
Recurrent Neural Networks (RNN)
People do not start thinking from scratch every second, just as you do not relearn every word while reading this article; human thinking has continuity. Traditional Convolutional Neural Networks lack memory and cannot solve this problem, while Recurrent Neural Networks (RNNs) can address this issue. In RNNs, the cycle allows for the resolution of the memory deficit, as shown in the figure below:

At this point, you may still not understand why RNNs can have memory. Let’s unfold this diagram:
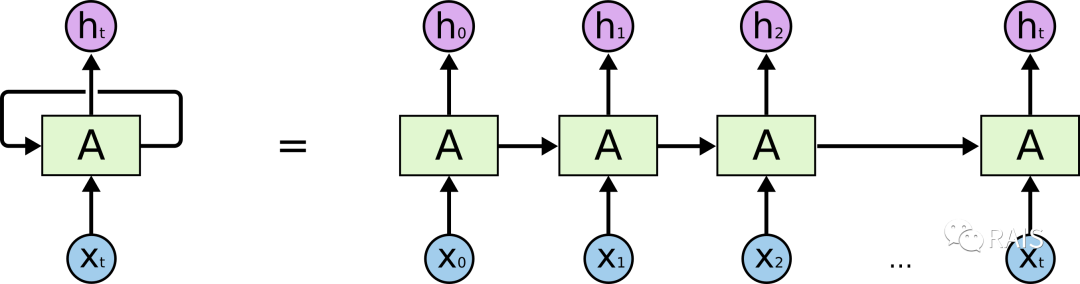
As we can see, after we input data, we first train to obtain output, and this output is passed to the next training iteration. Ordinary neural networks do not do this. When training on the current input, it includes both the input itself and the output from the previous training. The earlier training has an impression on the later one. Similarly, each subsequent training is influenced by the previous outputs (the influence on the current training is indirect).
Problems Encountered
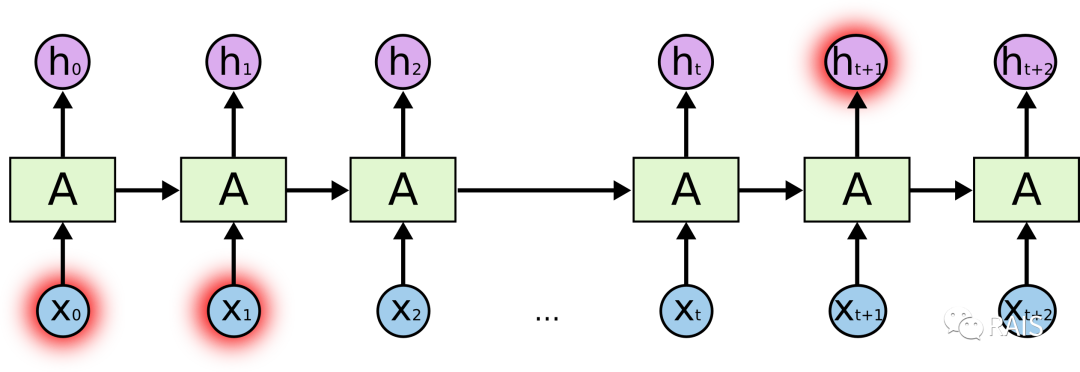
RNNs are very useful, but there are still some problems, mainly the inability to perform long-term memory. We can imagine (and there are papers proving this) that an earlier input, when transmitted over a long chain, has an increasingly smaller effect on later outputs. It’s as if the network has a certain memory capacity, but the memory lasts only about 7 seconds before being quickly forgotten. As shown in the figure, the influence of earlier inputs on later outputs becomes quite small (theoretically, this problem can be avoided by adjusting parameters, but finding the right parameters is very difficult and impractical, thus it can be approximated as unfeasible). The proposal of LSTM is to solve this problem.
LSTM
LSTM (Long Short Term Memory) is essentially a type of RNN, but the cycle (the A in the above figure) has been redesigned to solve the problem of insufficient memory duration. While other neural networks strive to adjust parameters to improve memory retention, LSTM inherently possesses a remarkable memory capability!
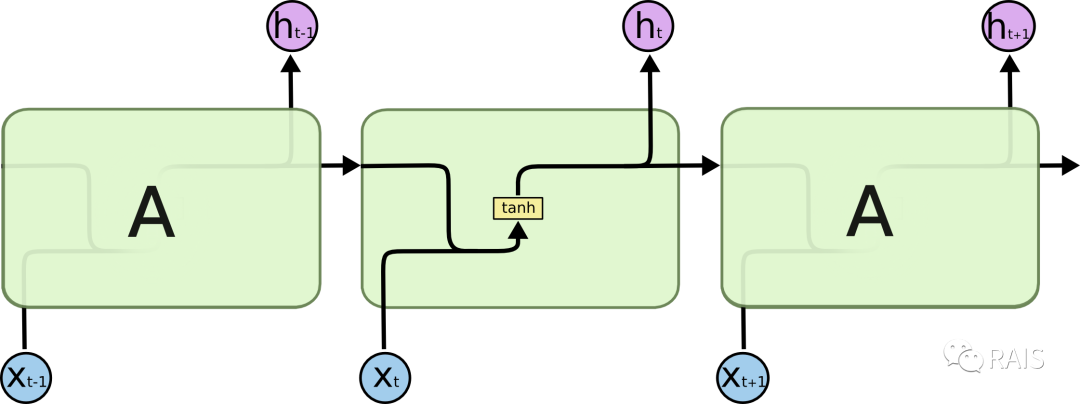
The A in a standard RNN is shown in the figure below, where the previous input and the current input undergo a computation, represented by tanh:
In contrast, the A in LSTM is significantly more complex. It is not a single neural network layer as in the previous figure, but consists of four layers, as shown below. It may seem a bit difficult to understand, but this is the content that requires careful analysis. Read on, and you will surely gain insights:
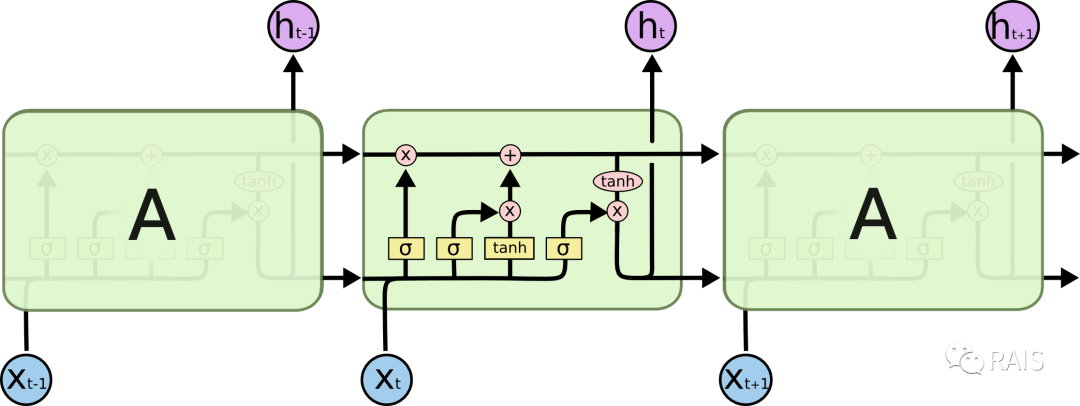
Let’s define some meanings of the figures: the yellow boxes represent simple neural network layers; the pink ones denote pointwise operations, such as addition and multiplication; there are also merge and split (copy) operations:

Core Idea
First, look at the highlighted part of the figure below. The output from the previous step can flow along this highway with almost no obstruction. What a simple and straightforward idea! Since we want to ensure that previous training is not forgotten, we will keep passing it along:
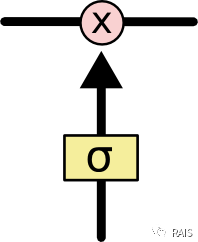
Of course, to make this transmission more meaningful, we need to introduce some gate controls. These gates are selective; they can allow complete passage, complete blockage, or partial passage. The S function (Sigmoid) can achieve this purpose, as shown in the simple gate below:
To summarize, we construct an LSTM network that has the capability to pass previous data to the end, enabling the network to have long-term memory while also incorporating gate controls to timely discard useless memories.
Detailed Analysis
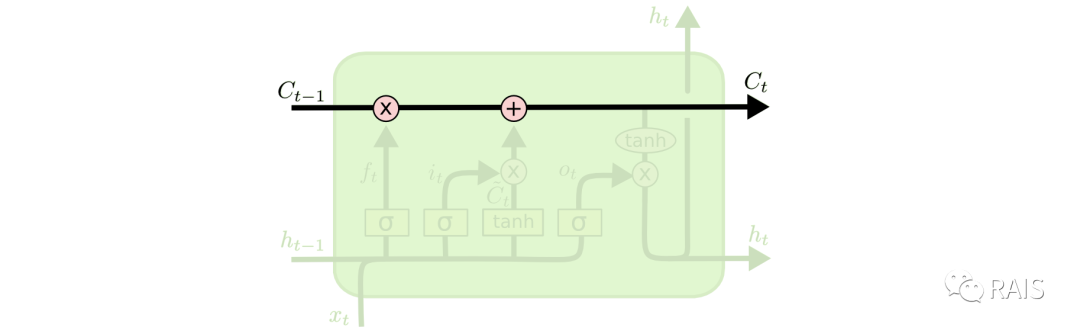
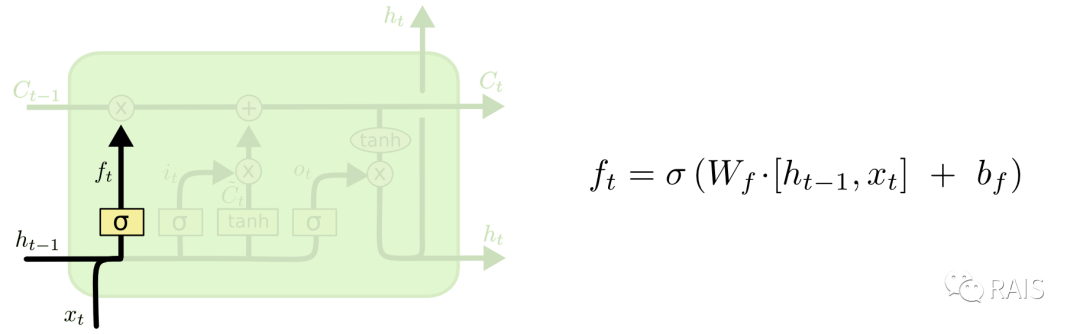
With this core idea, understanding the network becomes much simpler. From left to right, the first layer is the “selective forget” mechanism. We determine which memories from the previous output need to be retained or forgotten based on the current input using Sigmoid (the formula is on the right, and it does not support night mode reading):
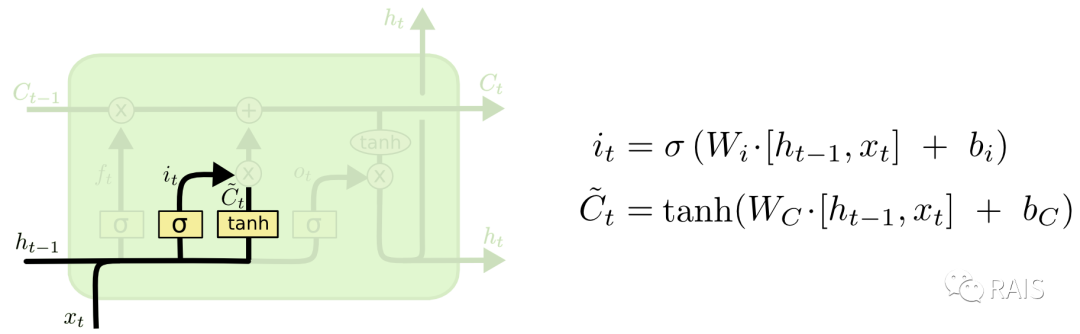
The second part is further divided into two sections: one is the “input gate layer,” which uses Sigmoid to decide which information needs to be updated, and the other part creates a candidate value vector, which represents the intermediate state after preliminary calculations of the current input and the last output:
After the previous calculations, we can update the cell state. The first step is to determine which data from the previous cell needs to be passed and which needs to be forgotten; the second step is to determine which data needs to be updated, and multiplying it by the intermediate state calculated this time gives us the updated data. Adding the results of the first two steps yields the new cell state, which can continue to be passed on.
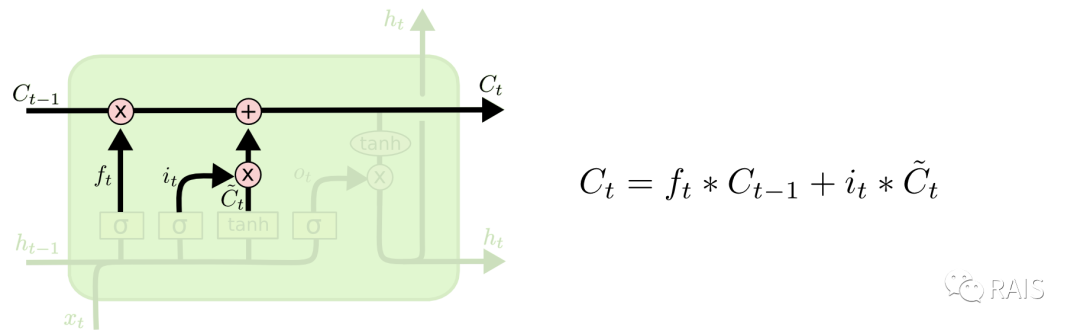
This step requires us to decide our output: first, we use Sigmoid to determine which part we need to output; second, we organize the cell state obtained from the previous calculations into a range from -1 to 1 using tanh; third, we multiply the results from the first and second steps to obtain the final output:
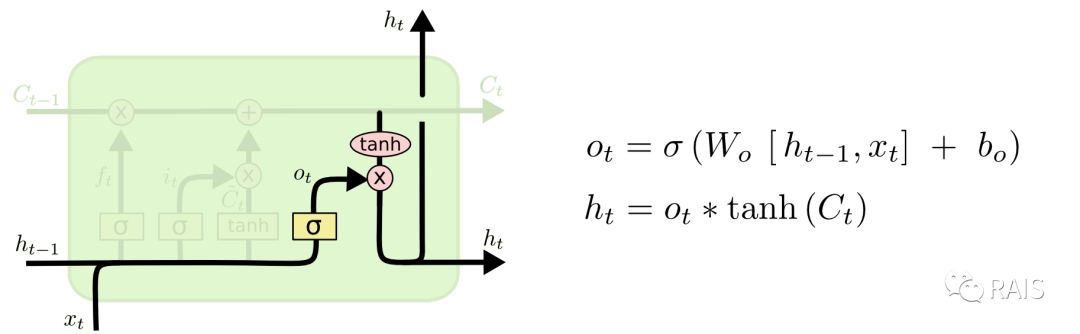
To summarize what we just did: we first determined which data from the previous cell state needed to be retained or discarded based on the current input and the last output. Then, we conducted network training based on the current input to further obtain the cell state and output for this training, and we continue to pass the cell state and this output forward.
There is a question: why is it necessary to discard? For example, when translating an article, the first paragraph introduces a person’s detailed information and background, while the next paragraph describes a story that happened today. The relationship between the two is weakly coupled, and it is necessary to promptly discard the memory of the background information to better translate the story that follows.
Other modified networks based on LSTM are essentially the same; they simply have certain parts connected differently. Papers have validated that, in general, the impact on training results is minimal. Here, we will not elaborate, as they are quite similar, focusing on improving core capabilities rather than on strange techniques:
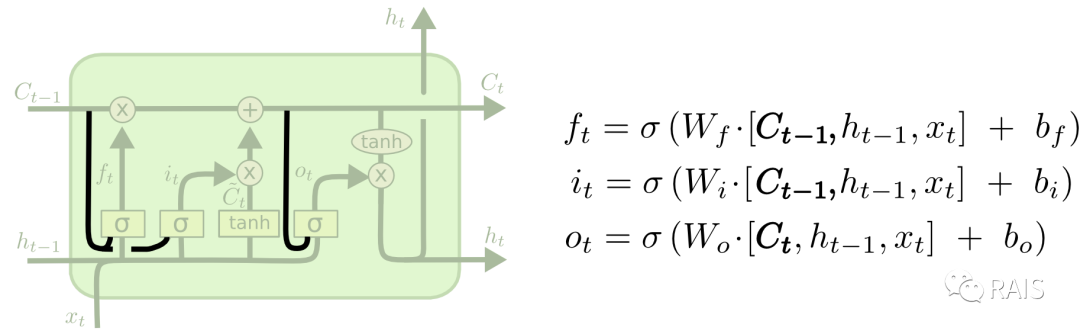
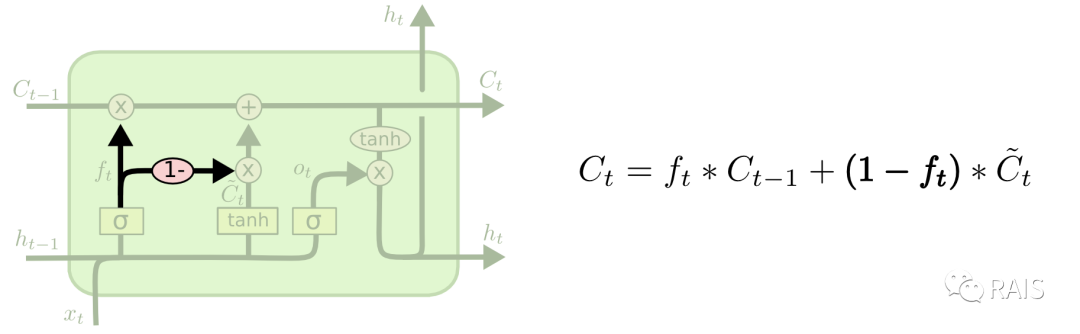

Conclusion
This article introduces Long Short Term Memory networks. In most cases, if RNNs achieve good results in a certain domain, it is likely that LSTM is being used. This is a great article, and the images in this article are sourced from Understanding-LSTMs, which is worth reading.