
Original Author: Adam Kosiorek Annie, Translated from GitHub QbitAI | WeChat Official Account QbitAI
The attention mechanism in neural networks has garnered significant attention. In this article, I will attempt to find commonalities and use cases of different mechanisms, explaining the principles and implementations of two types of soft visual attention.
What is Attention?
In simple terms, the attention mechanism in neural networks is a network that can focus on its inputs (or features), allowing it to select specific inputs. We set the input as x∈Rd, the feature vector as z∈Rk, and a∈[0,1]k as the attention vector, with fφ(x) as the attention network. Generally, the implementation of attention is:
a=fφ(x)
or za=a⊙z
In the above equation [1], ⊙ represents the element-wise multiplication operation. Here we introduce the concepts of soft attention and hard attention; the former refers to the mask of values during multiplication being between 0 and 1, while the latter indicates that the mask of values is forced to be either 0 or 1, i.e., a∈{0,1}k. For the latter, we can use hard attention to mask the feature vector: za=z[a]. This increases its dimensionality.
To understand the importance of attention, we need to consider the essence of neural networks—they are function approximators. Depending on their architecture, they can approximate different types of functions. Neural networks are typically applied in chain matrix multiplication and corresponding element architectures, where inputs or feature vectors only interact during addition.
The attention mechanism can be used to compute masks for feature multiplication, an operation that greatly expands the function space that neural networks can approximate, enabling entirely new use cases.
Visual Attention
Attention can be applied to various types of inputs without considering their shapes. In the case of matrix-valued inputs like images, we introduce the concept of visual attention. Let the image be defined as I∈RH*W, and g∈Rh*w be the glimpse, which applies the attention mechanism to images.
Hard Attention
Hard attention in images has been applied for a long time, such as in image cropping. Its concept is simple and requires indexing. Hard attention can be implemented in Python and TensorFlow as:

The only issue with this form is that it is non-differentiable, and if we want to understand the model’s parameters, we must use aids like the score-function estimator.
Soft Attention
In the simplest variant of attention, soft attention for images is not much different from the vector-valued features implemented in equation [1]. The paper “Show, Attend and Tell: Neural Image Caption Generation with Visual Attention” records its early applications.
Paper link:
https://arxiv.org/abs/1502.03044

This model learns specific parts of images while generating language that describes those parts.
However, soft attention can be somewhat inefficient for computation. The masked parts of the input do not affect the result but still require computation. At the same time, it is also over-parameterized; the Sigmoid activation function used to implement attention is independent of each other. It can select multiple targets at once, but in practice, we usually want to selectively focus on one or a few elements in the scene.
Next, I will introduce two mechanisms, DRAW and Spatial Transformer Networks, to address the above issues. They can also adjust the size of the input, further enhancing performance.
DRAW introduction paper link:
https://arxiv.org/abs/1502.04623
Spatial Transformer Networks introduction paper link:
https://arxiv.org/abs/1506.02025
Gaussian Attention
Gaussian attention creates an attention map of the size of the image using a parameterized one-dimensional Gaussian filter. Define ay=Rh, ax=Rw as the attention vectors; the attention mask can be written as:


In the figure above, the top row represents ax, the rightmost column represents ay, and the middle rectangle represents a. To visualize the results, the vector contains only 0s and 1s. In practice, they can be implemented as one-dimensional Gaussian function vectors. Generally, the number of Gaussian functions is equal to the spatial dimensions, with each vector represented by three parameters: the center of the first Gaussian μ, the distance between the centers of the continuous Gaussian distributions, and the standard deviation σ of the Gaussian distribution. With these parameters, attention and glimpses become differentiable, and the learning difficulty is significantly reduced.
Since the above example can only select a part of the image, while the remaining image needs to be cleaned up, using attention also seems somewhat inefficient. If we do not directly use vectors, but instead choose to form them into matrices Ay∈Rh*H and Ax∈Rw*W, it may be better.
Now, each row of each matrix has a Gaussian, and the parameter d specifies the specific distance between the centers of the Gaussian distributions in consecutive rows. A glimpse can be represented as:

I applied this mechanism in a recent paper on object tracking using RNN attention, which is about HART (Hierarchical Attentive Recurrent Tracking).
Paper link:
https://arxiv.org/abs/1706.09262
Here is an example, with the left side showing the input image and the right side showing the attention, displaying a box on the main image in green.

The following code can create the above matrix-valued mask for small batch samples in TensorFlow. If you want to create Ay, you can call it Ay = gaussian_mask(u, s, d, h, H), where u, s, d represent μ, σ, and d, specified in pixels.
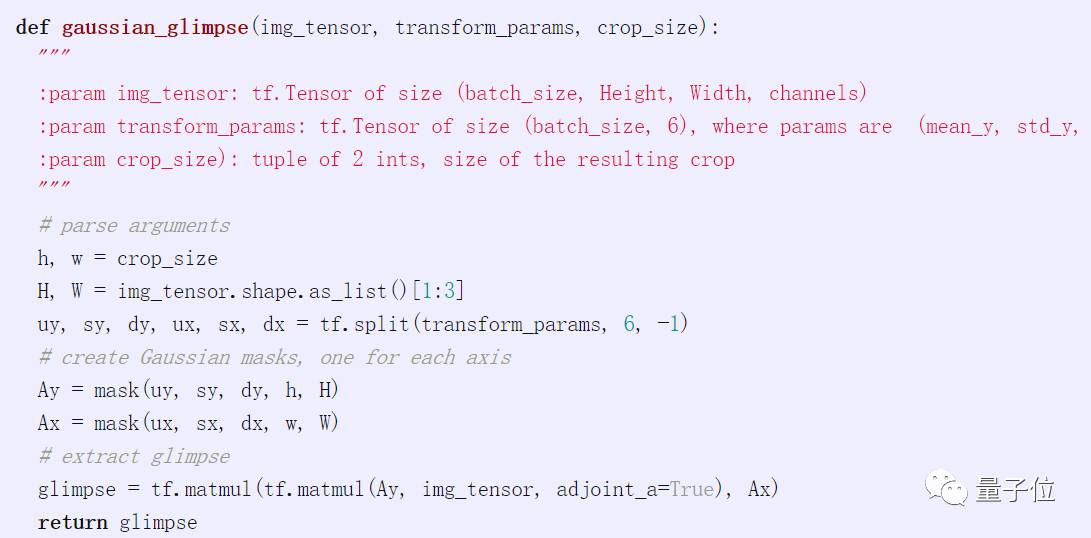
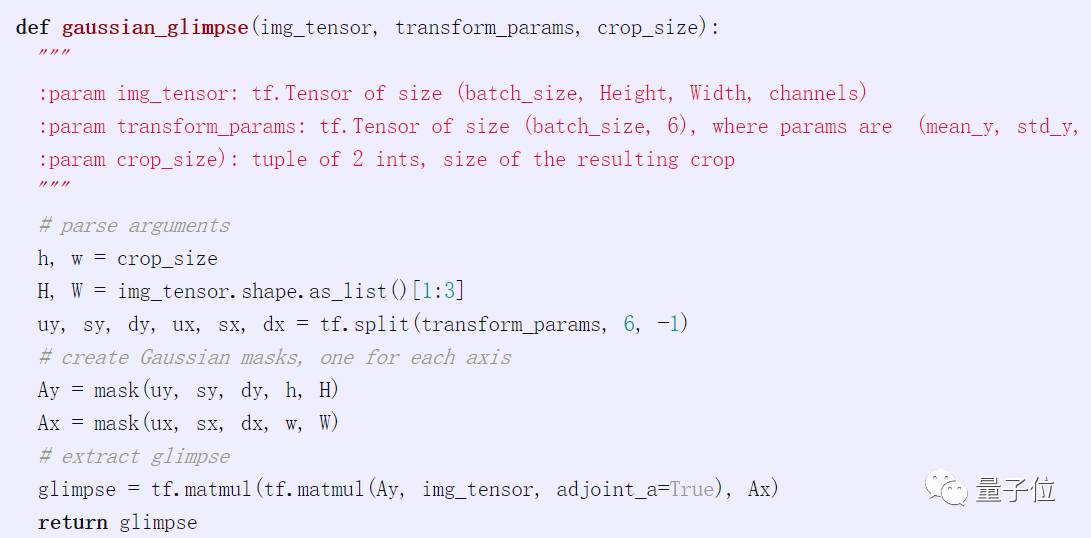
We can also write a function to directly extract an image from the input:
Spatial Transformer
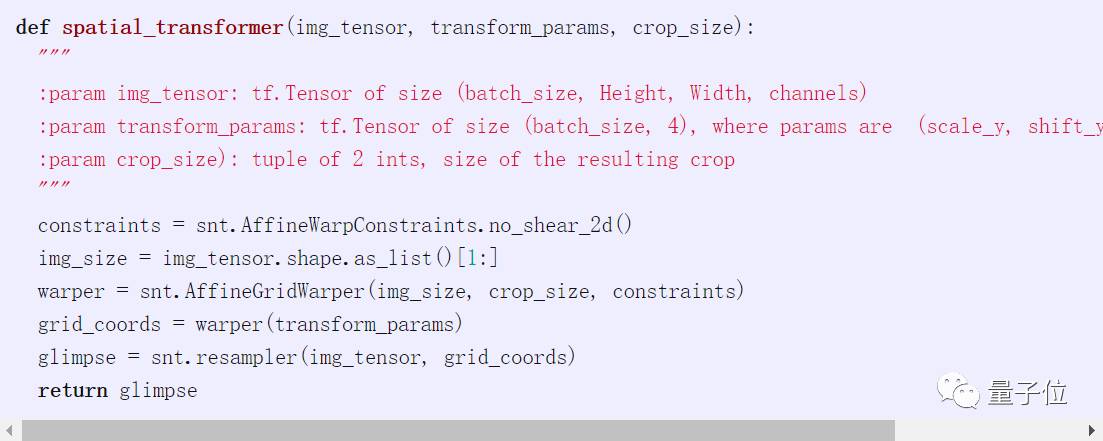
The Spatial Transformer (STN) allows for more general transformations, distinguishing image cropping. Image cropping is also a possible use case, consisting of two components: a grid generator and a sampler. The grid generator specifies the grid of points from which to sample, while the sampler takes the samples. In DeepMind’s recent neural network library Sonnet, it is very simple to implement using TensorFlow.
Gaussian Attention vs. Spatial Transformer
Gaussian Attention and Spatial Transformer exhibit similar behaviors; how do we decide which implementation to choose? Here are some subtle differences:
Gaussian attention is a hyperparameterized cropping mechanism that requires 6 parameters but only has 4 degrees of freedom (y, x, height, and width). STN only requires four parameters.
Currently, I have not run any tests, but STN should be faster. It relies on linear interpolation of sampling points, while Gaussian attention requires performing two matrix multiplications.
Gaussian attention should be easier to train. This is because each pixel in the resulting glimpse can be a convex combination of relatively large pixel blocks from the source image, making it easier to trace errors. On the other hand, STN relies on linear interpolation, where the gradient at each sampling point is non-zero only at the two nearest pixel points.
Conclusion
The attention mechanism extends the functionality of neural networks, allowing them to approximate more complex functions. Or in more intuitive terms, it can focus on specific parts of the input, improving performance on natural language benchmarks and enabling entirely new functionalities, such as image captions, addressing in memory networks, and neural programming.
I believe the most important use cases for attention have yet to be discovered. For example, we know that objects in videos are consistent and coherent; they do not suddenly disappear from frame to frame. The attention mechanism can be used to represent this consistency. As for its subsequent development, I will continue to pay attention.
— End —
Join the Community
The QbitAI AI community group 10 is now recruiting. Welcome students interested in AI to add the assistant WeChat qbitbot3 to join the group;
In addition, QbitAI’s specialized sub-groups (Autonomous Driving, CV, NLP, Machine Learning, etc.) are recruiting, aimed at engineers and researchers working in related fields.
To join the group, please add the assistant WeChat qbitbot3 and be sure to note the corresponding group’s keyword~ After passing the review, we will invite you to join the group. (The review for professional groups is stricter, thank you for understanding.)
Sincere Recruitment
QbitAI is recruiting editors/reporters, with the workplace in Zhongguancun, Beijing. We look forward to talented and passionate students joining us! For details, please reply with “Recruitment” in the dialogue interface of the QbitAI official account.

QbitAI QbitAI
վ’ᴗ’ ի Tracking AI technology and product news