Machine Heart Column
Machine Heart Editorial Team
This article presents a unified framework called SpeechGen, which can be used for any speech LM and various speech generation tasks, showing great potential.

Introduction and Motivation
Large Language Models (LLMs) have garnered significant attention in the field of AI-generated content (AIGC), especially with the emergence of ChatGPT.
However, how to handle continuous speech with large language models remains an unresolved challenge, hindering the application of LLMs in speech generation. This is because speech signals contain rich information, such as speaker and emotion, transcending pure text data, leading to the continuous emergence of Speech Language Models (speech LMs).
Although speech language models are still in their early stages compared to text-based language models, they possess enormous potential due to the richer information embedded in speech data, which is promising.
Researchers are actively exploring the potential of the prompt paradigm to leverage the capabilities of pre-trained language models. This prompting guides pre-trained language models to perform specific downstream tasks by fine-tuning a small number of parameters. This technique has gained popularity in the NLP field due to its efficiency and effectiveness. In the field of speech processing, SpeechPrompt has demonstrated significant improvements in parameter efficiency and has achieved competitive performance across various speech classification tasks.
However, whether prompts can assist speech language models in completing generation tasks remains an open question. In this article, we propose an innovative unified framework: SpeechGen, aimed at unlocking the generation potential of speech language models. As shown in the figure below, feeding a segment of speech and a specific prompt to the speech LM as input enables the speech LM to perform specific tasks. For example, providing a red prompt as input allows the speech LM to perform speech translation tasks.
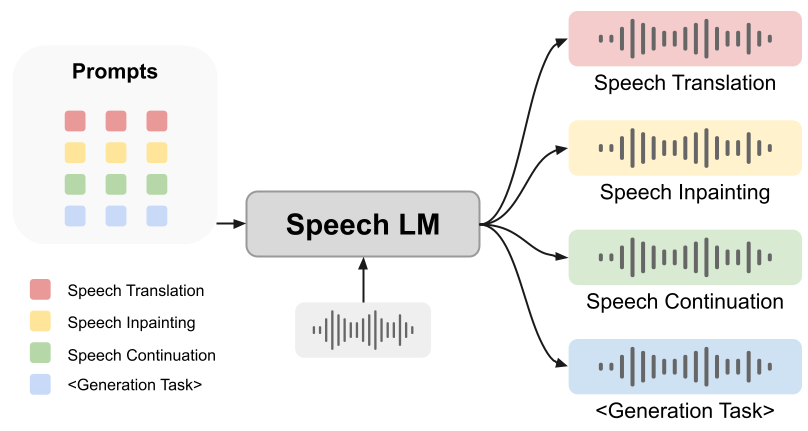
The framework we propose has the following advantages:
1. Textless: Our framework and the speech language models it relies on are independent of text data, which is invaluable. After all, the process of obtaining labeled text paired with speech is time-consuming and cumbersome, and suitable text may not even be found in certain languages. The textless nature allows our powerful speech generation capabilities to cover various language needs, benefiting all of humanity.
2. Versatility: The framework we developed is highly versatile and can be applied to a wide range of speech generation tasks. The experiments in the paper use speech translation, speech inpainting, and speech continuation as examples.
3. Easy to follow: Our proposed framework provides a universal solution for various speech generation tasks, making it easy to design downstream models and loss functions.
4. Transferability: Our framework is not only easy to adapt to future more advanced speech language models but also holds great potential for further enhancing efficiency and effectiveness. Especially exciting is that with advanced speech language models on the horizon, our framework will see even greater development.
5. Affordability: Our framework is designed to require training only a small number of parameters instead of the entire large language model. This greatly reduces computational burden and allows the training process to be executed on a GTX 2080 GPU. Such computational costs are affordable even for university laboratories.
Introduction to SpeechGen
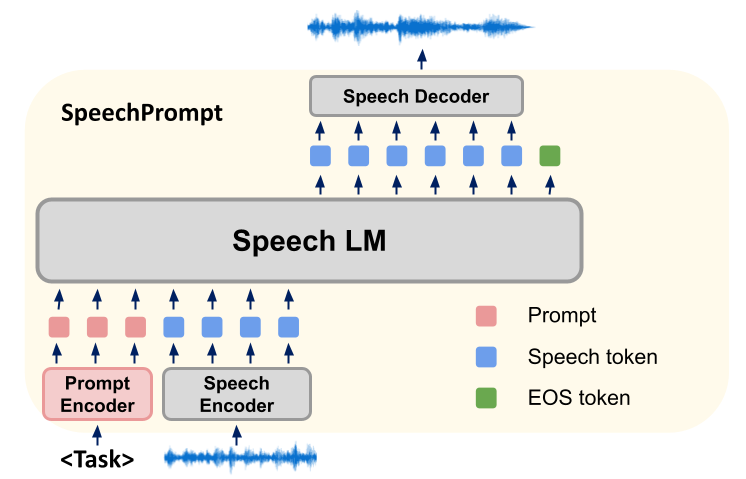
Our research approach involves building a brand new framework, SpeechGen, which primarily utilizes Spoken Language Models (SLMs) for fine-tuning various downstream speech generation tasks. During the training process, the parameters of SLMs remain unchanged, and our method focuses on learning task-specific prompt vectors. SLMs effectively generate the required outputs for specific speech generation tasks by conditioning both the prompt vectors and input units simultaneously. Then, these discrete unit outputs are fed into a unit-based speech synthesizer to generate the corresponding waveforms.
Our SpeechGen framework consists of three elements: a speech encoder, an SLM, and a speech decoder.
First, the speech encoder takes waveforms as input and converts them into a sequence of units derived from a finite vocabulary. To shorten the sequence length, duplicate consecutive units are removed to generate a compressed unit sequence. Then, the SLM serves as the language model for the unit sequence, optimizing the probability by predicting the previous unit and the subsequent units in the sequence. We perform prompt tuning on the SLM to guide it in generating appropriate units based on the task. Finally, the tokens generated by the SLM are processed by the speech decoder, converting them back into waveforms. In our prompt tuning strategy, the prompt vectors are inserted at the beginning of the input sequence, guiding the SLMs during the generation process. The specific number of prompts inserted depends on the architecture of the SLMs. In sequence-to-sequence models, both the encoder and decoder inputs receive prompts, but in architectures with only an encoder or only a decoder, a single prompt is added at the front of the input sequence.
In sequence-to-sequence SLMs (like mBART), we employ self-supervised learning models (like HuBERT) to handle input and target speech. This allows for the generation of discrete units for the input and corresponding discrete units for the target. We add prompt vectors to the front of both the encoder and decoder inputs to construct the input sequence. Furthermore, we enhance the guidance ability of the prompts by replacing key-value pairs in the attention mechanism.
During model training, we use cross-entropy loss as the objective function for all generation tasks, calculating loss by comparing the model’s predictions with the target discrete unit labels. In this process, the prompt vectors are the only parameters that need to be trained in the model, while the parameters of the SLMs remain unchanged during training, ensuring consistency in model behavior. By inserting prompt vectors, we guide the SLMs to extract task-specific information from the input and increase the likelihood of producing outputs that fit specific speech generation tasks. This approach allows us to fine-tune and adjust the behavior of SLMs without modifying their underlying parameters.
Overall, our research approach is based on a brand new framework, SpeechGen, which guides the model’s generation process by training prompt vectors, enabling it to effectively produce outputs that meet specific speech generation tasks.
Our framework can be used for any speech LM and various generation tasks, showing great potential. In our experiments, since VALL-E and AudioLM are not open-source, we chose to use Unit mBART as the speech LM for case studies. We used speech translation, speech inpainting, and speech continuation as examples to demonstrate the capabilities of our framework. The diagrams for these three tasks are shown in the figure below. All tasks involve speech input and speech output, without the assistance of text.
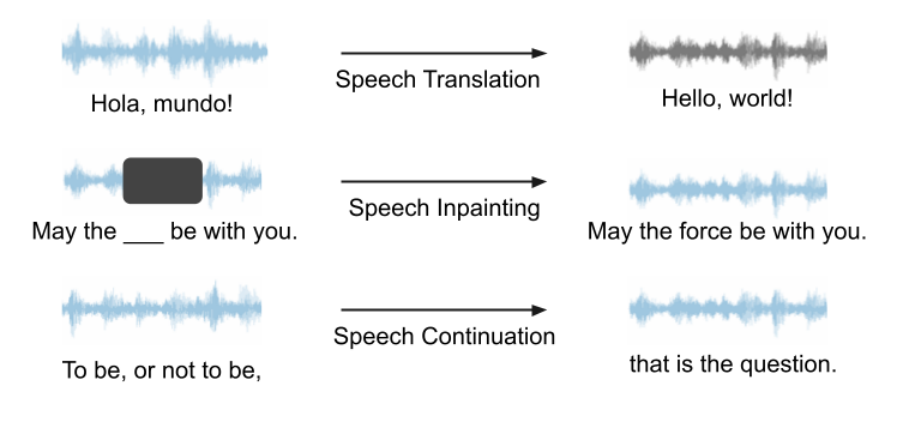
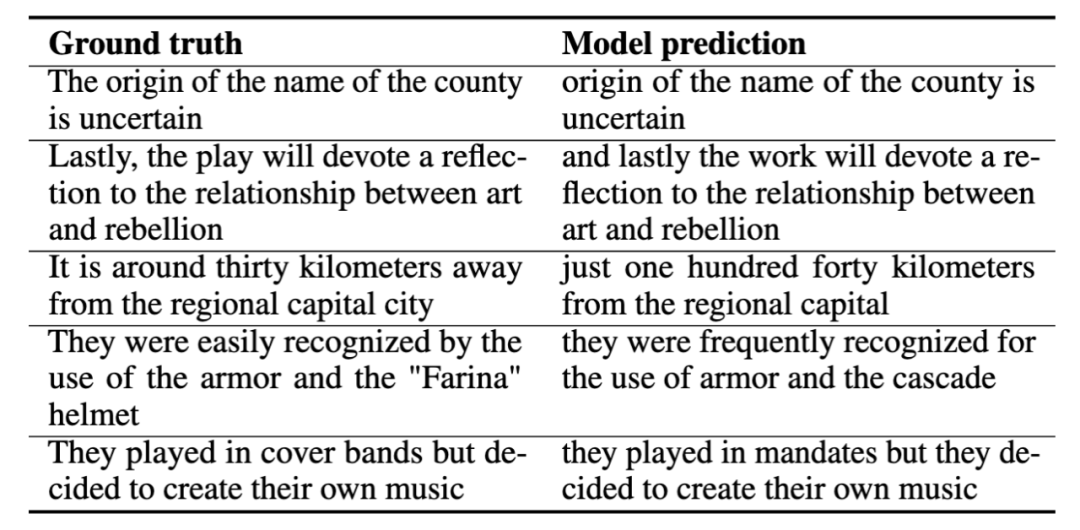
When training for speech translation, we used the task of translating Spanish to English. We provided the model with Spanish speech input, hoping it would produce English speech output, all without text assistance. Below are several examples of speech translation, where we will show the ground truth and the model’s predictions. These demonstration examples indicate that the model’s predictions capture the core meaning of the correct answers.
In our experiments on speech inpainting, we specifically selected audio segments longer than 2.5 seconds as the target speech for subsequent processing, and randomly selected a speech segment lasting between 0.8 to 1.2 seconds. We then masked the selected segment to simulate missing or damaged parts in the speech inpainting task. We used Word Error Rate (WER) and Character Error Rate (CER) as metrics to evaluate the extent of repair for the damaged segments.
Comparing the outputs generated by SpeechGen with the damaged speech, our model significantly reconstructed spoken vocabulary, reducing WER from 41.68% to 28.61% and CER from 25.10% to 10.75%, as shown in the table below. This indicates that our proposed method can significantly enhance the ability to reconstruct speech, ultimately improving the accuracy and intelligibility of the speech output.

The image below showcases an example, where the upper subplot shows the damaged speech, and the lower subplot shows the speech generated by SpeechGen, demonstrating that SpeechGen effectively repaired the damaged speech.
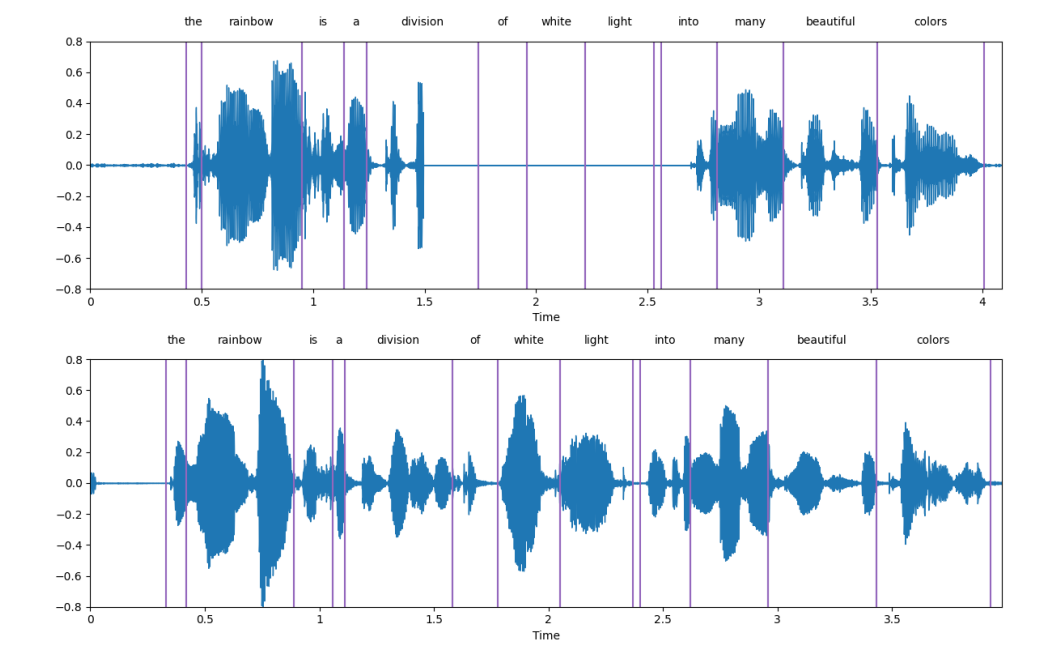
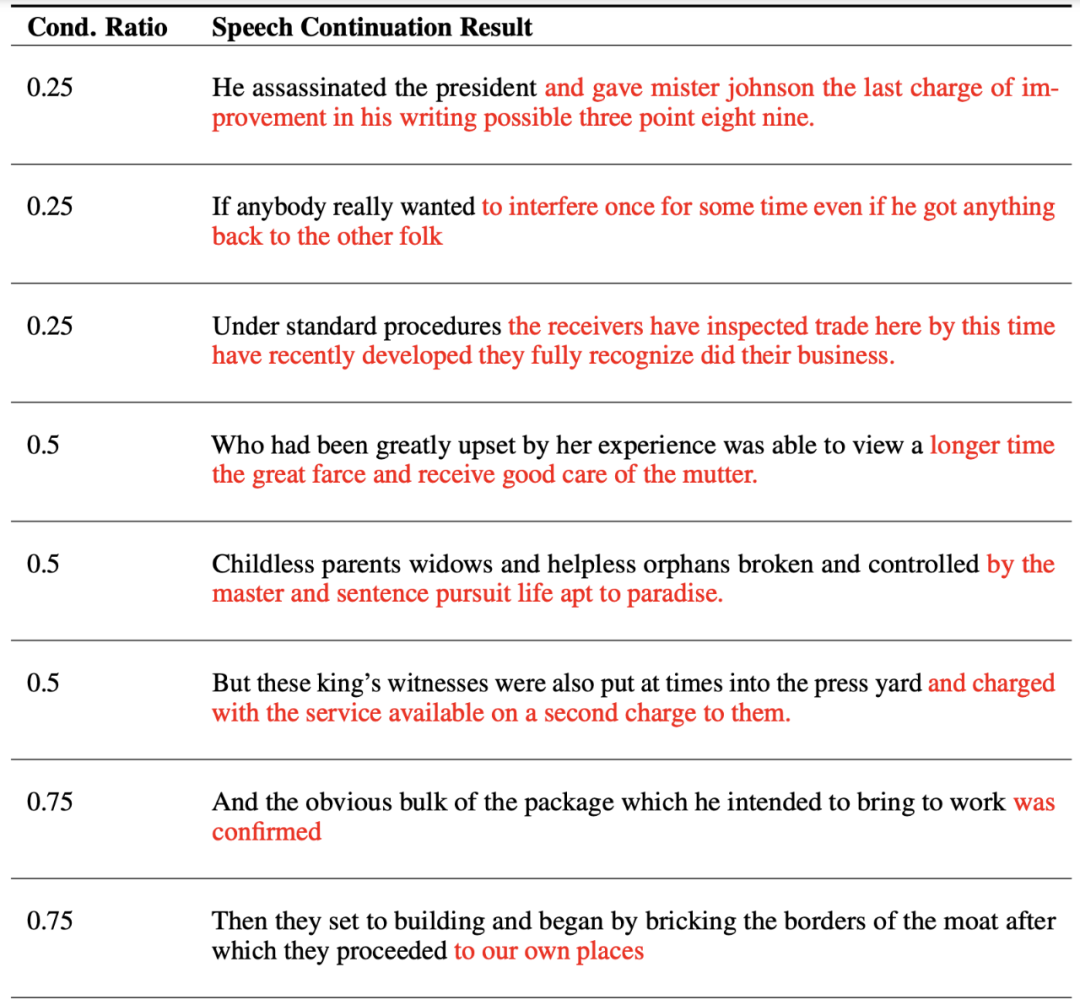
We will demonstrate the practical application of speech continuation using LJSpeech. During the training prompts, our strategy is to let the model only see a portion of the seed segment, which occupies a proportion of the total length of the speech. We refer to this as the condition ratio (r), allowing the model to continue generating subsequent speech.
Below are some instances, where the black text represents the seed segment, and the red text represents the sentences generated by SpeechGen (these sentences are first obtained through speech recognition. During training and inference, the model performs a speech-to-speech task without receiving any text information). Different condition ratios enable SpeechGen to generate sentences of varying lengths for coherence, completing a full sentence. From a quality perspective, the generated sentences are grammatically consistent with the seed segment and semantically related. However, the generated speech still fails to perfectly convey a complete meaning. We anticipate that this issue will be resolved in future, more powerful speech models.
Limitations and Future Directions
Speech language models and speech generation are in a thriving stage, and our framework provides a clever way to leverage powerful language models for speech generation. However, this framework still has some areas for improvement and many questions worth exploring.
1. Compared to text-based language models, speech language models are currently in the early stages of development. Although the prompt framework we proposed can stimulate speech language models to perform speech generation tasks, it does not achieve outstanding performance. However, with the continuous advancement of speech language models, such as the shift from GSLM to Unit mBART, the performance of prompts has significantly improved. Notably, tasks that were previously challenging for GSLM now perform better under Unit mBART. We expect more advanced speech language models to emerge in the future.
2. Beyond content information: Current speech language models cannot fully capture speaker and emotional information, which poses challenges for the current speech prompt framework in effectively handling these aspects. To overcome this limitation, we introduce plug-and-play modules specifically designed to inject speaker and emotional information into the framework. Looking ahead, we anticipate that future speech language models will integrate and utilize information beyond content to enhance performance and better address speaker and emotional aspects in speech generation tasks.
3. Possibilities of prompt generation: For prompt generation, we have flexible options to integrate various types of instructions, including text and image prompts. Imagine training a neural network to use images or text as input, rather than relying on pre-trained embeddings as prompts, as done in this article. This trained network would serve as a prompt generator, adding diversity to the framework. Such an approach would make prompt generation more interesting and colorful.
In this article, we explored using prompts to unlock the performance of speech language models across various generation tasks. We proposed a unified framework called SpeechGen, which has approximately 10M trainable parameters. The framework we proposed possesses several features, including textlessness, versatility, efficiency, transferability, and affordability. To demonstrate the capabilities of the SpeechGen framework, we conducted case studies using Unit mBART and experimented with three different speech generation tasks: speech translation, speech inpainting, and speech continuation.
When this paper was submitted to arXiv, Google introduced a more advanced speech language model—SPECTRON, showcasing the potential of speech language models in modeling information such as speaker and emotion. This is undoubtedly exciting news, and with the continuous emergence of advanced speech language models, our unified framework holds great potential.
© THE END
For reprints, please contact this public account for authorization
For submissions or inquiries: [email protected]
