
Click the card below to follow「AI Vision Engine」public account


Event-based cameras (EBCs) are a biologically inspired alternative to traditional cameras, emerging due to their advantages in energy efficiency, temporal resolution, and high dynamic range.
However, developing corresponding image analysis methods is quite challenging due to the sparsity and asynchronicity of EBC data. This study aims to address the object detection problem in EBC cameras. Current methods for EBC object detection mainly focus on building complex data representations and rely on specially designed architectures.
Here, the authors demonstrate that by combining the latest real-time detection Transformer or RT-DETR with a simple image representation of EBC data, outstanding performance can be achieved, surpassing existing state-of-the-art results. Specifically, the authors showcase an RT-DETR model trained on EBC data that performs comparably to the most advanced EBC object detection methods.
Subsequently, the authors propose a method inspired by Low-Rank Adaptation (LoRA) to enhance the RT-DETR model to handle the temporal dynamics of the data. The designed EvRT-DETR model outperforms current state-of-the-art results on standard benchmark datasets Gen1 () and Gen4 (), while only using standard modules for natural image and video analysis.
These results indicate that effective adaptation of mainstream object detection architectures can achieve efficient EBC object detection without requiring specialized architectural engineering.
unsetunset1. Introductionunsetunset
Event-based cameras (EBCs) provide a biologically inspired alternative to traditional frame-based cameras. Unlike traditional cameras that capture data at a predetermined frame rate, EBC pixels operate asynchronously, generating data only when they detect changes in brightness. This results in significant low power consumption (as low as 10 mW) and reduced data transmission rates. Combined with their excellent temporal resolution (in microseconds) and high dynamic range (greater than 100 dB), EBCs have found widespread applications in autonomous driving, robotics, and wearable electronics.
Despite these advantages, EBC data presents unique challenges for computer vision applications. Traditional cameras generate regular-shaped two-dimensional (2D) image frames, while EBC data consists of asynchronous pixel event streams. Each event is a tuple containing three elements: the location of the brightness change, the timestamp, and the polarity (whether brightness is increasing or decreasing). Events are generated only when the brightness change exceeds a preset threshold, resulting in high sparsity of the data. The sparsity and temporal characteristics of EBC data make it non-trivial to directly apply traditional computer vision techniques.
This paper addresses the object detection problem associated with Electromagnetic Wave Ranging (EBC) data. Current solutions to this problem mainly focus on two directions: (1) constructing complex image-like representation methods to represent EBC data (e.g., [34]), and (2) designing new object detection architectures that can handle the temporal characteristics of EBC data (e.g., [20]). Both directions make it possible to achieve high-performance object detection methods using EBC data.
Although existing EBC object detection methods perform well, they also have some shortcomings. First, they require significant engineering effort in data representation and model architecture design. This leads to a specialized development path that deviates from the development path of object detection methods based on frame-based cameras. This deviation makes it non-trivial to benefit directly from advances in the traditional computer vision field.
Here, the authors explore how to effectively adapt the latest natural image detector—real-time detection Transformer (RT-DETR) [32]—to EBC using a two-stage approach. In the first stage, the authors use a simple image representation of EBC data and train the RT-DETR model directly on this representation. Notably, this simple approach achieves performance comparable to state-of-the-art EBC-specific object detection methods. This is particularly surprising, as EBC-specific methods attempt to leverage the temporal characteristics of EBC data and focus on the distant past. In contrast, the authors’ method uses only a fixed single-frame time window (50 milliseconds), similar to traditional frame-based cameras.
In the second stage, the RT-DETR model is extended to handle EBC video, which is a sequence of fixed-time frames. Inspired by efficient adaptation methods like Low-Rank Adaptation (LoRA) [13], the authors build upon a pre-trained RT-DETR model that was pre-trained on single frames. The authors freeze this model and insert a lightweight recurrent neural network (RNN) temporal processing module into its encoder’s latent space. The designed EvRT-DETR model achieves state-of-the-art performance on standard benchmark datasets Gen1 [5] and Gen4 [22] with minimal temporal modifications, using only a simple image-like representation of EBC data and the standard RT-DETR architecture.
The contributions of this work are:
-
The authors demonstrate that the performance of RT-DETR trained on a simple image-like representation of EBC data is comparable to methods specifically designed for EBC object detection. -
The authors propose an efficient method to adapt the frozen RT-DETR model to video-based object detection with minimal architectural modifications. -
EvRT-DETR achieves state-of-the-art performance on standard Gen1 () and Gen4 () EBC benchmarks with minimal modifications to RT-DETR.
unsetunset2. Related Workunsetunset
Current analysis research on EBC data mainly focuses on two directions. First, finding efficient EBC data representation methods; second, exploring the neural network architectures best suited for EBC data.
Data Representation. Event cameras produce time-series event data in the form of , where is the timestamp of the event, is the polarity of the brightness change (positive or negative), and is the spatial location of the event pixel. To simplify analysis, event data is often transformed into other forms of representation to better suit traditional image analysis algorithms.
The simplest image representation of event camera data is called an event frame or 2D histogram representation [6]. To construct this representation, events can be segmented from the event stream based on fixed time windows. Then, events are collected within each time window, forming a 2D frame with a shape of , where the first dimension corresponds to event polarity and corresponds to the index of the camera sensor array.
A natural evolution of the 2D histogram representation is the stacked 2D histogram representation, where each frame is further divided into fixed time intervals ([6]). Such division leads to a data representation of shape , which is often reshaped to and treated as a natural image with channels.
Histograms and stacked histograms are the simplest and most image-like representations of EBC data. However, directly applying existing computer vision algorithms on these representations leads to poor performance [22].
To achieve better performance, other representation methods are being explored. For example, the temporal surface (TS) representation [6, 34] is an image-type representation where pixel values encode the time since the last event occurred at the given pixel. Therefore, unlike the simplest fixed-time window representation, TS has the potential to encode arbitrary distant past events. Experiments show that using TS representation significantly outperforms 2D histogram representation in object detection tasks [22].
Many other event data representation methods have also been proposed. Recent work ERGO-12 [34] developed an efficient image-like representation method that achieved state-of-the-art object detection performance on the Gen1 dataset. Meanwhile, other approaches reformulate object detection as a 3D problem by treating events as points in space-time or discretizing them into voxel grids [6]. While these representation methods are computationally heavier, they can retain precise event timing information and may better handle overlapping objects and complex motions.
Object Detection Architectures Based on EBC. Once a data representation is selected, object detection algorithms can be developed. Several classes of object detection methods have been designed for specific data representations.
For instance, the simplest 2D histogram (frame) representation can be used directly with traditional image object detection methods. While this is the most straightforward approach, unfortunately, it performs poorly [22].
Several methods based on 2D histogram frames extend analysis to video sequences. For example, the Recurrent Visual Transformer (RVT) [10] and State Space Visual Transformer (S5-ViT-B) [35] have designed neural architectures with various forms of temporal memory to better capture the sequential characteristics of EBC frames. Utilizing the temporal dimension significantly improves object detection quality compared to independent frames.
Recent research methods focus on using more efficient event representation forms to further enhance object detection performance. For example, the 12-channel event representation obtained through generalized Wasserstein optimization (ERGO-12) [34] constructs an optimized image-style event representation and demonstrates that standard object detection methods perform excellently on this representation. Another approach, the Asynchronous Spatio-Temporal Memory Network (ASTMNet) [15] and Adaptive Event Conversion (AEC) [19], attempt to combine better event representations with novel neural architectures to extend existing state-of-the-art results.
Many other methods have been developed, either treating EBC object detection as a 3D detection problem [9, 22, 26], leveraging the advantages of neuromorphic architectures [2], or exploring various hybrid methods [20, 21].
unsetunset3. Methodsunsetunset
This section describes the authors’ methods for EBC object detection. First, the authors explain the EBC data representation used, then discuss the structure of the RT-DETR architecture used as the baseline model. Finally, the authors introduce lightweight modifications made to the RT-DETR architecture to enable video memory functionality.
3.1. Event Representation
As previously mentioned, the authors attempt to use a simple preprocessing pipeline and convert EBC data into an image representation similar to stacked 2D histograms [6].
EBCs generate an asynchronous event stream where each event is a tuple of the form . Here, is the timestamp of the event, is the polarity (whether the change in light intensity is positive or negative), and is the spatial coordinates of the pixel generating the event. In this work, the authors segment the event stream into fixed time windows and buffer the events in each time window into an image-like historical representation , which the authors refer to as “frames.” To ensure direct comparability with existing methods, the authors adopt the frame construction parameters of RVT [10], thereby isolating the impact of the authors’ architectural choices on data preprocessing. Specifically, the authors segment a series of continuous fixed-time windows from the event stream, each lasting , with each such window corresponding to a single frame. Next, the authors further subdivide each frame into 10 intervals of . To construct the corresponding frame for the interval , the authors create an intermediate stacked histogram from the set of events within that interval.
Where , is the index of bins, is the spatial index of events in the EBC matrix, and 1 is the indicator function. Once a stacked histogram of shape is constructed, the authors can merge the polarity and temporal dimensions to obtain a 2D frame of image-style shape.
3.2. The RT-DETR Model
This paper relies on the RT-DETR architecture [32] for object detection. The RT-DETR model is one of a series of models derived from the Detection Transformer (DETR) [1]. DETR is the first widely successful Transformer-based object detection model [29]. Unlike traditional convolutional neural network (CNN) architectures [11, 25], DETR’s concise and elegant object detection pipeline makes it a highly attractive choice.
The DETR model is a hybrid CNN-Transformer model that adopts a backbone-encoder-decoder architecture. The backbone is a traditional CNN feature extraction backbone (e.g., ResNet [12]), followed by a Transformer encoder that transforms its features into tokens and captures the relationships between them. Finally, DETR’s decoder part is based on the Transformer decoder architecture. It decodes the encoder output through a cross-attention mechanism to identify objects in the image.
The original DETR model performs well overall [1], but suffers from serious training instability [30], poor prediction quality for small objects [1], and excessive inference time [33]. A series of follow-up works [1, 33] have attempted to address these issues by using feature pyramid networks (FPN) features, re-examining the role of decoder tokens, and employing deformable attention mechanisms for efficient feature querying.
Cumulative improvements to the DETR model led to the implementation of the RT-DETR model [32], which exhibits excellent detection performance across all object scales, stable training, and short inference times. The combination of advanced performance with real-time inference (>100 FPS) makes RT-DETR an ideal foundation for EBC object detection.
3.3. Temporal Dependencies
As described in Section 3.1, the authors use an image representation of EBC data in fixed time frames. While these frames can be processed independently, they actually constitute a continuous time series (video). The temporal dimension contains important information that aids in the object detection problem.
In particular, unlike traditional cameras that can capture the entire scene, EBCs can only detect changes in brightness.
Under uniform lighting conditions, this is equivalent to being able to detect only motion. Due to this characteristic of EBCs, stationary objects are almost invisible.
If a stationary target appears in the field of view of the event camera, its presence can still be inferred indirectly by considering the object’s past history. If at some previous time point, the target entered the camera’s scene, its stopping position can be approximated as the position of that target at any future time point. Therefore, for the localization of static targets, it may be necessary to use an object detection architecture with temporal memory.
There are various approaches to designing memory mechanisms in object detection architectures. For example, recent EBC detection methods rely on RNN memory mechanisms [10] or state space models [35]. On the other hand, natural object detection methods tend to use Transformer architectures as memory mechanisms [24].
While both Transformer and RNN architectures can capture temporal dependencies, RNNs have the advantage of arbitrary long-range attention spans when tracking stationary targets over long periods.
Based on these considerations, namely long-range attention and ease of implementation, the authors adopt an RNN-based memory mechanism in their methods.
3.4. EvRT-DETR
The authors’ EBC object detection method combines the object detection capability of RT-DETR with an RNN-based temporal memory module, forming a hybrid RT-DETR+RNN architecture (EvRT-DETR). The authors then train it in a two-stage manner.
In the first stage, the authors train an RT-DETR model on individual EBC frames (see Section 3.1), treating them as traditional images. This RT-DETR model provides a solid baseline and serves as the foundation for the second stage.
In the second stage, the authors start from the pre-trained RT-DETR model from the previous stage and freeze it. The authors then add temporal processing capabilities by inserting a lightweight RNN module into the latent space of the frozen encoder. The authors train the temporal RNN module only on EBC video segments while keeping the baseline RT-DETR frozen.
This modular design has several advantages. First, it clearly separates spatial and temporal feature processing, allowing for simple replacement with different spatial/temporal architectures. Similarly, this also allows leveraging the proven effective RT-DETR training strategy as the first stage, reducing the hyperparameter exploration space. Second, freezing RT-DETR prevents RNN gradient oscillations from degrading the performance of the baseline model. Finally, this separation allows each component to be optimized independently.
unsetunset4. Experimentsunsetunset
4.1. Datasets
The authors use two standard EBC object detection benchmark datasets—Gen1 [5] and Gen4 [22]—to test their algorithm. These datasets contain EBC recordings collected in various driving scenarios by the neuromorphic vision technology company Prophesee.
Gen1. The Gen1 dataset [5] is a widely used automotive dataset for object detection. It contains over 39 hours of continuous recordings of various driving situations. The dataset was acquired by a GEN1 EBC with a spatial resolution of 304×240 pixels. For analysis convenience, the dataset is organized into 60-second video segments and divided into training/testing sets, which include 1460 training clips and 470 testing clips. Gen1 is manually annotated at a frequency of 1-4 Hz (depending on the recording) from the parallel flow of natural image frames. Two classes of targets are annotated: cars and pedestrians.
Gen4. The Gen4 dataset [22] (also known as the dataset) was collected using the next-generation GEN4 version of the Prophesee camera. Unlike the GEN1 camera, the GEN4 is equipped with a larger sensor with a resolution of 1280×720. The dataset contains over 14 hours of driving recordings under various conditions. Similarly, this dataset is divided into 60-second video segments and split into training/testing sets, which include 11.19 hours of training video and 2.25 hours of testing video. The dataset is automatically annotated at a frequency of 60 Hz. For the object detection task, the dataset provides annotation information for vehicles, two-wheelers, and pedestrians.
4.2. Data Pre-processing
The authors follow the established RVT protocol [10] for data preprocessing. They construct event frames as 2D histogram representations for each 50-millisecond time window. Each frame is divided into 10 equal-duration 5-millisecond intervals. For the Gen1 dataset with a size of (240, 304), the authors zero-pad the frames to (256, 320) to ensure they are divisible by 32.
For the Gen4 dataset, the authors resize the image dimensions from (720,1280) to (360,640) to maintain consistency with previous work. The authors achieve this resizing by first constructing a full event frame of size (720,1280) and then using bilinear interpolation to downscale it by half. Similarly, for the Gen1 dataset, the authors also zero-pad the frame size to (384,640). For the Gen4 dataset, the authors deviate slightly from the RVT method, which only retains annotations for every other frame. Instead, the authors retain annotations for all frames, simplifying the data preprocessing process without significantly affecting model performance.
4.3. Training
The authors train EvRT-DETR in two stages. In the first stage, they train the RT-DETR baseline model using the Adam optimizer [14]. They use a batch size of 32 and keep the learning rate constant throughout the training process. Following standard RT-DETR training methods, the authors save the model weights’ exponential moving average (EMA) with a momentum of 0.9999. In total, the authors train RT-DETR for 400,000 iterations.
For the second training stage of the EvRT-DETR model, the authors start from the RT-DETR baseline from the previous step. They freeze the RT-DETR and train an RNN memory module operating on top of it. For training the RNN module, the authors closely mimic the RVT setup [10]. Specifically, they train on a mixture of random and sequential segments within the complete video. In each iteration, the authors select 4 random segments and use 4 consecutive segments, resulting in a total batch size of 8. For each random segment, the authors reset the memory RNN, but maintain RNN memory consistency for consecutive segments within the same video. For the Gen1 dataset, the authors use 21-frame segments; for the Gen4 dataset, they use 10-frame segments. The authors rely on the Adam optimizer, a 1-cycle learning rate scheduler [28], and a maximum learning rate of . The authors did not observe any benefits from using exponential moving average (EMA) to train the RNN memory module. In total, the RNN training runs for 200,000 iterations.
4.4. Evaluation Metrics
The authors evaluate model performance based on the standard COCO (Common Objects in Context) Mean Average Precision (mAP) metric [16]. To maintain consistency with previous literature, the authors rely on the EBC-specific implementation of COCO metrics provided by Prophesee’s Automotive Dataset Toolbox [22, 23].
4.5. Results
Table 2 shows the performance of the EvRT-DETR model compared to results from the literature. For single-frame training, the authors present the performance of the RT-DETR-T model (RT-DETR PResNet-18 configuration) and the RT-DETR-B model (RT-DETR PResNet-50 configuration).
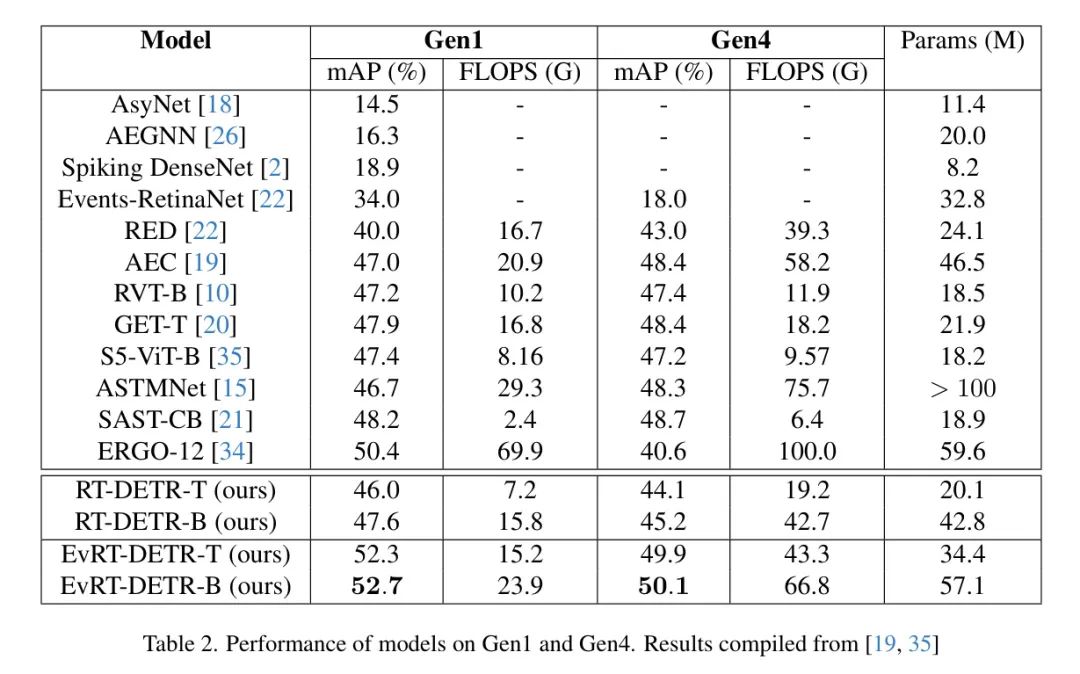
As shown in Table 2, training the RT-DETR model directly on EBC data already demonstrates quite competitive performance without any architectural engineering or data representation design. By adding the RNN plugin, EvRT-DETR shows superior performance among all competitors, even under the lightest configuration (EvRT-DETR-T).
In this study, the authors focus on evaluating the direct model detection performance. While computational efficiency is crucial, direct runtime comparisons become quite challenging due to the heterogeneity of time benchmarks reported in the literature (different hardware configurations, inclusion or exclusion of preprocessing pipelines, numerical precision, graph compilation choices, etc.). Therefore, the authors only present the model’s detection performance, leaving systematic and robust temporal analysis for future work. Given that the original RT-DETR implementation can process 108 frames per second (FPS) on natural images with higher resolutions than the authors’ EBC frames (Gen1 and Gen4), the authors expect computational performance to be sufficient for practical applications.
4.6. Ablations
Here, the authors explore the role of data augmentation and test using the YOLOX baseline method, which originates from the YOLO series of detectors.
Data Augmentation. When the RT-DETR model is trained directly on the benchmark dataset, the authors observe severe overfitting and poor model generalization. Therefore, this paper relies heavily on data augmentation techniques.
Table 3 summarizes various data augmentation methods in this study’s ablation experiments. The first two rows show the performance of the RT-DETR-B model with and without data augmentation. The subsequent rows demonstrate how model performance changes when the authors remove one data augmentation method from the final configuration (these removals are independent, not cumulative).
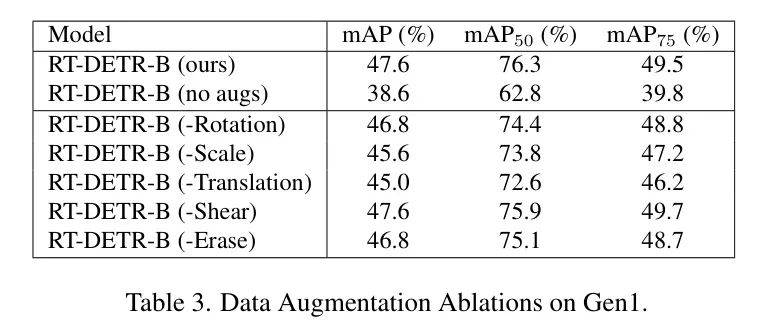
According to Table 3, the performance of RT-DETR-B without data augmentation drops by 9 mAP. Among the various contributions, random translation and random scaling yield the largest performance improvements. Random rotation and random erasure produce comparable but smaller improvements in model performance. Finally, random cropping has the least impact on model performance.
Alternative Baseline Models. The authors developed an object detection model based on the RT-DETR backbone. Naturally, one might question whether the observed improvements are specific to RT-DETR or can be replicated with other common object detection backbones.
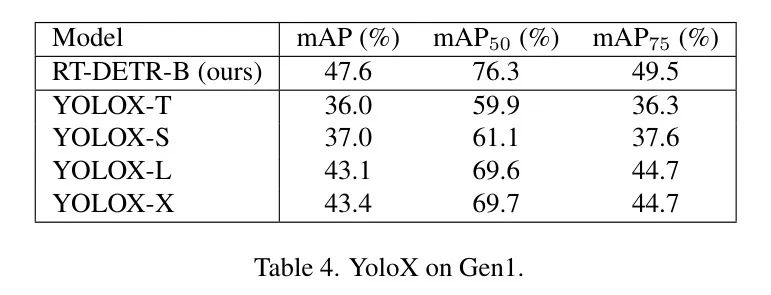
The authors attempt to replace the RT-DETR baseline model with another popular natural image architecture, YOLO, specifically using YOLOX [7]. The YOLOX object detection head has already been successfully explored in other EBC object detection architectures [10, 35], making it a natural choice for comparison.
Table 4 shows the performance of the YOLOX object detection baseline on the Gen1 dataset. The training setup for the YOLOX model is identical to that of the RT-DETR baseline. Although the best-performing YOLOX-X model has an mAP of 43.4%, lower than the 47.6% of RT-DETR-B, it still performs excellently in competition with architectures specifically designed for EBC. This indicates that natural image detectors may not be limited to RT-DETR for EBC data, especially evident in newer versions of the YOLO family.
unsetunset5. Conclusionsunsetunset
This study demonstrates the surprising effectiveness of mainstream RT-DETR object detection algorithms in EBC. The authors prove that applying RT-DETR to a basic image representation of EBC data achieves results comparable to methods specifically designed for EBC.
Furthermore, the minimal temporal adjustments made to the frozen RT-DETR achieve state-of-the-art performance while maintaining architectural simplicity.
Additionally, the authors’ experiments on YOLOX, although not reaching the performance of RT-DETR, indicate that the use of natural image object detection methods may have generalizability across different architectures for EBC data representations.
These results suggest that careful tuning of mainstream detection architectures can effectively handle EBC data with unique characteristics, potentially reducing the need for dedicated architecture development.
unsetunsetReferencesunsetunset
[0]. EvRT-DETR: The Surprising Effectiveness of DETR-based Detection for Event Cameras .
Click the card above to follow「AI Vision Engine」public account