1 Algorithm Introduction
XGBoost (eXtreme Gradient Boosting) is an algorithm based on GBDT, which is an ensemble machine learning algorithm based on decision trees, using Gradient Boosting as its framework. In 2016, Tianqi Chen formally proposed the XGBoost algorithm in his paper “XGBoost: A Scalable Tree Boosting System.” This algorithm efficiently implements GBDT and has made many improvements in both algorithm and engineering, being widely used in Kaggle competitions and many other machine learning competitions with great success.
Boosting is an iterative algorithm where each iteration weights the samples based on the predictions from the previous iteration. As the iterations progress, the errors decrease, thus continuously lowering the model’s bias. XGBoost is a Boosting algorithm.Gradient Boosting Decision Trees (GBDT) is an additive model based on the boosting ensemble idea, where a greedy learning approach is used during training with a forward distribution algorithm, learning a CART tree at each iteration to fit the residuals between the predictions of the previous t-1 trees and the true values of the training samples.
The basic idea of XGBoost is the same as that of GBDT, but it has made some optimizations, such as using second-order derivatives for a more precise loss function; regularization to avoid overfitting; and block storage for parallel computation. The following sections will provide a more detailed introduction to these optimization methods.
2 Algorithm Principles
XGBoost can use Regression Trees (CART) as base learners, or linear classifiers. When using CART as the base learner, its decision rules are the same as those of decision trees, but each leaf node in CART has a weight, which is the score or predicted value of the leaf node. An example of CART is shown below:
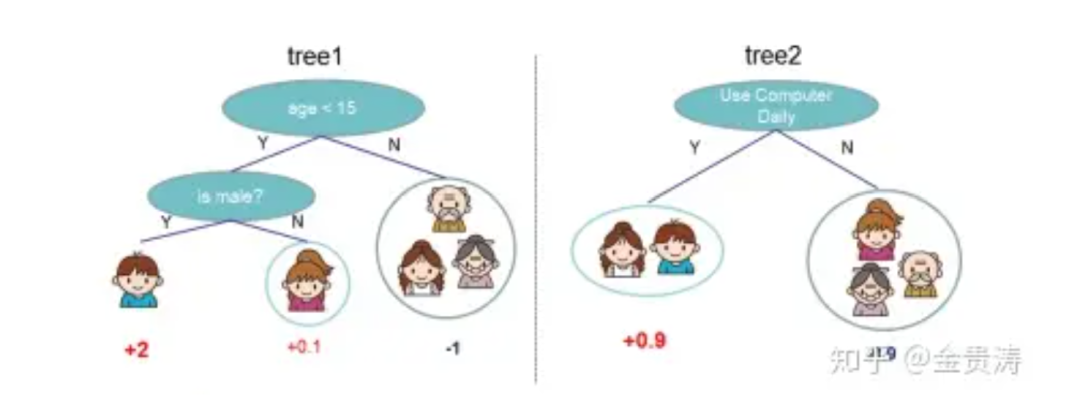
The image shows two regression trees (left and right), where the output values at the bottom of the trees are the weights (scores) of the leaf nodes. When predicting an output for a sample, the internal nodes’ decision conditions are used to partition the nodes, and the weight of the leaf node that the sample is finally assigned to is the predicted output value for that sample.
XGBoost is developed from GBDT, also utilizing the additive model and forward stepwise algorithm for learning optimization, but it differs from GBDT in several key aspects:
-
Objective Function: The loss function of XGBoost includes a regularization term to control the model’s complexity, which includes the number of leaf nodes and the sum of the squares of the weights of each leaf node.
-
Optimization Method: GBDT uses only first-order derivative information for optimization, while XGBoost uses both first and second-order derivative information.
-
Handling Missing Values: XGBoost has mechanisms to handle missing values by automatically selecting the optimal default splitting direction for them during the learning process.
-
Preventing Overfitting: In addition to adding regularization terms to prevent overfitting, XGBoost supports row and column sampling methods to further mitigate overfitting.
-
Results: It can achieve better results in the shortest time with fewer computational resources.
3 Algorithm Applications
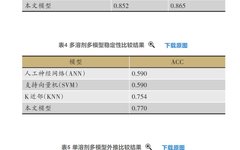
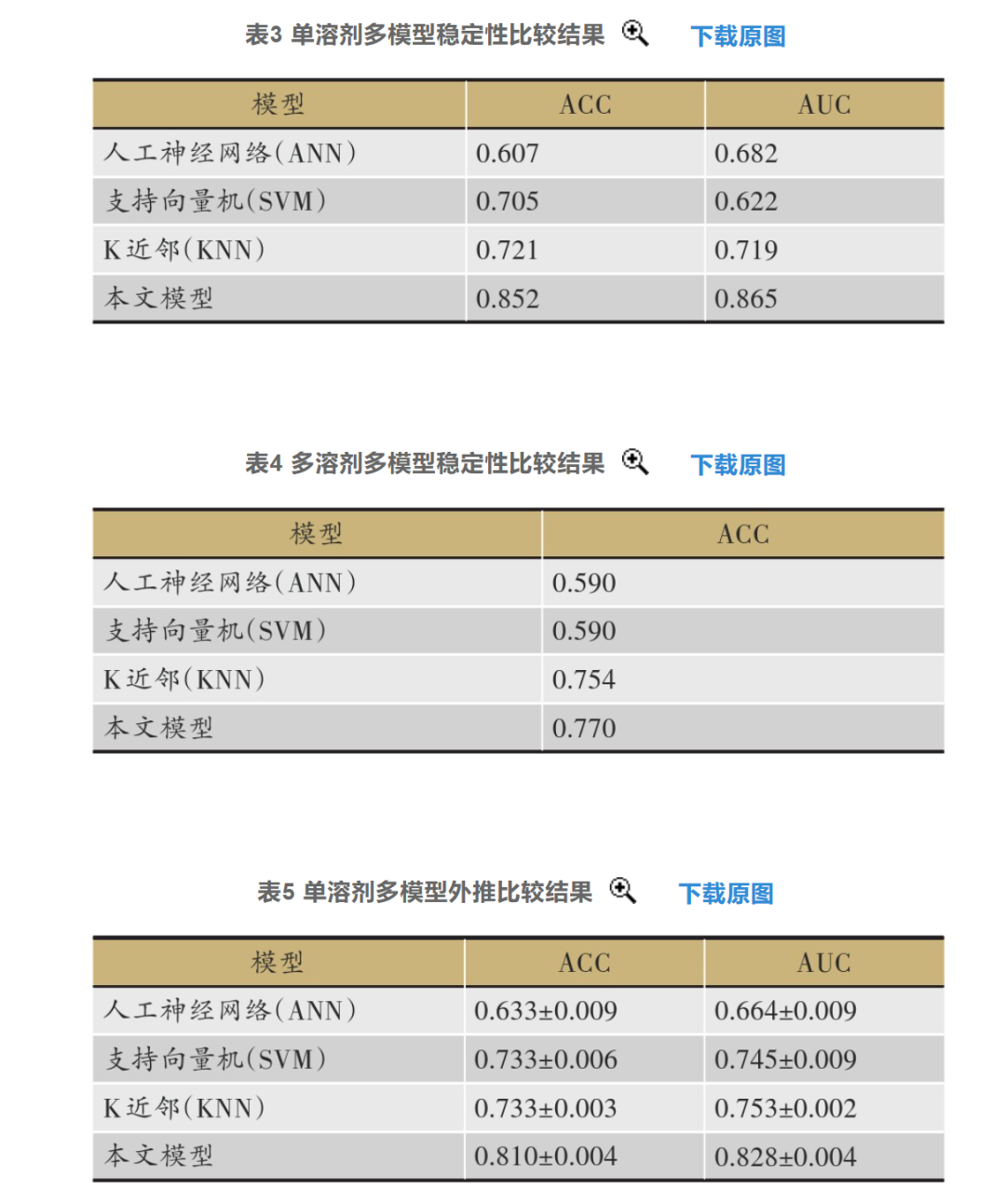
XGBoost is efficient, flexible, and lightweight, widely applied in data mining, recommendation systems, and other fields. In the field of traditional Chinese medicine, XGBoost plays an irreplaceable role. Unlike classic classification algorithms that use only the loss function in their objective functions, the objective function of the XGBoost algorithm consists of both a loss function and a model complexity component. Therefore, in the identification of cold and hot properties of traditional Chinese medicine and the visualization of cold and hot feature markers, researchers utilize the unique characteristics of XGBoost, combined with the typically small sample sizes of traditional Chinese medicine UV spectroscopy data, to construct models for recognizing the cold and hot properties of traditional Chinese medicine using the XGBoost algorithm from ensemble learning, evaluating the model’s performance through stability and extrapolation evaluations.
Most classic classification models tend to overfit when applied to UV spectroscopy data of traditional Chinese medicine. The higher the model’s complexity, the better it performs on the training set (lower bias), but the worse it performs on the test set (higher variance), leading to weaker generalization ability. The objective function of the XGBoost model is as follows, where the first part measures the size of the bias, with larger bias indicating poorer recognition performance; the second part measures the size of the variance, where higher model complexity leads to better fitting on the training set but significant performance differences on the test set. Therefore, to achieve overall optimality of the model, both bias and variance must be considered. The change in the objective function of the XGBoost algorithm makes the generated model less prone to overfitting and enhances its generalization ability, thus better adapting to the characteristics of traditional Chinese medicine UV spectroscopy data compared to other classic machine learning algorithms.

4 Conclusion
In the study of the thermal properties of medicinal substances, XGBoost can better adapt to the characteristics of traditional Chinese medicine UV spectroscopy data, showing significantly better stability and extrapolation performance than classic models. In other applications, XGBoost also demonstrates its strengths in high computational accuracy, speed, flexibility, ease of parameter tuning, and adaptability to various operating platforms, making it the ultimate evolution of the GBDT algorithm and tool.
No one is perfect, and neither is any algorithm. XGBoost still has disadvantages, such as sensitivity to noise and longer training times and higher resource consumption when dealing with large-scale data. However, overall, as a comprehensive algorithm, XGBoost remains an indelible favorite and rising star in various data competitions and applications.

[1] Zhihu Column. “[Easy to Understand] From Introduction to Practice of XGBoost, Very Detailed”. Seen on December 12, 2023.https://zhuanlan.zhihu.com/p/258564378.
[2] Zhihu Column. “Principles, Formula Derivation, Python Implementation, and Applications of XGBoost”. Seen on December 12, 2023.https://zhuanlan.zhihu.com/p/162001079.
[3] Zhihu Column. “Understanding XGBoost”. Seen on December 13, 2023. https://zhuanlan.zhihu.com/p/75217528.
[4] Zhihu Column. “Machine Learning – Ensemble Learning XGBoost”. Seen on December 14, 2023.https://zhuanlan.zhihu.com/p/607824746.
[5] Zhang Xike, Zhao Wenhua, Fu Xianjun et al. Identification of Cold and Hot Properties of Traditional Chinese Medicine Based on XGBoost and SHAP and Visualization Study of Cold and Hot Feature Marking [J]. World Science and Technology – Modernization of Traditional Chinese Medicine, 2022, 24(12):4984-4993.
Apriori Algorithm – “Truth” Lies in the Hands of the Majority
Conditional Random Fields (CRF) – An Indispensable “Tail” for Entity Recognition
BP Neural Network – An Iterative Network That Continuously Improves Itself

Ancient and Modern Medical Case Cloud Platform
Provides search services for over 500,000 ancient and modern medical cases
Supports manual, voice, OCR, and batch structured input of medical cases
Designed with nine analysis modules, closely aligning with clinical needs
Supports collaborative analysis of massive medical cases and personal cases
EDC Traditional Chinese Medicine Research Case Collection System
Supports multi-center, online random grouping, and data entry
SDV, audit trails, SMS reminders, data statistics
Analysis and other functions
Supports customized form design
Users can log in at: https://www.yiankb.com/edc
Free Trial!
Institute of Chinese Medical Sciences, Chinese Academy of Medical Sciences
Intelligent R&D Center for Traditional Chinese Medicine Health
Big Data R&D Department
Phone: 010-64089619
13522583261
QQ: 2778196938
https://www.yiankb.com