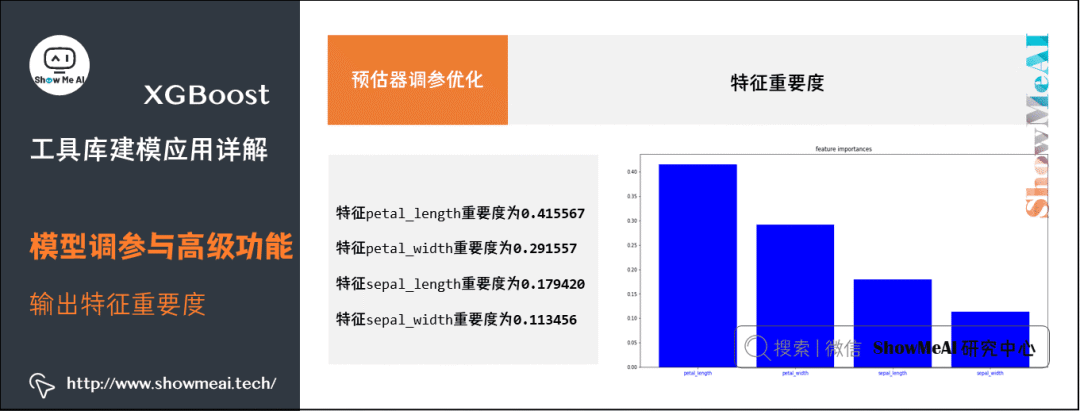
Feature ranking:
Feature petal_length importance: 0.415567
Feature petal_width importance: 0.291557
Feature sepal_length importance: 0.179420
Feature sepal_width importance: 0.113456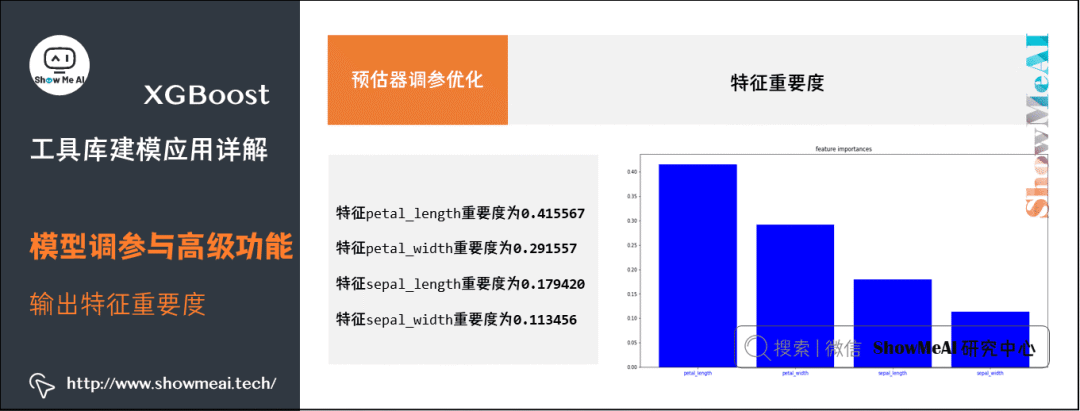
(5) Parallel Training Acceleration
In multi-resource scenarios, XGBoost can achieve parallel training acceleration. The example code is as follows:
import os
if __name__ == "__main__":
try:
from multiprocessing import set_start_method
except ImportError:
raise ImportError("Unable to import multiprocessing.set_start_method."
" This example only runs on Python 3.4")
#set_start_method("forkserver")
import numpy as np
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import load_boston
import xgboost as xgb
rng = np.random.RandomState(31337)
print("Parallel Parameter optimization")
boston = load_boston()
os.environ["OMP_NUM_THREADS"] = "2" # or to whatever you want
y = boston['target']
X = boston['data']
xgb_model = xgb.XGBRegressor()
clf = GridSearchCV(xgb_model, {'max_depth': [2, 4, 6],
'n_estimators': [50, 100, 200]}, verbose=1,
n_jobs=2)
clf.fit(X, y)
print(clf.best_score_)
print(clf.best_params_)Parallel Parameter optimization
Fitting 3 folds for each of 9 candidates, totalling 27 fits
[Parallel(n_jobs=2)]: Using backend LokyBackend with 2 concurrent workers.
[Parallel(n_jobs=2)]: Done 24 out of 27 | elapsed: 2.2s remaining: 0.3s
0.6001029721598573
{'max_depth': 4, 'n_estimators': 100}
[Parallel(n_jobs=2)]: Done 27 out of 27 | elapsed: 2.4s finishedReferences
[1] Illustrated Machine Learning | Detailed Explanation of XGBoost Model: https://www.showmeai.tech/article-detail/194[2] Illustrated Python | Installation and Environment Setup: https://www.showmeai.tech/article-detail/65[3] Python Data Analysis | Core Functions of Pandas: https://www.showmeai.tech/article-detail/146[4] Data Analysis Series Tutorials: https://www.showmeai.tech/tutorials/33[5] Quick Reference for Data Science Tools | Pandas User Guide: https://www.showmeai.tech/article-detail/101Recommended Reading1. Pandas 100 Tricks2. Pandas Data Cleaning3. Original Series on Machine Learning