
Machine Heart Reports
Currently, there are numerous providers offering deep learning services. When using these services, users need to send their information included in the prompt to these providers, which can lead to privacy leakage issues. On the other hand, service providers are generally unwilling to disclose the model parameters they have painstakingly trained.
To address this issue, a research team from Ant Group proposed the PUMA framework, which enables secure inference without compromising model performance. Moreover, they have open-sourced the relevant code.

-
Paper: https://arxiv.org/abs/2307.12533
-
Code: https://github.com/secretflow/spu/blob/main/examples/python/ml/flax_llama7b/flax_llama7b.py
Pre-trained Transformer models have shown excellent performance in many practical tasks, thus receiving significant attention. Many tools based on this technology have emerged, often providing services under the “Deep Learning as a Service (DLaaS)” paradigm. However, these services often face privacy issues. For instance, if a user wants to use ChatGPT, they either need to provide their private prompt to the service provider or require the service provider to share their proprietary trained weights with the user.
To solve the privacy issue of Transformer model services, one solution is Secure Multi-Party Computation (MPC), which can ensure the security of data and model weights during inference. However, the time and communication costs of simple basic Transformer inference in MPC are high, making it difficult to apply in practical scenarios. To achieve better efficiency, several research results have proposed various methods to accelerate secure inference of Transformer models, but these methods still have one or more of the following drawbacks:
-
Replacement is challenging. Recent work has suggested that to reduce costs, fast approximation methods such as quadratic functions and ReLU can replace high-cost functions like GeLU and softmax. However, simply replacing these functions may lead to a significant drop in Transformer model performance (which may require additional retraining of the model, i.e., fine-tuning) and deployment issues.
-
High inference costs. Some studies have proposed using more accurate polynomial functions to approximate high-cost nonlinear functions, but their approximation methods do not consider the special properties of GeLU and Softmax. Therefore, even with approximation, the costs of this method remain high.
-
Difficult to deploy. Recent studies have also proposed accelerating secure inference by modifying the architecture of the Transformer model, such as decomposing the embedding process and reorganizing the linear layers. Worse, since the Crypten framework does not support secure LayerNorm, simply using BatchNorm to simulate the cost can lead to incorrect results in secure inference. These modification methods conflict with existing plaintext Transformer systems.
In summary, in the field of MPC Transformer inference, it is challenging to achieve both model performance and efficiency, leading to the following question:
Is it possible to securely and efficiently evaluate pre-trained large Transformer models while achieving accuracy close to that of plaintext models without further retraining?
The PUMA framework proposed by Ant Group was born to solve this problem, enabling secure and accurate end-to-end execution of secure Transformer inference. The main contributions of this paper include:
-
A new method for approximating nonlinear functions. The paper proposes a more accurate and faster approximation method that can be used to approximate high-cost nonlinear functions (such as GeLU and Softmax) in Transformer models. Unlike previous methods, the newly proposed approximation method is based on the special properties of these nonlinear functions, balancing accuracy and efficiency.
-
Faster and more accurate secure inference. The researchers conducted extensive experiments using 6 Transformer models and 4 datasets, showing that when using the PUMA framework, accuracy is close to that of plaintext models while speed and communication efficiency improve by about 2 times (and note that the accuracy of MPCFORMER is inferior to PUMA). PUMA can even evaluate LLaMA-7B and generate a token in under 5 minutes. The authors state that this is the first time MPC has been used to evaluate such a large language model.
-
An open-source end-to-end framework. The researchers from Ant Group successfully designed and implemented secure Embedding and LayerNorm procedures in MPC form. The result is that the PUMA workflow follows that of plaintext Transformer models without changing any model architecture, making it easy to load and evaluate pre-trained plaintext Transformer models (such as models downloaded from Huggingface). The authors claim this is the first open-source MPC solution that supports accurate inference of pre-trained Transformer models without requiring retraining or further modifications.
PUMA’s Secure Design
PUMA Overview
The design goal of PUMA is to enable Transformer-based models to perform computations securely. To achieve this, the system defines three entities: model owner, client, and computing party. The model owner provides a trained Transformer model, the client is responsible for providing data to the system and receiving inference results, while the computing parties (i.e., P_0, P_1, and P_2) execute secure computation protocols. Note that the model owner and client can also act as computing parties, but for clarity, they will be distinguished here.
During the secure inference process, a key invariant must be maintained: the computing parties always have two-thirds of the confidential shares of the client’s input and two-thirds of the weights of the model layers at the start, and ultimately, the computing parties also have two-thirds of the confidential shares of the outputs of these layers. Since these shares do not leak information to the parties, it ensures that these protocol modules can be combined in sequence at any depth, thus providing secure computation for any Transformer-based model. PUMA primarily focuses on reducing the running time and communication costs between the computing parties while maintaining the required security level. By utilizing replicated confidential shares and the newly proposed 3PC protocol, PUMA enables secure inference for Transformer-based models in a three-party setting.
Secure Embedding Protocol
The current secure embedding process requires the client to create a one-hot vector using token IDs, which deviates from the plaintext workflow and disrupts the Transformer structure. Therefore, this method is not easily deployable in real Transformer model service applications.
To address this issue, the researchers proposed a new secure embedding design. Let token ID ∈ [n] and all embedding vectors be represented as 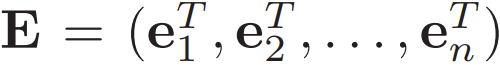 , the embedding can be represented as
, the embedding can be represented as 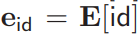 . Since (id, E) shares secrets, the operation of the newly proposed secure embedding protocol
. Since (id, E) shares secrets, the operation of the newly proposed secure embedding protocol 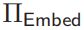 works as follows:
works as follows:
-
The computing party, upon receiving the ID vector from the client, securely computes the one-hot vector
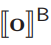 . Specifically,
. Specifically, 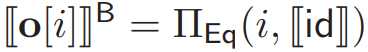 where i ∈ [n].
where i ∈ [n]. -
Each computing party can compute the embedding vector through
 without needing secure truncation.
without needing secure truncation.
In this way, the Π_Embed does not need to explicitly modify the workflow of the Transformer model.
Secure GeLU Protocol
Currently, most methods treat the GeLU function as composed of smaller functions and attempt to optimize each part, which causes them to miss the opportunity to optimize the private GeLU as a whole. Given the GeLU function:
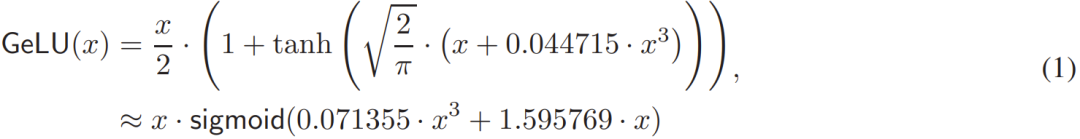
Some past methods focused on designing efficient protocols for the tanh function or applying existing power and reciprocal MPC protocols to Sigmoid.
However, these methods did not utilize the fact that the GeLU function is essentially linear on both sides, i.e., when x<−4, GeLU(x) ≈ 0, and when x>3, GeLU(x) ≈ x. The researchers propose that within the short interval [−4,3] of GeLU, a low-degree polynomial piecewise approximation is a more efficient and easier-to-implement secure protocol choice. Specifically, this piecewise low-degree polynomial is shown in equation (2):
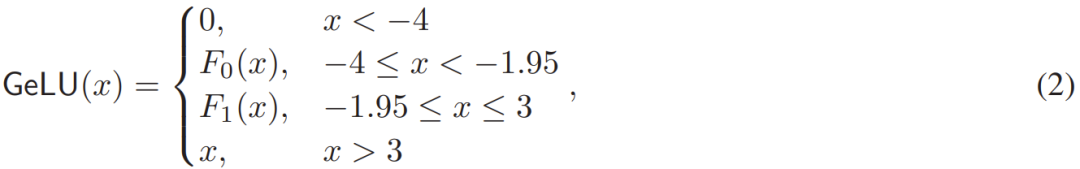
The calculations of the polynomials F_0 and F_1 are implemented using the software library numpy.polyfit, as shown in equation (3). The researchers found that this polynomial fitting, although simple, performed surprisingly well; the maximum error of the experimental results is < 0.01403, the median error is < 4.41e−05, and the average error is < 0.00168.
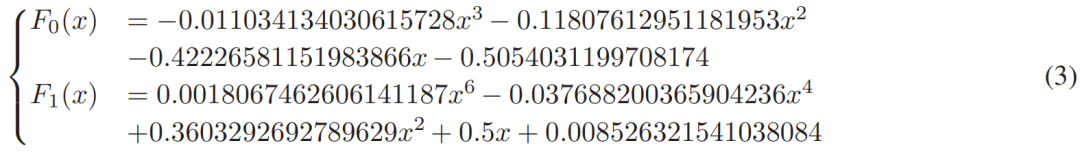
Mathematically, given the confidential input 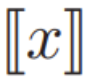 , the newly proposed secure GeLU protocol
, the newly proposed secure GeLU protocol 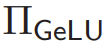 is constructed as shown in Algorithm 1.
is constructed as shown in Algorithm 1.

Secure Softmax Protocol
In the function  , a key challenge is computing the Softmax function (where M can be viewed as a bias matrix). For numerical stability, Softmax can be computed as follows:
, a key challenge is computing the Softmax function (where M can be viewed as a bias matrix). For numerical stability, Softmax can be computed as follows:
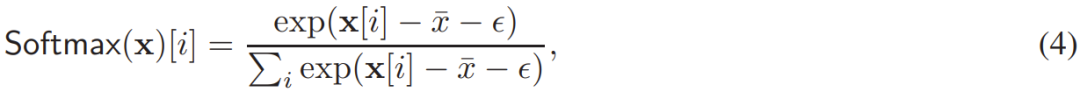
where 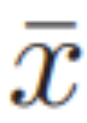 is the maximum element of the input vector x. For ordinary plaintext softmax, ε = 0. For a two-dimensional matrix, equation (4) is applied to each row vector.
is the maximum element of the input vector x. For ordinary plaintext softmax, ε = 0. For a two-dimensional matrix, equation (4) is applied to each row vector.
Algorithm 2 provides a detailed mathematical description of the newly proposed secure protocol Π_Softmax, which introduces two optimization methods:

-
The first optimization sets ε in equation (4) to a very small positive value, such as ε=10^-6, so that the input for the power operation in equation (4) is negative. The researchers utilized these negative operands to enhance speed. They specifically calculated the powers using simple clipping with Taylor series.
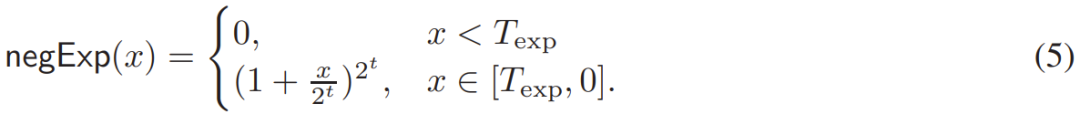
-
The second optimization proposed by the researchers is to reduce the amount of division, which ultimately lowers the computation and communication costs. Therefore, for a vector x of size n, the researchers replaced the Div(x, Broadcast(y)) operation with x·Broadcast(1/y), where
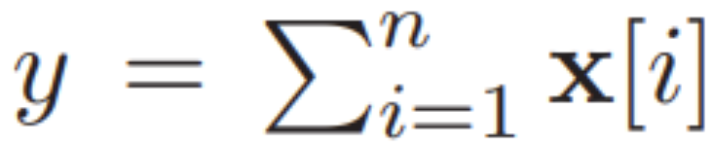 . This replacement effectively reduces n divisions to 1 reciprocal operation and n multiplications. This optimization is particularly beneficial for Softmax operations. Under fixed-point settings, 1/y remains sufficiently large during Softmax operations, making it difficult to maintain adequate accuracy. Thus, such optimizations can significantly reduce computation and communication costs while ensuring accuracy.
. This replacement effectively reduces n divisions to 1 reciprocal operation and n multiplications. This optimization is particularly beneficial for Softmax operations. Under fixed-point settings, 1/y remains sufficiently large during Softmax operations, making it difficult to maintain adequate accuracy. Thus, such optimizations can significantly reduce computation and communication costs while ensuring accuracy.
Secure LayerNorm Protocol
Recall that given a vector x of size n, 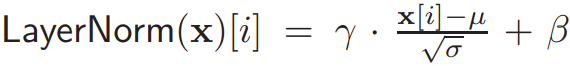 , where (γ, β) are trained parameters,
, where (γ, β) are trained parameters, 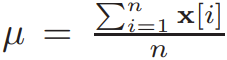 and
and 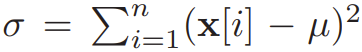 . In MPC, a key challenge is evaluating the division by the square root formula
. In MPC, a key challenge is evaluating the division by the square root formula 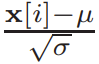 . To safely evaluate this formula, CrypTen’s approach is to execute this MPC protocol in the following order: square root, reciprocal, and multiplication. However, the researchers from Ant Group observed that
. To safely evaluate this formula, CrypTen’s approach is to execute this MPC protocol in the following order: square root, reciprocal, and multiplication. However, the researchers from Ant Group observed that 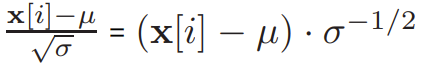 . In terms of MPC, the cost of computing the reciprocal of the square root σ^{-1/2} is close to that of the square root operation. Additionally, inspired by the second optimization in the previous section, they proposed first calculating σ^{-1/2} and then broadcasting Broadcast(σ^{-1/2}) to support fast and secure LayerNorm(x). Algorithm 3 provides the mathematical form of the Π_LayerNorm protocol.
. In terms of MPC, the cost of computing the reciprocal of the square root σ^{-1/2} is close to that of the square root operation. Additionally, inspired by the second optimization in the previous section, they proposed first calculating σ^{-1/2} and then broadcasting Broadcast(σ^{-1/2}) to support fast and secure LayerNorm(x). Algorithm 3 provides the mathematical form of the Π_LayerNorm protocol.

Experimental Evaluation

Figure 1: Performance on GLUE and Wikitext-103 V1 benchmarks, model-wise, a is Bert-Base, b is Roberta-Base, c is Bert-Large, d includes GPT2-Base, GPT2-Medium, GPT2-Large.

Table 1: Costs for an input sentence of length 128, Bert-Base, Roberta-Base, and Bert-Large. Time cost is measured in seconds, and communication cost is measured in GB.

Table 2: Costs for GPT2-Base, GPT2-Medium, and GPT2-Large. The input sentence length is 32, and these are the costs for generating 1 token.
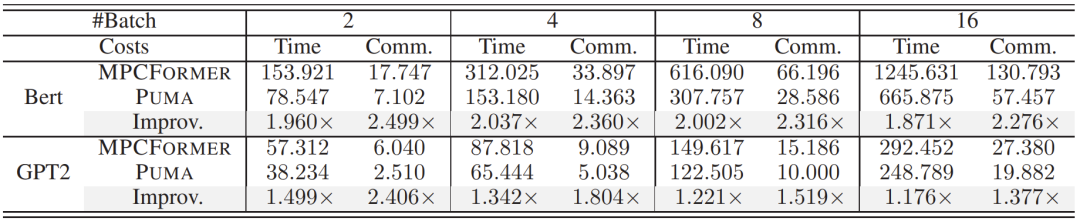
Table 3: Costs for batches of {2, 4, 8, 16} sentences. The input lengths for Bert-Base and GPT2-Base are set to 128 and 32 respectively, and the data for GPT2 is the cost of generating 1 token.
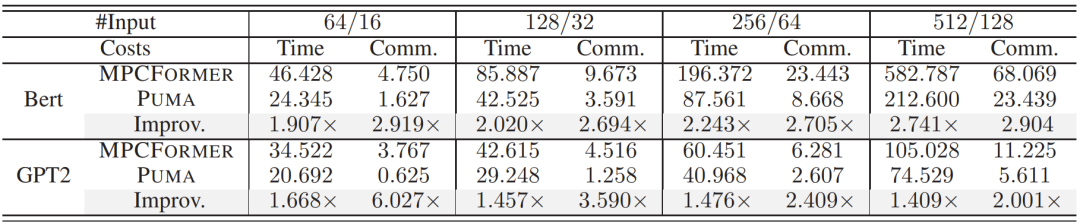
Table 4: Costs for Bert-Base and GPT2-Base under different input lengths (#Input). The input lengths for Bert-Base and GPT2-Base are set to {64, 128, 256, 512} and {16, 32, 64, 128} respectively. The data for GPT2 is the cost of generating 1 token.
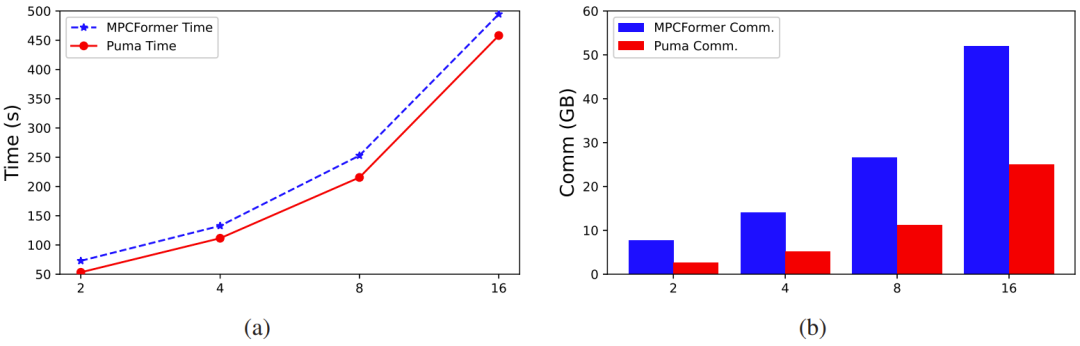
Figure 2: Costs of GPT2-Base generating different output tokens, with an input length of 32. a is the runtime cost, b is the communication cost.

Table 5: Costs of performing secure inference with LLaMA-7B, where #Input indicates the length of the input sentence and #Output indicates the number of tokens generated.
It only takes five minutes to scale for LLaMA-7B. The researchers evaluated the large language model LLaMA-7B using PUMA on three Alibaba Cloud ecs.r7.32xlarge servers, each with 128 threads and 1 TB RAM, a bandwidth of 20 GB, and a round-trip time of 0.06 ms. As shown in Table 5, PUMA can support large language models like LLaMA-7B to achieve secure inference at a reasonable cost. For example, given an input sentence composed of 8 tokens, PUMA can output one token in approximately 346.126 seconds with a communication cost of 1.865 GB. The researchers state that this is the first time an MPC scheme has been used to evaluate LLaMA-7B.
Although PUMA has achieved a series of breakthroughs, it is still an academic achievement, and its inference time is still some distance from practical deployment. The researchers believe that in the future, with the latest quantization techniques in the field of machine learning and new hardware acceleration technologies, truly privacy-protecting large model services will no longer be far from us.

© THE END
For reprints, please contact this public account for authorization
Submissions or inquiries: [email protected]