Authorized by WeChat account Data Mining Machine Cultivation Diary
Author | Mu Wen
This article is exclusively authorized for reprint by “Big Data Digest” and prohibits all other forms of reprint without the author’s permission.
Hello everyone, my name is Data Mining Machine, I dropped out of Royal Bruster University, I drink the strongest orange juice, and I am as persistent as I am in my pursuits.
Today, I will unveil the mysterious veil of Word2vec and delve into its essence.
Believe me, this is definitely the most straightforward and easy-to-understand summary of Word2vec in Chinese that you will ever see.
(Huh? You ask me why I have this confidence? Just look below, my pitfall history…)
Table of Contents
-
1. Summary of Word2vec Reference Materials
-
2. Main Text
-
2.1. What is Word2vec?
-
2.2. Skip-gram and CBOW Models
-
2.2.1 Simple Cases of Skip-gram and CBOW
-
2.2.2. More General Case of Skip-gram
-
2.2.3 More General Case of CBOW
-
2.3. Training Tricks of Word2vec
-
2.4. Extensions
-
3. Practical Application
1. Summary of Word2vec Reference Materials
Let me briefly describe my process of digging deep into Word2vec: I first followed the usual practice of reading Mikolov’s two original papers on Word2vec, but found that I was still confused after reading them; the main reason is that these two papers omitted too much theoretical background and derivation details. Then I dug out Bengio’s 2003 JMLR paper and Ronan’s 2011 JMLR paper, which helped me understand language models and using CNN for NLP tasks, but I still couldn’t fully grasp Word2vec. At this point, I began to read a lot of blogs in both Chinese and English, and one blog by Bei Piao Lang Zi attracted my attention; it systematically explained the background and details of Word2vec and provided an in-depth analysis of the implementation details in the code. After reading it, I understood many details but still felt some fog; finally, I saw someone recommending Xin Rong’s English paper on Quora, and after reading it, I felt enlightened, as if a light bulb had gone off, and it became my top recommendation for Word2vec reference materials. Below, I will list all the Word2vec-related reference materials I have read and provide evaluations.
-
Mikolov’s two original papers:
-
“Distributed Representations of Sentences and Documents”
-
Proposed a more concise language model framework based on previous work and used it to generate word vectors; this framework is Word2vec.
-
“Efficient estimation of word representations in vector space”
-
Specifically discusses two tricks in training Word2vec: hierarchical softmax and negative sampling.
-
Advantages: The pioneering work of Word2vec; both papers are worth reading.
-
Disadvantages: Only see the trees but not the forest and leaves; after reading, one does not grasp the essence. Here, the “forest” refers to the theoretical foundation of the Word2vec model—namely, the language model represented in the form of a neural network, and the “leaves” refer to the specific neural network forms, theoretical derivations, and implementation details of hierarchical softmax, etc.
Bei Piao Lang Zi’s blog: “Deep Learning Word2vec Notes – Basics”
-
Advantages: Very systematic, combined with source code analysis, language is straightforward and easy to understand.
-
Disadvantages: Too verbose, a bit hard to grasp the essence.
Yoav Goldberg’s paper: “Word2vec Explained – Deriving Mikolov et al.’s Negative-Sampling Word-Embedding Method”
-
Advantages: The derivation of the negative sampling formula is very complete.
-
Disadvantages: Not comprehensive enough, and it is all formulas without illustrations, which is a bit dry.
Xin Rong’s paper: “Word2vec Parameter Learning Explained”:
-
! Highly recommended!
-
The theory is complete, easy to understand, and directly hits the point; it has both high-level intuition explanations and detailed derivation processes.
-
You must read this paper! You must read this paper! You must read this paper!
Laise Wei’s doctoral dissertation “Research on Semantic Vector Representation Methods for Words and Documents Based on Neural Networks” and his blog (online name: licstar)
-
Can serve as more in-depth and comprehensive supplementary reading; it covers not only Word2vec but also all mainstream methods of word embedding.
Several experts’ answers on Zhihu: “What are the advantages of Word2vec compared to previous Word Embedding methods?”
-
Famous scholars such as Liu Zhiyuan, Qiu Xipeng, and Li Shaohua express their views on Word2vec from different angles, which is very worth a look.
Sebastian’s blog: “On word embeddings – Part 2: Approximating the Softmax”
-
It provides a detailed explanation of the approximation method for softmax; hierarchical softmax of Word2vec is just one of them.
2. Main Text
In this article, you will see:
-
A concise explanation of the theoretical essence of Word2vec.
-
How to train word vectors using gensim, find similar words, and optimize the model.
You will not see in this article:
-
The derivation of the neural network training process.
-
The theory and implementation details of tricks like hierarchical softmax/negative sampling.
2.1. What is Word2vec?
Before discussing Word2vec, let’s talk about NLP (Natural Language Processing). In NLP, the most granular unit is the word; words form sentences, sentences form paragraphs, and paragraphs form documents. Therefore, when addressing NLP problems, we must first tackle words.
For example, determining the part of speech of a word, whether it is a verb or a noun. Using a machine learning approach, we have a series of samples (x,y), where x is the word, and y is its part of speech. We want to construct a mapping f(x) -> y, but here the mathematical model f (such as a neural network or SVM) only accepts numerical input, while the words in NLP are human abstract summaries, represented in symbolic forms (such as Chinese, English, Latin, etc.), so we need to convert them into numerical forms, or in other words—embed them into a mathematical space. This embedding method is called word embedding, and Word2vec is a type of word embedding.
I mentioned in my previous work “It’s All a Trick: Understanding Time Series and Data Mining from God’s Perspective” that most machine learning models can be summarized as:
f(x) -> y
In NLP, if we consider x as a word in a sentence, y is the context words of that word. Then, in this case, f is the “topic model” that often appears in NLP, and the purpose of this model is to determine whether the sample (x,y) conforms to the laws of natural language. More colloquially, it is to see if words x and y together make sense.
Word2vec originates from this idea, but its ultimate goal is not to train f to perfection but to focus on the byproduct after the model is trained—the model parameters (specifically, the weights of the neural network), and use these parameters as a vectorized representation of input x, which is called the word vector (it’s okay if you don’t understand this now; we will analyze it in detail in the next section).
Let’s look at an example of how to use Word2vec to find similar words:
-
For the sentence: “They praise Wu Yanzu for being so handsome that he has no friends,” if input x is “Wu Yanzu,” then y can be “They,” “praise,” “handsome,” “no friends,” and so on.
-
Now consider another sentence: “They praise me for being so handsome that I have no friends.” If input x is “me,” it is not hard to see that the context y here is the same as in the previous sentence.
-
Thus, f(Wu Yanzu) = f(me) = y, so big data tells us: I = Wu Yanzu (a perfect conclusion).
2.2. Skip-gram and CBOW Models
We mentioned language models earlier.
-
If we use a word as input to predict its surrounding context, this model is called the “Skip-gram model.”
-
If we take the context of a word as input to predict the word itself, it is the “CBOW model.”
2.2.1 Simple Cases of Skip-gram and CBOW
Let’s first look at the simplest example. As mentioned above, y is the context of x, so when y only takes one word from the context, the language model becomes:
Use the current word x to predict its next word y.
But as mentioned above, general mathematical models only accept numerical input; how should we represent x here? Obviously, we cannot use Word2vec since that is the product of our trained model; what we want now is the original input form of x.
The answer is: one-hot encoder.
The so-called one-hot encoder is conceptually similar to how categorical variables are handled in feature engineering (refer to my previous work “General Framework for Data Mining Competitions” and “Deep Dive into the Secrets Behind One-hot and Dummy”). Essentially, it uses a vector containing only one 1 and the rest 0s to uniquely represent a word.
For example, assuming there are V words in total, and “Wu Yanzu” is the first word and “me” is the second word, then “Wu Yanzu” can be represented as a V-dimensional zero vector with the first position’s 0 changed to 1, and “me” can similarly be represented as a V-dimensional zero vector with the second position’s 0 changed to 1. In this way, each word can find its unique representation.
Now we can look at the network structure of Skip-gram; x is the input in the form of one-hot encoder mentioned above, and y is the probability output over these V words, which we hope matches the actual y’s one-hot encoder.
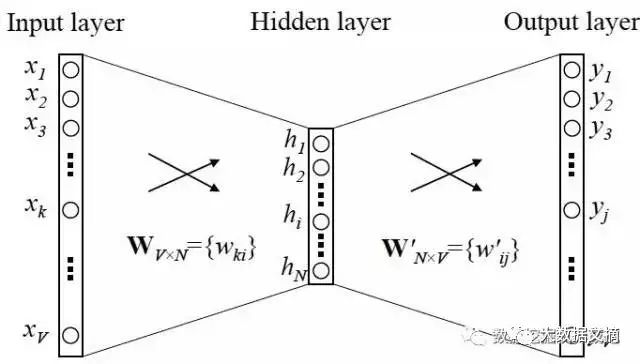
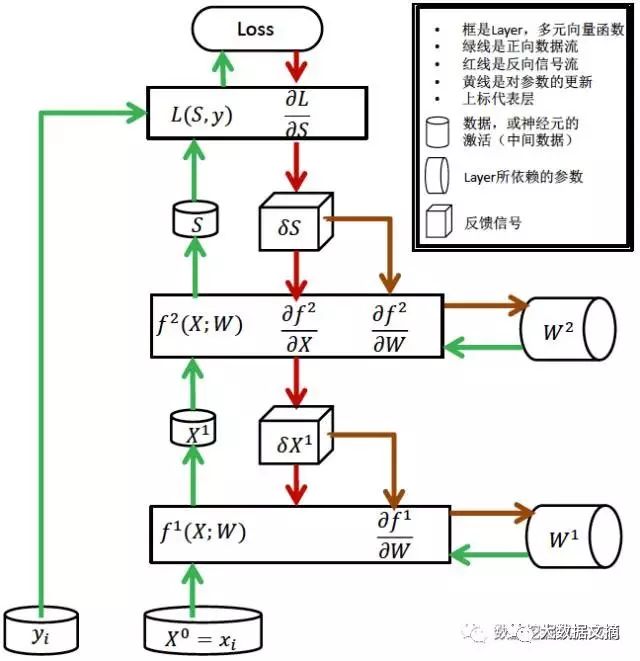
First, we need to train this neural network using the backpropagation algorithm, which is essentially chain rule differentiation; I won’t elaborate on that here, but I will give an intuitive illustration (you don’t need to understand this; it’s not the focus of this article, but the diagram is really well done, thanks to Dr. Xie from my company).
When the model is trained, the final output is actually the weights of the neural network. For example, if we input a one-hot encoder for x: [1,0,0,…,0], corresponding to the word “Wu Yanzu,” only the weight corresponding to the position of 1 in the input layer to the hidden layer is activated; the number of these weights corresponds to the number of hidden layer nodes, thus forming a vector vx to represent x. Since the position of 1 in the one-hot encoder of each word is different, this vector vx can uniquely represent x.
Note: The above statement captures the essence of Word2vec!
Additionally, we just mentioned that the output y is also represented using V nodes, corresponding to V words, so we can also set the output node to [1,0,0,…,0], which can also represent the word “Wu Yanzu,” but the weights activated are from the hidden layer to the output layer, and the number of these weights matches the hidden layer, thus forming a vector vy, which can be seen as another representation of the word vector for “Wu Yanzu.” The two word vectors vx and vy are what Mikolov referred to in the paper as the “input vector” and “output vector,” with the input vector being generally used.
It is worth mentioning that the dimension of this word vector (which is consistent with the number of hidden layer nodes) is generally much smaller than the total number of words V, so Word2vec is essentially a dimensionality reduction operation—reducing words from one-hot encoder form to Word2vec form.
2.2.2. More General Case of Skip-gram
The above discussion is the simplest case, where y has only one word. When y has multiple words, the network structure is as follows:

This can be seen as a parallel model of single x -> single y, with the cost function being the accumulation of individual cost functions (after taking the log).
If you want to delve into how these models are parallel and the form of the cost function, you might want to carefully read reference material 4. We won’t expand on this here.
2.2.3 More General Case of CBOW
Similar to Skip-gram, except:
Skip-gram predicts the context of a word, while CBOW predicts the word using the context.
The network structure is as follows:
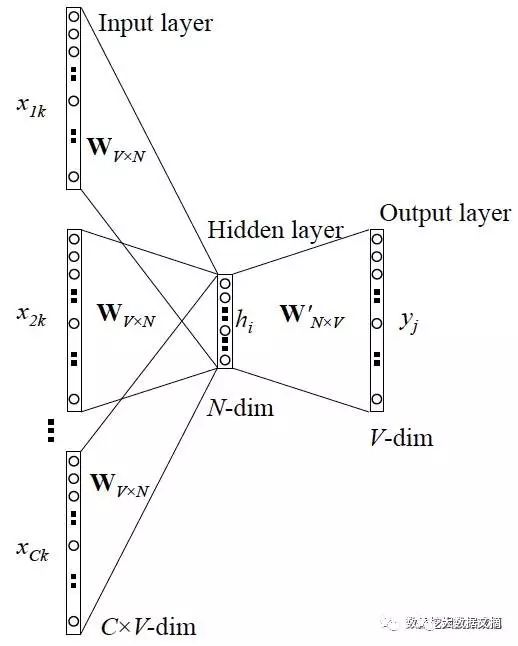
Unlike the parallel model of Skip-gram, here the input consists of multiple words, so it needs to be processed (generally summed and then averaged), while the output’s cost function remains unchanged; we won’t expand on this here, and it is recommended that you read reference material 4.
2.3. Training Tricks of Word2vec
Many beginners will find themselves trapped in the hierarchical softmax and negative sampling mentioned in Mikolov’s paper (reference material 1) just like I did, but in fact, they are not the essence of Word2vec; they are just training tricks, but they are not unique to it. Hierarchical softmax is just one approximate form of softmax (see reference material 7), and negative sampling is also borrowed from other methods.
Why use training tricks? As we just mentioned, Word2vec is essentially a model with V output nodes corresponding to V words, which is fundamentally a multi-classification problem. However, in practice, the number of words is extremely large, which poses significant computational challenges, so tricks are needed to speed up training.
Here, I summarize the essence of these two tricks,which can help everyone understand better; I won’t elaborate too much, and interested readers can delve into reference materials 1-7.
-
Hierarchical softmax
-
Essentially transforms an N-class classification problem into log(N) binary classification problems.
-
Negative sampling
-
Essentially predicts a subset of the overall categories.
2.4. Extensions
Many times, when we face a myriad of models and methods, we hope to summarize some essential, common elements to build our knowledge system. For example, in my previous work “The Essence of Classification and Regression,” I originally outlined the essential connections between classification models and regression models. In the field of word embedding, in addition to Word2vec, there are also word embedding methods based on co-occurrence matrix decomposition like GloVe.
Diving deeper, we find that models represented in the form of neural networks (like Word2vec) and co-occurrence matrix decomposition models (like GloVe) have theoretical similarities. Here I recommend reading reference material 5—Dr. Laise Wei proved in the appendix of his doctoral dissertation that the cost function of the Skip-gram model and GloVe is essentially the same. Isn’t that a very interesting conclusion? Therefore, in practical applications, the differences between the two are not significant, especially in many high-level NLP tasks (like sentence representation, named entity recognition, document representation), where word vectors are often used as raw inputs, and at the high-level layer, the differences become even smaller.
Given that words are the most granular expressions in NLP, the application of word vectors is very broad; they can be used for both word-level tasks and as inputs for many models to perform high-level tasks such as sentences and documents, including but not limited to:
-
Calculating similarity
-
Finding similar words
-
Information retrieval
-
As input for models like SVM/LSTM
-
Chinese word segmentation
-
Named entity recognition
-
Sentence representation
-
Sentiment analysis
-
Document representation
-
Document topic classification
3. Practical Application
After discussing so many theoretical details, in practical applications, you only need to call the interface of Gensim (a third-party Python library). However, exploring the theory is still necessary; it allows you to better understand the meaning of parameters, the factors that affect model results, and to apply this understanding to other problems.
Here we will use Gensim and NLTK to complete the task of finding similar words in the biomedical field, which will involve:
-
Interpreting the meanings of the parameters of the Word2vec model in Gensim
-
Training the Word2vec model based on the corresponding corpus and evaluating the results
-
Tuning the model results
The corpus has been provided; you can follow my WeChat account QR code and reply <span>Sherlocked</span> to obtain the corpus, which contains abstracts of 5000 lines of literature related to the biomedical field (in English).
I will detail the practical steps in the next article, so please stay tuned to my WeChat account. Friendly reminder: Please install the Gensim and NLTK libraries beforehand, and it is recommended to use Jupyter Notebook as the code execution environment.
Friendly reminder: Please install the Gensim and NLTK libraries beforehand, and it is recommended to use Jupyter Notebook as the code execution environment.
Data Mining Machine Cultivation Diary
WeChat ID: DataMiner_X

One Person, One Pen | “Panoramic Report” on Data Team Building

The Tsinghua Data Science Research Institute, in collaboration with Big Data Digest, has initiated a survey on data team building across all industries.This survey will assess the current state of data team development domestically and internationally and predict trends, while exploring how data teams should be built. We will combine a series of interviews and survey content to publish a “Panoramic Report on Data Team Building” in early July.
If you are part of a data team, work with a data team, or wish to learn about the development status and future of other data teams.
Then please take 5 minutes to click “Read the original text” to fill out the questionnaire and help us complete this survey.

Click the image to read the article
AI Learning Strategy for Math Newbies | Easy Introduction to Mathematical Symbols


