Click the “MLNLP” above, and select “Star” to follow the public account
Heavyweight content delivered first-hand
Editor: Yizhen
https://www.zhihu.com/question/321088108
This article is for academic exchange and sharing. If there is any infringement, it will be deleted.
The author found an interesting question on Zhihu titled “Why can negative sampling in word2vec achieve results similar to softmax?” Below, I will share some insights from experts that may help your research.
High-Quality Answers on Zhihu:
Author:wzlhttps://www.zhihu.com/question/321088108/answer/659611684
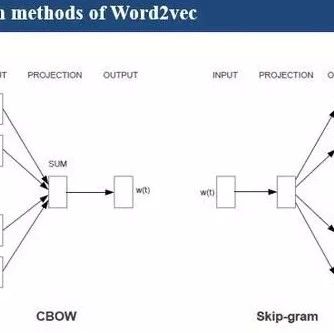
What does softmax do?

To explain simply,  represents the output token, which is the predicted word;
represents the output token, which is the predicted word;  represents the input token, which is the input word;
represents the input token, which is the input word;  represents the model under softmax;
represents the model under softmax;  represents the parameters. The word2vector under softmax includes
represents the parameters. The word2vector under softmax includes  which consists of two parts: one is the embedding layer, represented by the orange circle in the softmax structure, and the other is the softmax layer, represented by the green line in the softmax structure. Therefore, what softmax does is update the parameters to make the numerator of equation 1 larger and the denominator smaller, thereby increasing the probability of the predicted word.
which consists of two parts: one is the embedding layer, represented by the orange circle in the softmax structure, and the other is the softmax layer, represented by the green line in the softmax structure. Therefore, what softmax does is update the parameters to make the numerator of equation 1 larger and the denominator smaller, thereby increasing the probability of the predicted word.
So what about negative sampling?


 represents words that co-occur in a word window,
represents words that co-occur in a word window,  represents words that do not co-occur in a word window;
represents words that do not co-occur in a word window;  represents the Negative Sampling model;
represents the Negative Sampling model;  represents parameters. In Negative Sampling, there is only one parameter, which is the embedding layer;
represents parameters. In Negative Sampling, there is only one parameter, which is the embedding layer;  represents non-updatable parameters.
represents non-updatable parameters.
In simple terms, NS is a binary classification that increases the probability of words in the word window while decreasing the probability of words outside the word window. After three transformations, NS and softmax are very similar in form. Softmax aims to maximize the numerator  while minimizing the others’
while minimizing the others’  . NS also aims to maximize the numerator
. NS also aims to maximize the numerator  while minimizing the negative sampling tokens’
while minimizing the negative sampling tokens’  .
.
Therefore, it can be said that negative sampling is an approximation of softmax, not exactly the same. A comparison can be made between  and
and  . Thus, their results are quite similar.
. Thus, their results are quite similar.
Update:
2019-04-23: Modified some mathematical symbols that may cause ambiguity; added explanations of the model structure under two types of loss.
2019-04-26: Corrected some mathematical symbol errors.
References:
-
Mikolov T, Sutskever I, Chen K, et al. Distributed representations of words and phrases and their compositionality[C]//Advances in neural information processing systems. 2013: 3111-3119.
-
Mnih, A. and Teh, Y.W., 2012. A fast and simple algorithm for training neural probabilistic language models.arXiv preprint arXiv:1206.6426.
-
https://github.com/tmikolov/word2vec
Author:Towserhttps://www.zhihu.com/question/321088108/answer/665493824
To correct, negative sampling cannot achieve the same effect as softmax.
Negative sampling/NCE/softmax can all be used to train word vectors, but only the latter two can be used to train language models (where NCE is an asymptotic approximation of softmax). Negative sampling cannot.
As for why negative sampling can train word vectors, refer to other people’s answers.
Author:Cyberhttps://www.zhihu.com/question/321088108/answer/664752551
Let’s get a theoretical explanation. Softmax normalization is complex due to the large vocabulary. Theoretically, NCE approximates softmax, and experimental papers have proven that only sampling number k=25 is needed for equivalent effect, with a speedup of 45x. Negative sampling is a special case of NCE, occurring only when k equals the total vocabulary. In practice, the number of negative samples is very small, thus approximating NCE and softmax, while the negative sampling formula is simpler and widely used. Negative sampling improves training speed while ensuring detailed reading, making it a silver bullet for training many large-scale distributed models.
Author:Anticoderhttps://www.zhihu.com/question/321088108/answer/659144819
From the perspective of parameter updates, the objective is more reasonable for softmax, but since there is only one target word per sample, the weight update should make this word’s output value large while making others (negative samples) small. When using negative sampling, it is equivalent to partially selecting negative samples, keeping the positive sample the same, making its output large while the sampled negative samples’ output is made small.
The design of the loss is for parameter updates, so theoretically, these two methods should be equivalent in effect. However, the differences between these two methods become apparent, and the number of sampling methods should be quite important.

Recommended Reading:
Full refund for not getting an offer | Special training for programming tests and data competitions
From Word2Vec to Bert, discussing the past and present of word vectors (Part 1)
Chen Lijie, a PhD student from Tsinghua University, wins best student paper at a top theoretical computer science conference
