Source: Machine Heart Editorial Team
Why do tree-based machine learning methods, such as XGBoost and Random Forest, outperform deep learning on tabular data?This article provides the reasons behind this phenomenon. They selected 45 open datasets and defined a new benchmark to compare tree-based models and deep models, summarizing three reasons to explainthis phenomenon.
Deep learning has made significant advancements in fields like image, language, and even audio. However, it performs moderately when handling tabular data. Due to the characteristics of tabular data, such as uneven features, small sample sizes, and large outliers, it is challenging to find corresponding invariants.
Tree-based models are non-differentiable and cannot be jointly trained with deep learning modules, making the creation of tabular-specific deep learning architectures a very active area of research. Many studies claim to outperform or match tree-based models, but their research has faced much skepticism.
In fact, the learning of tabular data lacks established benchmarks, giving researchers a lot of freedom when evaluating their methods. Additionally, compared to benchmarks in other machine learning subdomains, most online available tabular datasets are small, making evaluation more challenging.
To alleviate these concerns, researchers from institutions such as the National Institute for Research in Computer Science and Automation and Sorbonne University proposed a benchmark for tabular data that can evaluate the latest deep learning models and indicate that tree-based models remain SOTA on medium-sized tabular datasets.
The article provides solid evidence for this conclusion, indicating that on tabular data, using tree-based methods is easier to achieve good predictions than deep learning (even modern architectures), and the researchers explored the reasons behind it.
Paper link: https://hal.archives-ouvertes.fr/hal-03723551/document
It is worth mentioning that one of the authors of the paper is Gaël Varoquaux, who is one of the leaders of the Scikit-learn project. Currently, this project has become one of the most popular machine learning libraries on GitHub. The article “Scikit-learn: Machine learning in Python,” co-authored by Gaël Varoquaux, has been cited 58,949 times.
The contributions of this article can be summarized as follows:
This research created a new benchmark for tabular data (selecting 45 open datasets) and shared these datasets through OpenML, making them easy to use.
This research compared deep learning models and tree-based models across various settings of tabular data, considering the cost of hyperparameter selection. It also shared the original results of random search, enabling researchers to cheaply test new algorithms for a fixed hyperparameter optimization budget.
Tree-based models still outperform deep learning methods on tabular data
The new benchmark references 45 tabular datasets, with the following criteria for selection:
-
Heterogeneous columns, where columns correspond to different types of features, thus excluding image or signal datasets.
-
Low dimensionality, with a dataset d/n ratio below 1/10.
-
Invalid datasets, removing datasets with little usable information.
-
I.I.D. (Independent and Identically Distributed) data, removing datasets like streams or time series.
-
Real-world data, deleting artificial datasets but retaining some simulated datasets.
-
Datasets must not be too small, removing those with too few features (< 4) and too few samples (< 3,000).
-
Removing overly simple datasets.
-
Removing datasets from games like poker and chess, as these datasets have deterministic goals.
Among tree-based models, the researchers selected 3 SOTA models: RandomForest from Scikit Learn, GradientBoostingTrees (GBTs), and XGBoost.
The study benchmarked the following deep models: MLP, Resnet, FT Transformer, SAINT.
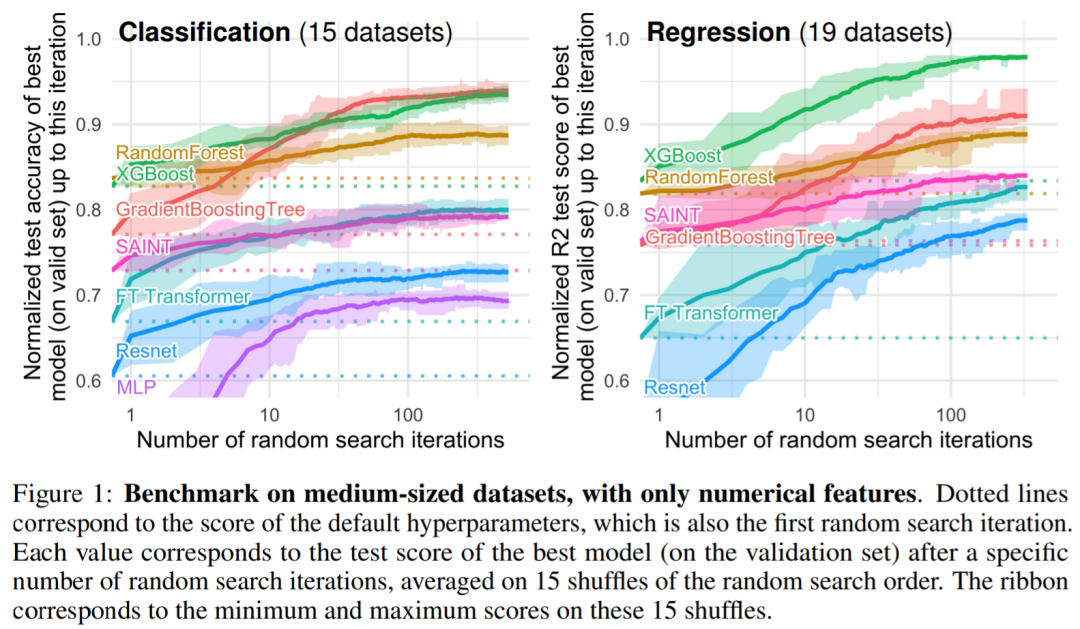
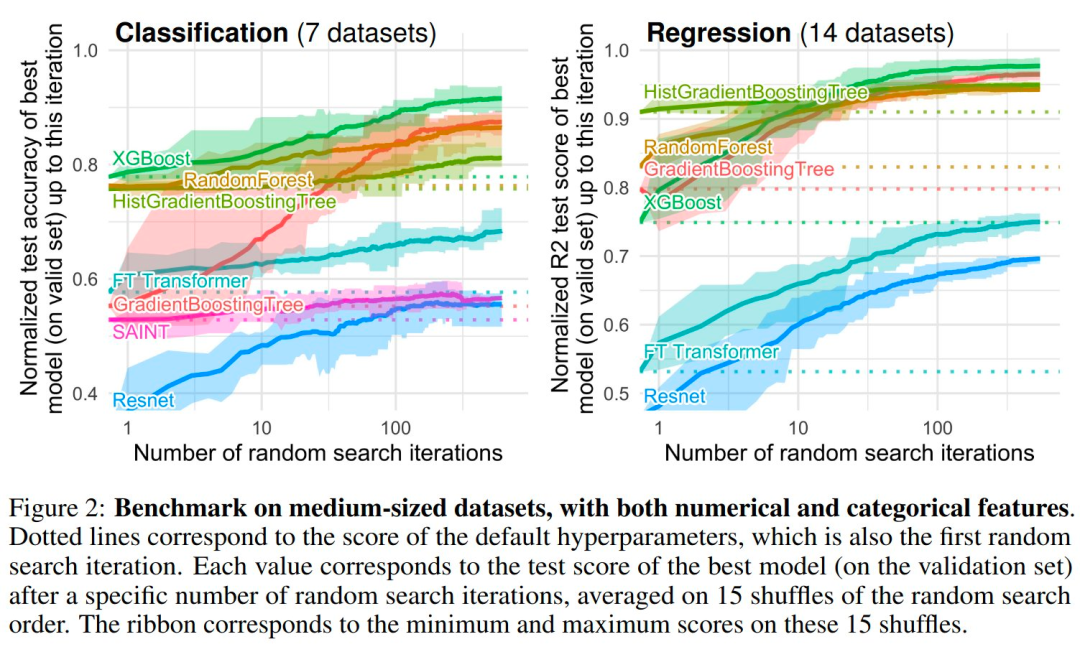
Figures 1 and 2 show the benchmarking results of different types of datasets.
Empirical Investigation: Why Tree-Based Models Still Outperform Deep Learning on Tabular Data
Inductive bias. Tree-based models outperform neural networks across various hyperparameter selections. In fact, the best methods for handling tabular data share two common properties: they are ensemble methods, either bagging (Random Forest) or boosting (XGBoost, GBT), and the weak learners used in these methods are decision trees.
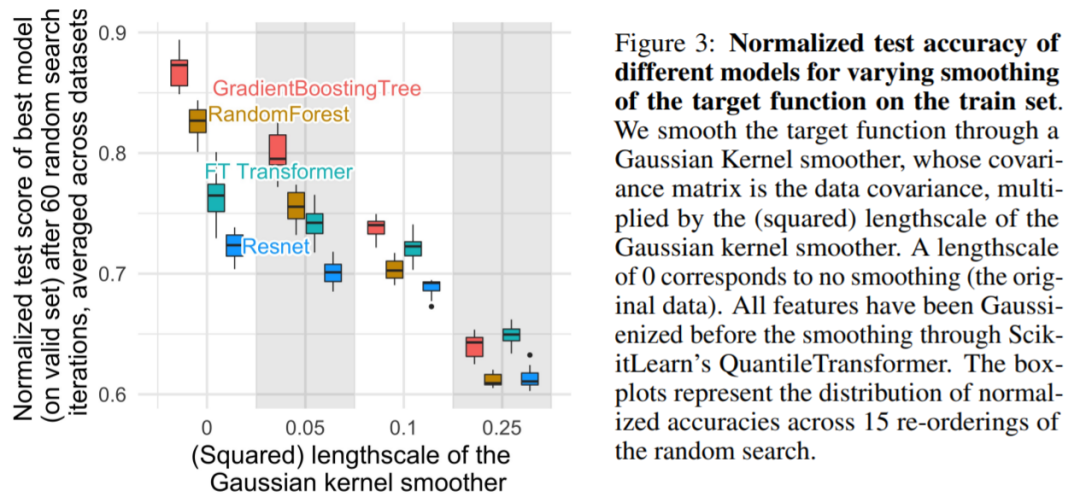
Finding 1: Neural Networks (NN) Tend to Over-Smooth Solutions
As shown in Figure 3, for smaller scales, smoothing the objective function on the training set significantly reduces the accuracy of tree-based models but has little effect on NN. These results indicate that the objective function in the dataset is not smooth, making it difficult for NN to adapt to these irregular functions compared to tree-based models. This is consistent with findings from Rahaman et al., who discovered that NN tends towards low-frequency functions. Decision tree-based models learn piece-wise constant functions without such bias.
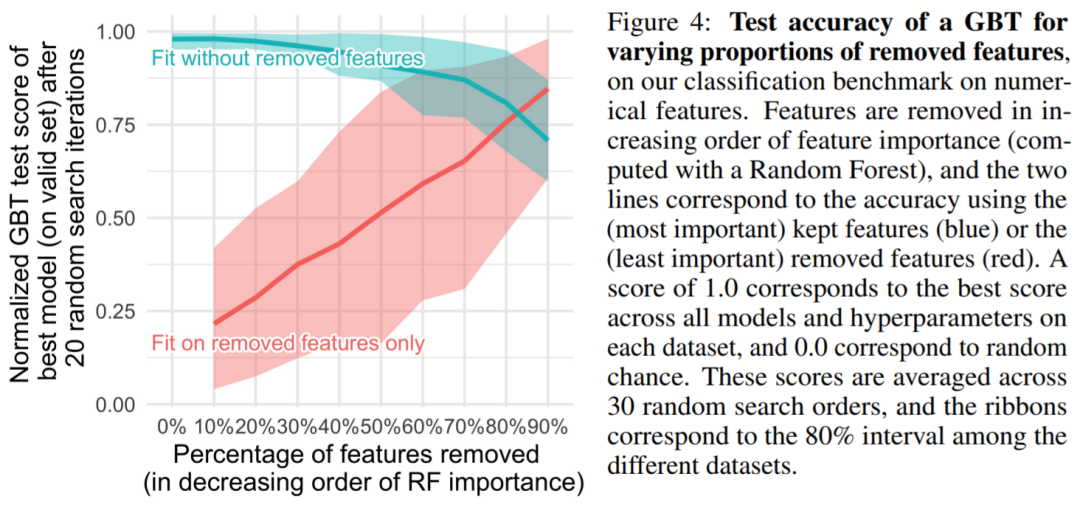
Finding 2: Non-informative Features Affect NN Like MLP More
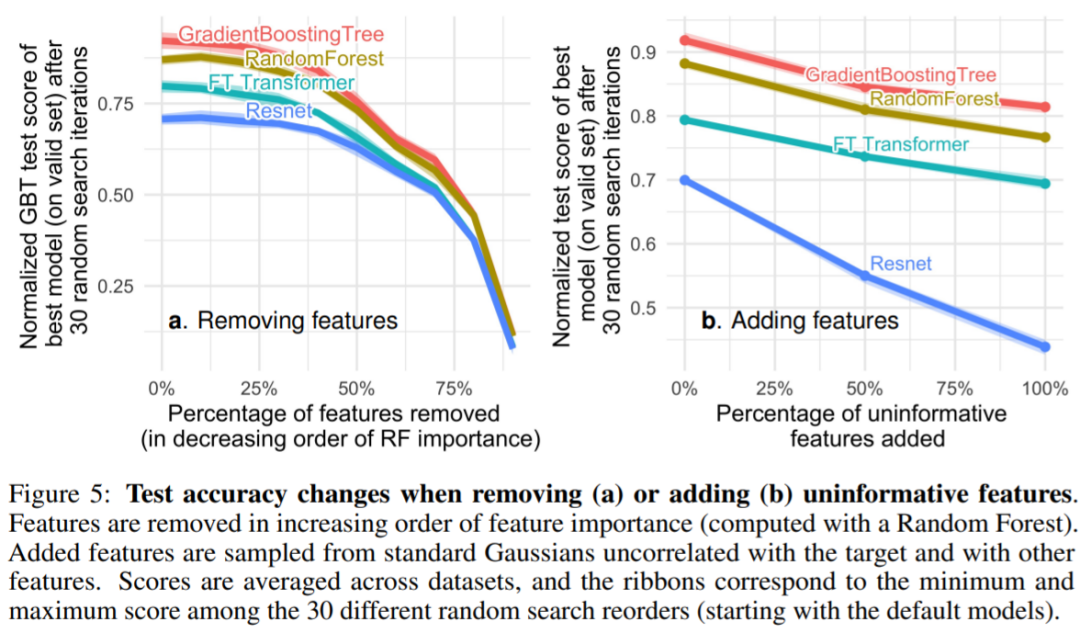
Tabular datasets contain many non-informative features, and for each dataset, the study selected a proportion of features to discard based on feature importance (usually sorted by Random Forest). As seen in Figure 4, removing more than half of the features has little impact on the classification accuracy of GBT.
In Figure 5, removing non-informative features (5a) reduces the performance gap between MLP (Resnet) and other models (FT Transformers and tree-based models), while adding non-informative features widens the gap, indicating that MLP has poor robustness to non-informative features. In Figure 5a, when researchers remove a larger proportion of features, they also remove useful informative features. Figure 5b indicates that the accuracy drop from removing these features can be compensated by removing non-informative features, which is more helpful for MLP compared to other models (while the study also removed redundant features without affecting model performance).
Finding 3: Data is Non-Invariant Through Rotation
Why are MLPs more affected by non-informative features compared to other models? One answer is that MLP is rotation-invariant: when applying rotation to features in the training and test sets, learning MLP on the training set and evaluating it on the test set remains invariant. In fact, any rotation-invariant learning process has a worst-case sample complexity that grows linearly with the number of irrelevant features. Intuitively, to eliminate useless features, rotation-invariant algorithms must first find the original direction of the features and then select the least informative features.
Figure 6a shows the change in test accuracy when the dataset undergoes random rotation, confirming that only Resnets are rotation invariant. Notably, random rotation reverses the performance order: the result is that NN is above tree-based models, and Resnets are above FT Transformer, indicating that rotation invariance is undesirable. In fact, tabular data often has individual meanings, such as age, weight, etc.
Figure 6b shows that removing the least important half of the features from each dataset (before rotation) reduces the performance of all models except Resnets, but comparatively, the magnitude of the decline is smaller than when using all features without removing any.
Original link: https://twitter.com/GaelVaroquaux/status/1549422403889