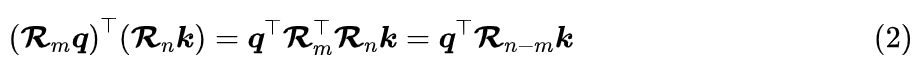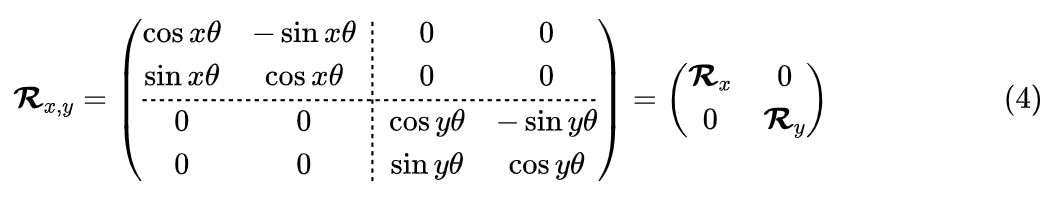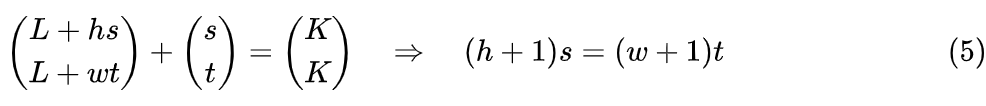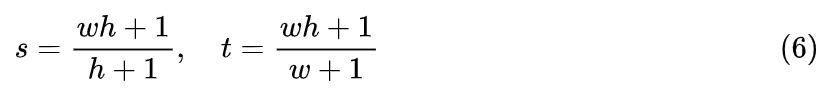In the second article of this series, “The Path of Transformer Upgrade: A Rotational Position Encoding that Draws on the Strengths of Many,” the author proposes Rotational Position Encoding (RoPE) — a method to achieve relative position encoding through absolute position representation. Initially, RoPE was designed for one-dimensional sequences such as text and audio (RoPE-1D), and later in “The Path of Transformer Upgrade: Rotational Position Encoding in Two Dimensions,” we extended it to two-dimensional sequences (RoPE-2D), which is applicable to images in ViT.
However, whether RoPE-1D or RoPE-2D, they share a common characteristic of being unimodal, meaning they are designed for pure text or pure image input scenarios. So how should RoPE be adjusted for multimodal scenarios, such as mixed text and image inputs?
The author searched and found that there are few works discussing this issue. The mainstream approach seems to be to flatten all inputs directly and treat them as one-dimensional inputs to apply RoPE-1D, making RoPE-2D quite rare. Not to mention whether this approach will become a bottleneck for performance as image resolution increases, it ultimately seems inadequate. Therefore, we will attempt to explore a natural combination of both.
Rotational Position
The term “rotational” in RoPE comes from the rotation matrix which satisfies:
This leads to the inner product for (assuming it is a column vector):
In the leftmost expression, it is performed independently, without involving the interaction of m and n, so it is formally an absolute position. However, the equivalent form on the right relies only on the relative position n-m, so when combined with Dot-Product Attention, it effectively behaves as a relative position.This feature also gives RoPE translational invariance: because (n+c) – (m+c) = n-m, if we add a constant to all absolute positions before applying RoPE, the attention result theoretically should not change (in practice, due to computational precision, there may be slight errors).The above is the form for , for (where d is even), we need a rotation matrix for , so we introduce different to construct a block diagonal matrix
From an implementation perspective, this means grouping into pairs and applying different for a two-dimensional rotation transformation. This is existing RoPE content, so I will not elaborate further. In principle, we only need to find a solution in the lowest dimension, which can be generalized to any dimension through block diagonal methods, so the following analysis will only consider the minimum dimension.
Two-Dimensional Position
When we talk about the concept of “dimension”, it can have various meanings. For instance, when we say , it means that are d-dimensional vectors. However, the focus of this article on RoPE-1D and RoPE-2D does not refer to this dimension but to the dimension required to record a position.
▲ Text and its Position ID
For example, to record the position of a certain token in text, we only need a scalar n, indicating it is the n-th token. But for images, even after patchifying, it usually retains width and height dimensions, so we need a pair of coordinates (x,y) to accurately encode the position of a patch:
▲ Image and its Position Coordinates
The previous section introduced , which only encoded a scalar n, so it is RoPE-1D. To handle image input more reasonably, we need to extend it to the corresponding RoPE-2D:
It is clear that this is just a block diagonal combination of , so it can naturally be extended to 3D or even higher dimensions. From an implementation perspective, it becomes simpler: it just splits into two halves (3D into three equal parts, 4D into four equal parts, and so on), with one half applying RoPE-1D for x and the other half applying RoPE-1D for y, and then they are combined.It should be noted that, for symmetry and simplicity, the constructed above uses the same for x and y, but this is not strictly necessary; in appropriate cases, we can configure slightly different for x and y.
Forced Dimensionality Reduction
Now we see that the position of text is a scalar n, while the position of an image is a vector (x,y), which are not consistent. Therefore, when handling mixed text and image inputs, we need some techniques to reconcile this inconsistency.The most direct solution, as mentioned at the beginning of the article, is to flatten the image into a one-dimensional vector sequence and then treat it as ordinary text, applying position encoding in the same way as for text.This approach is naturally very general, not limited to adding RoPE; it can also add any absolute position encoding. Existing multimodal models, such as Fuyu-8b, Deepseek-VL, Emu2, etc., seem to do this, although the details may vary. For example, when encountering patches in different rows, a special token representing [SEP] can be added to separate them:
▲ Text and images are flattened into one-dimensional sequences for processing
This solution also fits the current mainstream Decoder-Only architecture, as Decoder-Only means that even without position encoding, it is not permutation invariant. Therefore, we must specify what we think is the best input order, and since we need to specify the input order, using one-dimensional position encoding according to the specified order is a natural choice.Additionally, in the case of pure text, this model is no different from an ordinary pure text LLM, allowing us to continue training a pre-trained text LLM into a multimodal model.However, from my perspective, the concept of position encoding itself should not be tied to the use of Attention. It should be applicable to Decoder, Encoder, and any Attention Mask.On the other hand, maintaining the two-dimensionality of positions maximally preserves our prior knowledge about nearby positions. For example, we believe that positions (x+1,y) and (x,y+1) should be close to (x,y), but if we flatten (first horizontally, then vertically), (x,y) becomes xw + y, while (x+1,y) and (x,y+1) become xw+y+w and xw+y+1, respectively. The distance of the former depends on w, while the latter is fixed at 1.Of course, we can specify other orders, but no matter how we specify the order, it cannot completely accommodate the proximity of all neighboring positions; after all, with one less dimension, the expressible similarity is significantly reduced.
Unified Dimensionality Increase
From the perspective of vector space, a one-dimensional scalar can be viewed as a special two-dimensional vector. Therefore, compared to flattening into one dimension, if we instead unify all input positions to two dimensions, we theoretically have greater operational space.To achieve this, we can consider a common typesetting method: using images as separators to segment the text, treating continuous text as a line, while images are treated as multiple lines of text. Thus, the entire mixed text and image input can be regarded as a long multi-line document, where each text token or image patch has its own line number x and in-line order y, giving all input units (tokens or patches) a two-dimensional position (x,y).Therefore, we can uniformly use RoPE-2D (other 2D forms of position encoding theoretically can also be used) to encode positions while retaining the original two-dimensionality of image positions.
▲ Simulated typesetting to unify two-dimensional position coordinates
It is clear that the main advantage of this scheme is its intuitiveness; it directly corresponds to actual visual typesetting, making it easy to understand and promote. However, it also has a very apparent drawback: for pure text input, it cannot degrade to RoPE-1D but becomes RoPE-2D with x always equal to 1. This raises doubts about the feasibility of training a multimodal LLM starting from a pre-trained text LLM.Moreover, using images as dividing points may lead to excessive fragmentation of text when there are many images. This manifests as large fluctuations in the length of each text segment and forced line breaks in what should be continuous text, all of which may become performance bottlenecks.
Combining Two into One
If we want to preserve the position information of image patches without loss, then unifying to two-dimensional and using RoPE-2D (or other 2D forms of position encoding) seems to be the inevitable choice. Thus, the scheme from the previous section is already on the right track. What we need to further consider is how to allow it to degrade to RoPE-1D for pure text inputs, in order to be compatible with existing text LLMs.Firstly, we have already mentioned that is a block diagonal combination of and , so is a block diagonal combination of two s, while RoPE-1D’s is also a block diagonal combination of multiple different s.Thus, as long as we select different for x and y from , then can be viewed as part of RoPE-1D (i.e., ). Therefore, for RoPE-2D to degrade to RoPE-1D, the position of text should take the form (n,n) rather than specifying a line number in the way discussed in the previous section.Then, within the image, we use conventional RoPE-2D. For a single image with patches, its two-dimensional position coordinates flattened are:
If this image is located after a sentence of length L, the position encoding of the last token of this sentence would be (L,L), and thus the position encoding of the image following this sentence should be
However, this is not perfect, as the last token of the sentence has a position of (L,L) while the first patch of the image has a position of (L+1,L+1), which differs by (1,1). If another sentence follows this image, and the first token of that sentence has a position of (K,K), then the last patch of the image would be (L+h,L+w). When approaches infinity, no matter how we set K, it is impossible for (K,K) to differ from (L+h,L+w) by (1,1), indicating an asymmetry between the image and the sentences on either side, which is not elegant enough.To improve this, we can multiply the image’s x and y by positive numbers s and t:
As long as , this scaling is lossless for position information, so such an operation is permissible. After introducing the scale, if the last token of the sentence remains at (L,L), then the positions of the image patches would all add L. At this point, the difference between the position of the last token of the sentence and the position of the first patch of the image would be (s,t). If we want the difference between the position of the first token of the sentence following the image and the position of the last patch of the image to also be (s,t), we would need
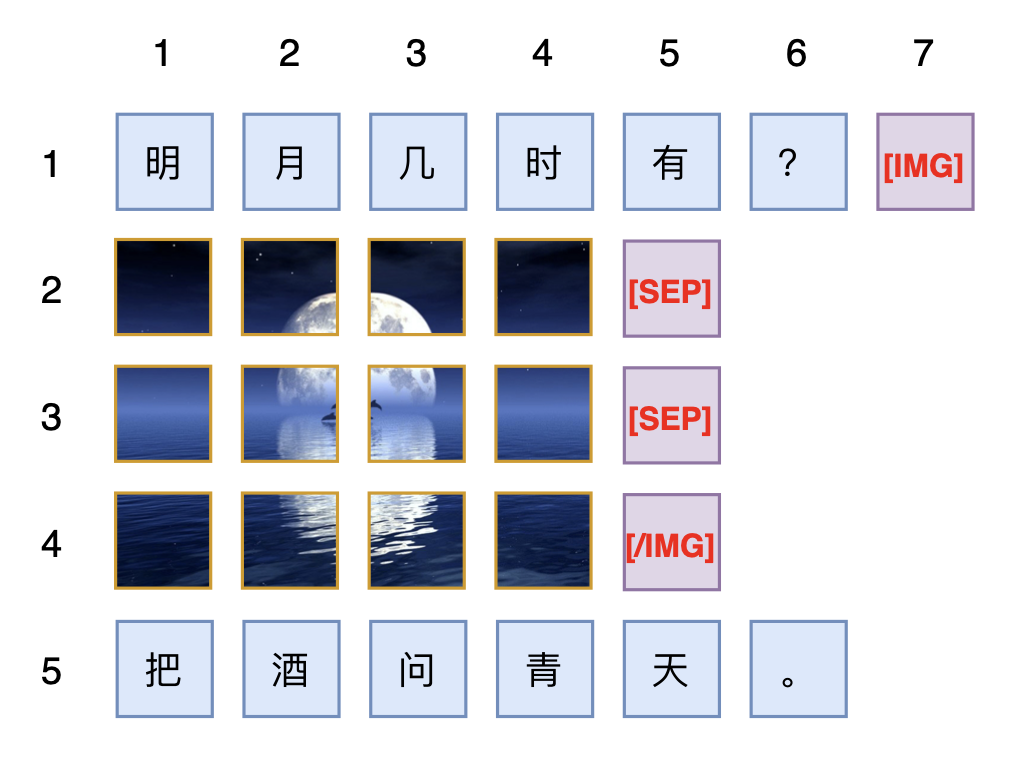
Considering the arbitrariness of h and w, and wishing to ensure that position IDs are all integers, the simplest solution is naturally s=w+1 and t=h+1. The position of the first token of the new sentence would then be K=L+(w+1)(h+1). A specific example is shown below:
▲ Supporting degradation to RoPE-1D for two-dimensional positions
Extended Thoughts
The position of the last token of the left sentence is L, while the position of the first token of the right sentence is K=L+(w+1)(h+1). If the middle part is also a sentence, we can deduce that this sentence has (w+1)(h+1)-1 tokens. This is equivalent to saying that if an image of size is placed between two sentences, then regarding the relative positions of these two sentences, it is equivalent to having a sentence with (w+1)(h+1)-1 tokens in between.This number seems a bit unnatural since it appears that wh is the perfect answer. However, this is the simplest solution to ensure that all position IDs are integers. If non-integer position IDs are allowed, we can agree that an image of size is equivalent to wh tokens, leading to
Some readers may ask: if two different-sized images are adjacent, is there no symmetric solution?This is not difficult; we can add special tokens before and after each image, such as [IMG] and [/IMG], and treat these special tokens as ordinary text tokens for position encoding. This directly avoids the situation of two images being adjacent (because according to the agreement, patches of the same image must be separated by [IMG] and [/IMG], treating these tokens as text, so it is equivalent to saying that each image must be separated by two texts).Additionally, the introduction above did not mention [SEP]; if needed, it can be introduced independently. In fact, [SEP] is only necessary when using a patch-by-patch autoregressive method for image generation; if images are simply used as input or generated with diffusion models, then [SEP] is redundant.Thus, we have completed the derivation of how to extend RoPE to mixed text and image inputs. If we need a name, we can call the final scheme “RoPE-Tie (RoPE for Text-image).” It must be said that the final RoPE-Tie is not very elegant, giving a somewhat “ornate” feeling.In terms of effectiveness, compared to directly flattening into one dimension using RoPE-1D, switching to RoPE-Tie does not necessarily yield any improvement; it is more of a product of the author’s perfectionism. Therefore, for multimodal models that have already scaled to a certain extent, there is no need for significant changes. However, if one has not yet started or is just beginning, it may be worth trying RoPE-Tie.
Article Summary
This article discusses how to combine RoPE-1D and RoPE-2D to better handle mixed input formats of text and images. The main idea is to support two-dimensional position indicators for images through RoPE-2D while imposing appropriate constraints to allow degradation to conventional RoPE-1D in pure text scenarios.
Further Reading
#Submission Channel#
Let Your Words Be Seen by More People
How can we allow more quality content to reach readers with a shorter path, reducing the cost for readers to find quality content? The answer is: people you don’t know.
There are always some people you don’t know who know what you want to know. PaperWeekly may serve as a bridge, facilitating the collision of scholars and academic inspirations from different backgrounds and directions, sparking more possibilities.
PaperWeekly encourages university laboratories or individuals to share various quality content on our platform, which can be latest paper interpretations, analysis of academic hotspots, research insights, or competition experience explanations, etc. Our goal is simple: to let knowledge truly flow.
📝 Basic Requirements for Submissions:
• The article must be an original work by the individual, not previously published in public channels. If it has been published or is pending publication on other platforms, please clearly indicate.
• Manuscripts are recommended to be written in markdown format. Images in the text should be sent as attachments, requiring clear images without copyright issues.
• PaperWeekly respects the author’s right to attribution and will provide industry-competitive remuneration for each accepted original submission, based on a tiered system depending on the article’s readership and quality.