1 Algorithm Introduction
XGBoost, short for eXtreme Gradient Boosting, is an ensemble learning algorithm based on Gradient Boosting Decision Trees (GBDT). It improves upon GBDT by introducing regularization terms and second-order derivative information, enhancing model performance and generalization ability.
2 Algorithm Principles
The core idea of the XGBoost model is to combine multiple weak classifiers (decision trees) into a strong classifier. Each decision tree is trained based on the residuals of the previous tree, iteratively optimizing the loss function to gradually reduce the residuals. At the same time, the model reduces the risk of overfitting by controlling the complexity of the trees and the regularization terms.
The principles of XGBoost are based on the gradient boosting algorithm, which iteratively adds prediction trees, with each tree attempting to correct the errors of the previous tree. Key features of XGBoost include:
(1) Second-order Taylor expansion: XGBoost uses second-order Taylor expansion in optimizing the loss function, making the algorithm more precise in handling non-linear problems.
(2) Regularization: To prevent overfitting, XGBoost incorporates regularization terms into the objective function to control model complexity.(3) Missing value handling: XGBoost can automatically handle missing values in the data by learning the optimal split points to manage missing data.(4) Parallelization: XGBoost supports parallel processing of feature dimensions, improving the training efficiency of the algorithm.(1) Data preprocessing: Initially, the raw data needs to be cleaned and preprocessed. This includes handling missing values, dealing with outliers, feature selection, and data normalization.
(2) Splitting training and testing sets: To evaluate the model’s performance, the dataset needs to be divided into training and testing sets. Typically, 80% of the data is used for training, and 20% for testing.
(3) Parameter tuning: The XGBoost model has many adjustable parameters, such as learning rate, number of trees, and tree depth. Techniques like cross-validation and grid search can be used to find the optimal parameter combination.
(4) Training the model: The model is trained using the training set. The XGBoost model gradually optimizes the classifier based on the defined loss function, generating multiple decision tree models.
(5) Model evaluation: The trained model is evaluated using the testing set. Common evaluation metrics include accuracy, precision, recall, and F1-score.
3 Algorithm Applications
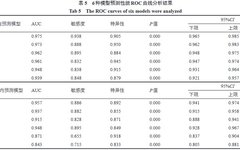
XGBoost has a wide range of applications across various fields, including financial risk control (credit card fraud detection, loan approval), recommendation systems (product recommendations, news recommendations), and biomedicine (gene expression data analysis, building precise models for disease diagnosis), etc. In the field of traditional Chinese medicine, XGBoost is often used in recurrence prediction studies. Researchers such as Hao Ruofei have constructed XGBoost models to predict recurrence in patients with ischemic stroke undergoing traditional Chinese medicine treatment, while also building logistic regression (LR), support vector machine (SVM), Gaussian process model (GBM), decision tree (DT), and random forest (RF) models. The study included 48 patients with ischemic stroke from March 2019 to June 2022 at the Huguosi Traditional Chinese Medicine Hospital affiliated with Beijing University of Chinese Medicine, divided into recurrence and non-recurrence groups, comparing the differences in various indicators between the two groups, constructing recurrence risk prediction models, and including variables with inter-group differences of P<0.1 as risk variables. The sample cases were randomly divided into training and testing sets in a 7:3 ratio for model training and validation. Based on the predicted false positive rate, false negative rate, and overall accuracy, ROC curves were drawn to calculate AUC, sensitivity, and specificity, selecting the model with the best predictive performance.
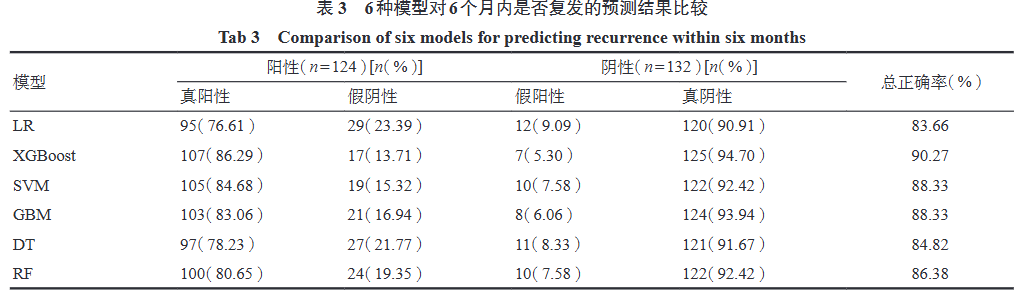
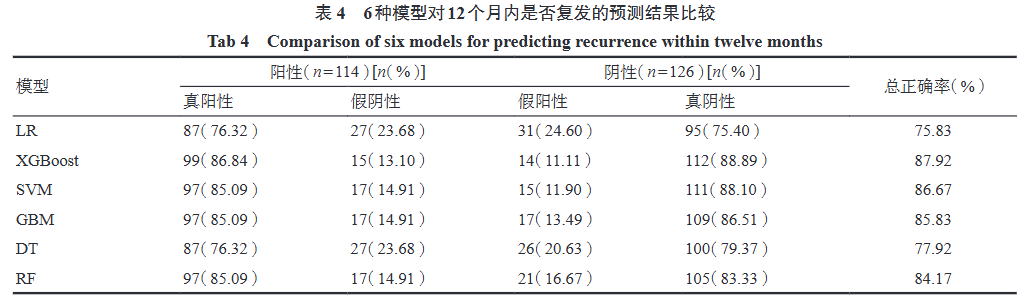
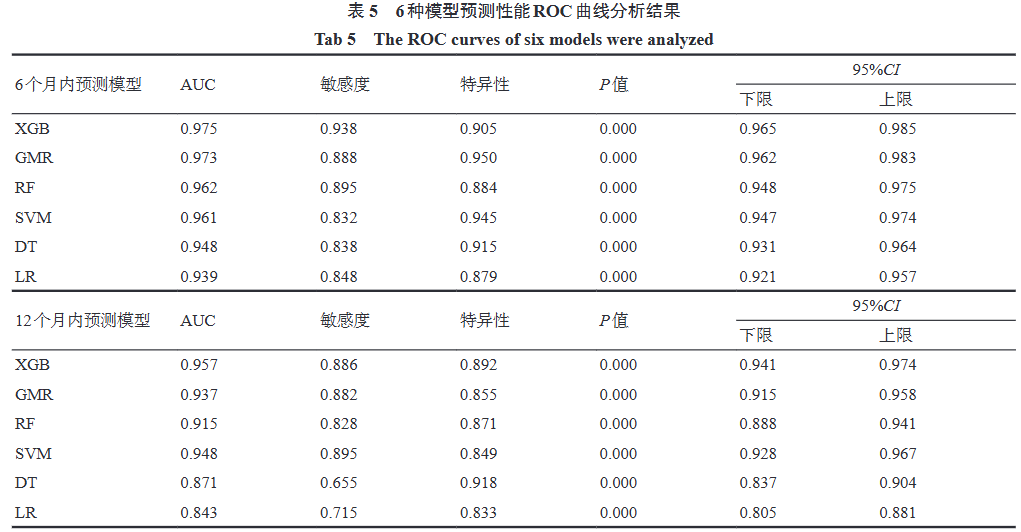
4 Conclusion
Recommended Reading:
CLIP Model: Building Universal Representations for Vision and Language
Prompt Learning: A New Tool for Language Models to Perform Well in Low-Resource Scenarios
Masked Language Models: Key Technologies for Building Next-Generation Intelligent Language Processing Systems

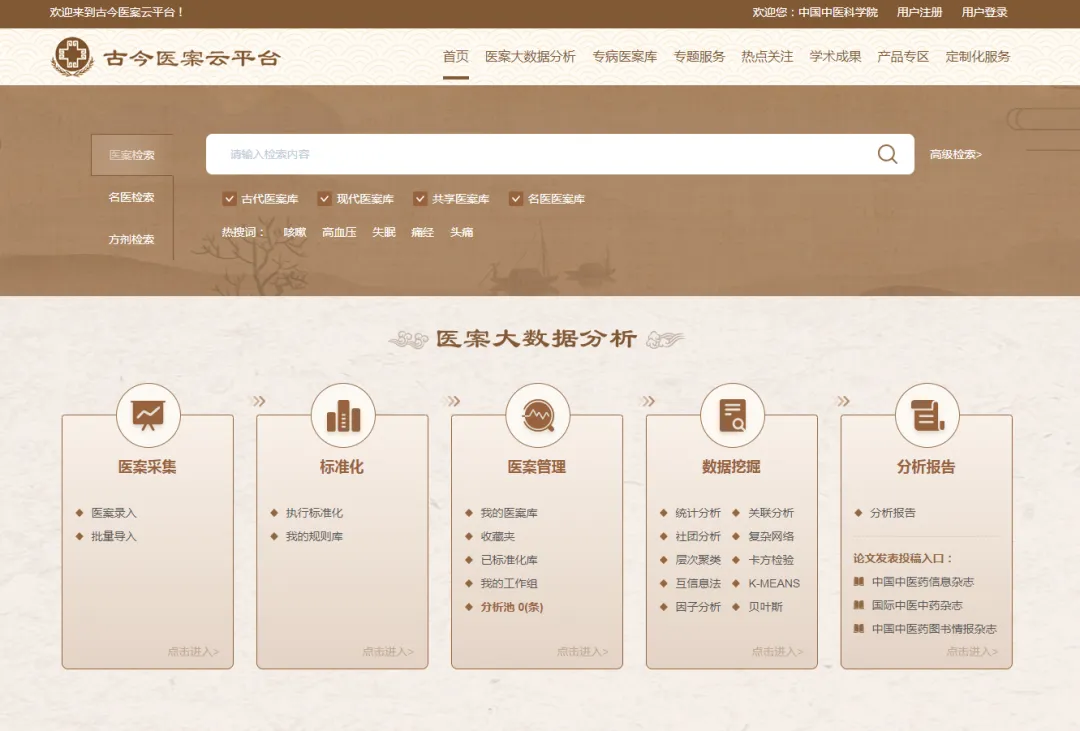
Gu Jin Medical Case Cloud Platform
Providing over 500,000 historical and contemporary medical case search services
Supports manual, voice, OCR, and batch structured input of medical cases
Designed with nine analysis modules, close to clinical practical needs
Supports collaborative analysis of massive medical cases and personal cases on the platform
EDC Traditional Chinese Medicine Research Case Collection System
Supports multi-center, online random grouping, data entry
SDV, audit trail, SMS reminders, data statistics
Analysis and other functions
Supports custom form design
Users can log in at: https://www.yiankb.com/edc
Free trial!
Institute of Traditional Chinese Medicine Information Research, China Academy of Chinese Medical Sciences
Intelligent R&D Center for Traditional Chinese Medicine Health
Big Data R&D Department
Phone: 010-64089619
13522583261
QQ: 2778196938
https://www.yiankb.com