
Source: DeepHub IMBA
This article is about 1600 words long and is recommended to be read in 5 minutes.
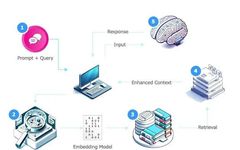
Retrieval-Augmented Generation is a technical approach aimed at enhancing the performance of large language models.
Overview of Retrieval-Augmented Generation (RAG) Technology
Retrieval-Augmented Generation (RAG) is a technical method aimed at enhancing the performance of Large Language Models (LLMs). The core idea is to improve the output quality of the model by integrating information from external reliable knowledge bases.
The working principle of RAG can be summarized as follows: when an LLM receives a query, it not only relies on its pre-trained knowledge but also actively retrieves relevant information from specified knowledge sources. This approach ensures that the generated output can reference a wealth of context-rich data and is supported by the latest, most relevant available information.
Core Components of RAG Systems
A standard RAG system mainly consists of three key components:
-
Retriever Component:
-
Function: Searches for highly relevant information related to the query topic within a knowledge base or large document collection.
-
How it works: Identifies documents that are semantically related to the query and calculates relevance using similarity measures (usually employing cosine similarity between vectors).
Generator:
-
Definition: Typically a large language model.
-
Input: Retrieved relevant information and the original query.
-
Output: Generates responses based on the input.
Knowledge Base:
-
Purpose: Serves as the data source for the retriever to find documents or information.
Workflow of RAG
-
Collect relevant information from external sources.
-
Append the collected information to the user’s original prompt.
-
Send the enhanced prompt as input to the language model.
-
During the generation phase, the LLM combines the enhanced prompt with its own training data representation to generate a response tailored to the user’s query.
The responses generated by this process integrate personalized and verifiable information, making it particularly suitable for applications such as chatbots.

Key Steps in Building a RAG System
-
Knowledge Base Preparation:
-
Indexing documents
-
Creating text embeddings
Retriever Model:
-
Train or fine-tune to effectively search the knowledge base
Generator Model:
-
Typically employs a pre-trained language model
System Integration:
-
Ensure seamless collaboration of all components
Introduction to Graph RAG Technology
Graph RAG is an advanced variant of the RAG method, characterized by the introduction of graph-structured data. Unlike viewing the knowledge base as a flat document collection, Graph RAG represents information as an interconnected network of entities and relationships.
Core Concepts of Graph RAG
Graph RAG is built on Knowledge Graphs (KGs). Knowledge graphs are structured representations of real-world entities and their relationships, mainly consisting of two basic elements:
-
Nodes: Represent individual entities such as people, places, objects, or concepts.
-
Edges: Represent the relationships between nodes, defining how entities are connected.
Compared to standard RAG, which uses vector similarity and vector databases for retrieval, Graph RAG leverages knowledge bases for more comprehensive and systematic information retrieval, thereby improving the completeness and accuracy of the retrieval.
Technical Advantages of Graph RAG
Graph RAG has the following significant advantages over standard RAG:
-
Capturing Relational Context:
Can capture and utilize complex relationships between information fragments, providing richer and more contextual information retrieval results.
-
Multi-hop Reasoning Capability:
The graph structure supports the system to reason along relationship chains, achieving more complex and deeper logical analysis.
-
Structured Knowledge Representation:
Compared to flat document structures, graph structures can more naturally represent hierarchical and non-hierarchical relationships, aligning more closely with the way knowledge is organized in the real world.
-
Improved Query Efficiency:
For query types involving relationship traversal, the graph structure can significantly enhance processing efficiency.

Workflow of Graph RAG
The workflow of Graph RAG can be summarized in the following key steps:
-
Query Processing:
Analyze and transform the input query to fit the query format of the graph structure.
-
Graph Traversal:
The system explores the graph structure, searching for connected information nodes along relevant relationship paths.
-
Subgraph Retrieval:
Unlike retrieving independent information fragments, the system extracts relevant subgraphs that contain interrelated contexts.
-
Information Integration:
Combines and processes the retrieved subgraphs to form a coherent and comprehensive set of contextual information.
-
Response Generation:
The language model generates the final response based on the original query and the integrated graph information.
Graph RAG Processing Flowchart

Key Differences Between Standard RAG and Graph RAG
-
Knowledge Representation Method:
-
Standard RAG: Adopts a flat document structure
-
Graph RAG: Uses a graph structure to represent knowledge
Retrieval Mechanism:
-
Standard RAG: Primarily relies on vector similarity search
-
Graph RAG: Employs graph traversal algorithms for information retrieval
Context Understanding Capability:
-
Graph RAG can capture more complex multi-step relationships that may be overlooked in standard RAG
Reasoning Capability:
-
The graph structure of Graph RAG supports deeper and more complex reasoning about interrelated information

Conclusion
The Graph RAG technology significantly enhances the capabilities of traditional RAG systems by introducing graph-structured knowledge representation and processing methods. It not only improves the accuracy and completeness of information retrieval but also provides stronger support for complex queries and multi-step reasoning. This approach shows clear advantages in tasks that require deep contextual understanding and complex relationship analysis.
With the continuous development of knowledge graph technology and graph databases, Graph RAG is expected to play an increasingly important role in various advanced AI applications, especially in areas requiring precise, comprehensive information retrieval and complex reasoning.
About Us
Data Hub THU, as a public account for data science, is backed by the Tsinghua University Big Data Research Center, sharing cutting-edge research dynamics in data science and big data technology innovation, continuously disseminating data science knowledge, striving to build a platform for gathering data talents, and creating China’s strongest big data group.

Sina Weibo: @Data Hub THU
WeChat Video Account: Data Hub THU
Today’s Headlines: Data Hub THU