Question: I have looked through various materials and read the original papers, which detail how Q, K, and V are obtained through certain operations to produce output results. However, I have not found anywhere that explains where Q, K, and V come from. Isn’t the input of a layer just a tensor? Why are there three tensors: Q, K, and V?
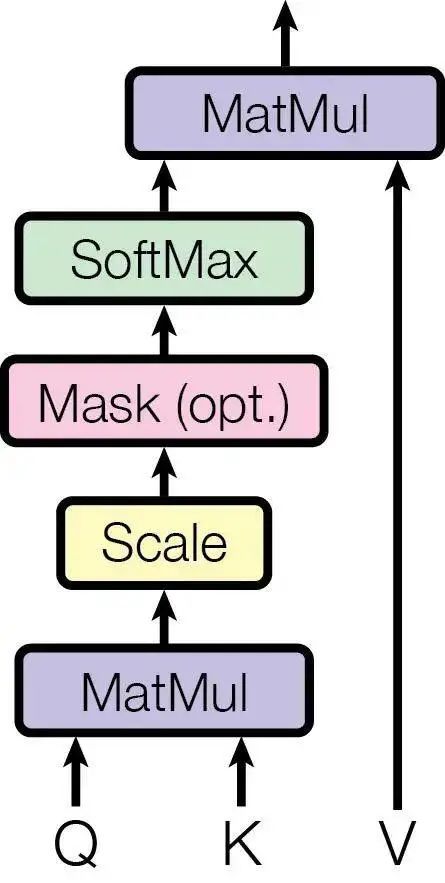
IIIItdaf’s Answer:
I work in CV, and while learning about Transformers, I also had this question when looking at QKV in Self-Attention. Why do we need to define three tensors? So I searched for this question. I feel that everyone has explained it well, but it could be stated more straightforwardly. I have a rough understanding; since drawing diagrams for answers is quite troublesome and I lack experience, I will simply share my understanding, which may not be accurate, and I ask for your forgiveness.
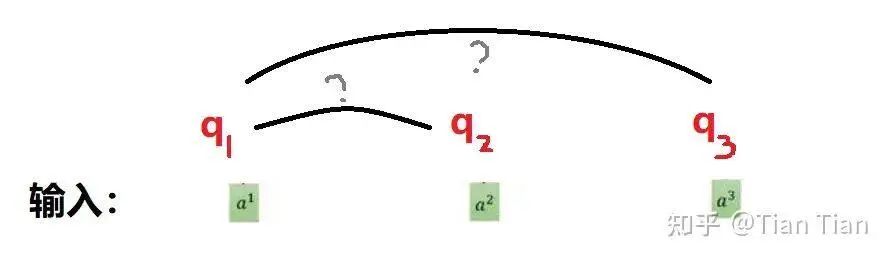
The attention mechanism is essentially about learning a weighting through training. The self-attention mechanism aims to find relationships between words through a weight matrix spontaneously. Therefore, it is necessary to define a tensor for each input and then use multiplication between tensors to find the relationships between inputs. So, is it enough to define just one tensor for each input? No, it is not! If each input only has one corresponding Q, then after multiplying Q1 and Q2 to find the relationship between a1 and a2, how do we store and use this result? Moreover, is the relationship between a1 and a2 reciprocal? What if there is a difference between a1 seeking a2 and a2 seeking a1? If we only define one tensor, isn’t this model a bit too simplistic?
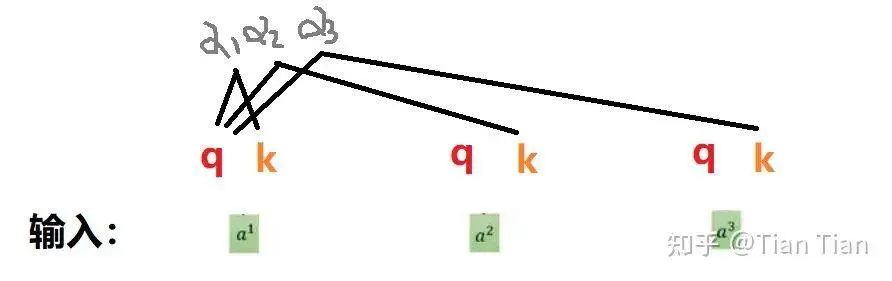
If one is not enough, then we define two, thus we have Q and K. You can understand Q as representing the self-use, using Q to find relationships with other inputs; K can be understood as being used by others, specifically for dealing with inputs that seek relationships with you. In this way, by multiplying your Q with others’ K (of course, you can also multiply with your own K), you can find the relationship: the weight α.
Is defining only Q and K sufficient? It may still not be enough. The relationships found need to be utilized; otherwise, they are meaningless. The weight α needs to be used to weight the input information to reflect the value of the relationships found. Can we directly weight the inputs? While this is possible, it seems a bit direct and rigid. Hence, we define V. It is important to note that V, like Q and K, is also obtained by multiplying the input a with a coefficient matrix. So, defining V roughly adds another layer of learnable parameters to a, and then we weight the adjusted a to apply the relationships learned through the attention mechanism. Thus, by multiplying α and V, we perform the weighting operation to finally obtain the output o.
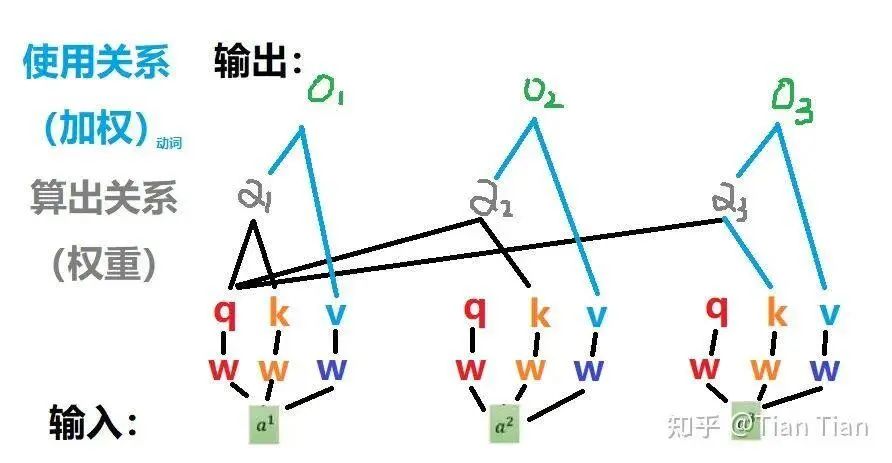
In summary, my feeling is that defining these three tensors serves two purposes: on one hand, to learn the relationships between inputs and find and record the weights of relationships between entities; on the other hand, it reasonably introduces learnable parameters within a structured framework, enhancing the network’s learning capability. The diagram below illustrates their relationships well, sourced from “Jishi Platform: Understanding Vision Transformer Principles and Code, This Technical Review Suffices”; please delete if infringing.

This is my rudimentary interpretation; please correct me if there are any inaccuracies. I will continue studying attention mechanisms…
This article is reprinted from Zhihu, and the copyright belongs to the original author; please delete if infringing.
