Click on the above“Beginner’s Guide to Visuals”, choose to add a“Star” or “Pin”
Important insights delivered immediately
Perhaps the breakthrough in computer vision and machine learning over the past decade is the invention of GANs (Generative Adversarial Networks)—a method that introduces the possibility of generating content beyond what already exists in the data, serving as a gateway to a new field now referred to as generative modeling. However, after a phase of rapid development, GANs began to face a plateau, with most methods struggling to overcome some bottlenecks inherent to adversarial methods. This is not just an issue with a single method, but rather the adversarial nature of the problem itself. Some major bottlenecks of GANs include:
-
Lack of diversity in image generation
-
Mode collapse
-
Difficulty in learning multi-modal distribution problems
-
Excessive training time
-
Challenges in training due to the adversarial nature of the problem
There is also a long-standing series of likelihood-based methods (e.g., Markov Random Fields) that have failed to make a significant impact due to the complexity of implementation and formulation for each problem. One such method is the “diffusion model”—a method inspired by the physical process of gas diffusion, attempting to model the same phenomenon across multiple scientific fields. However, its application in image generation has recently become increasingly evident, primarily because we now have more computational power to test complex algorithms that were previously unfeasible.
A standard diffusion model has two main process domains: forward diffusion and reverse diffusion. In the forward diffusion phase, images are gradually corrupted with noise until they become completely random noise. In the reverse process, a series of Markov chains are used to gradually remove the predicted noise at each time step, recovering data from Gaussian noise.
 Diffusion models have recently shown significant performance in image generation tasks, outperforming GANs in tasks such as image synthesis. These models can also produce more diverse images and have been shown to be unaffected by mode collapse. This is due to the ability of diffusion models to retain the semantic structure of the data. However, these models have high computational requirements, and training requires very large memory, making it difficult for most researchers to even attempt this approach. This is because all Markov states need to be predicted continuously in memory, meaning multiple instances of large deep networks are kept in memory at all times. Additionally, the training time for these methods has become excessively long (e.g., days to months) because these models often get caught up in the fine-grained, hard-to-detect complexities of image data. However, it is important to note that this fine-grained image generation is also one of the main advantages of diffusion models, thus making their use somewhat paradoxical.
Another very well-known series of methods from the NLP domain is the transformer. They have been very successful in language modeling and building conversational AI tools. In visual applications, transformers demonstrate advantages in generalization and adaptability, making them suitable for general learning. They capture the semantic structure in text and even images better than other techniques. However, compared to other methods, transformers require large amounts of data and also face performance plateaus in many visual domains.
Diffusion models have recently shown significant performance in image generation tasks, outperforming GANs in tasks such as image synthesis. These models can also produce more diverse images and have been shown to be unaffected by mode collapse. This is due to the ability of diffusion models to retain the semantic structure of the data. However, these models have high computational requirements, and training requires very large memory, making it difficult for most researchers to even attempt this approach. This is because all Markov states need to be predicted continuously in memory, meaning multiple instances of large deep networks are kept in memory at all times. Additionally, the training time for these methods has become excessively long (e.g., days to months) because these models often get caught up in the fine-grained, hard-to-detect complexities of image data. However, it is important to note that this fine-grained image generation is also one of the main advantages of diffusion models, thus making their use somewhat paradoxical.
Another very well-known series of methods from the NLP domain is the transformer. They have been very successful in language modeling and building conversational AI tools. In visual applications, transformers demonstrate advantages in generalization and adaptability, making them suitable for general learning. They capture the semantic structure in text and even images better than other techniques. However, compared to other methods, transformers require large amounts of data and also face performance plateaus in many visual domains.
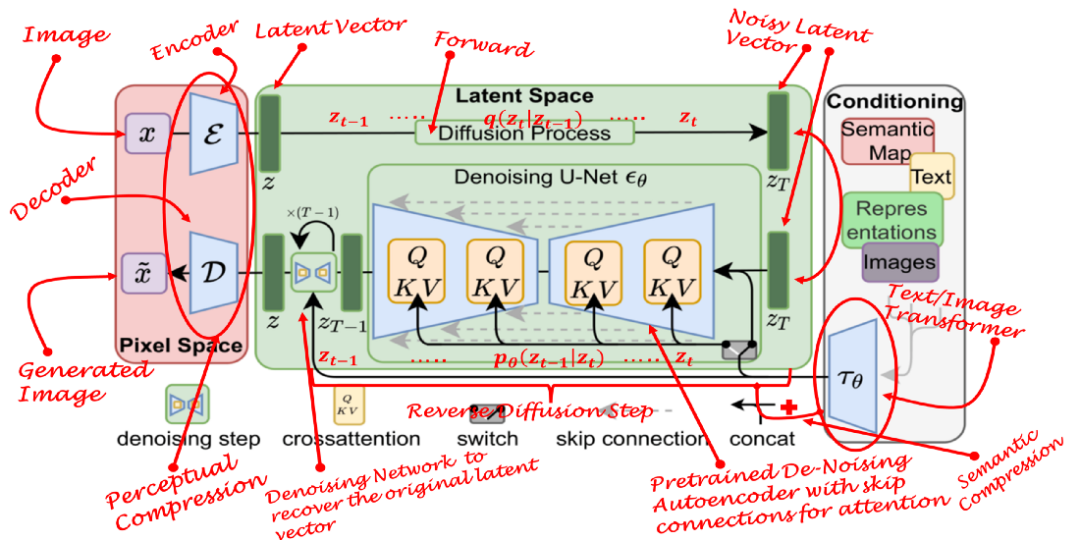
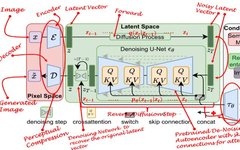
A recently proposed method combines the perceptual capabilities of GANs, the detail-preserving abilities of diffusion models, and the semantic capabilities of transformers, which the authors refer to as “Latent Diffusion Models” (LDM). LDM has proven to be more robust and efficient than all previously mentioned models. Compared to other methods, they not only save memory but also produce diverse, highly detailed images while retaining the semantic structure of the data. In short, LDM applies the diffusion process in latent space rather than pixel space, while incorporating semantic feedback from transformers.
Any generative learning method consists of two main stages: perceptual compression and semantic compression.
In the perceptual compression learning phase, the learning method must encapsulate the data into an abstract representation by removing high-frequency details. This step is necessary for constructing environment-invariant and robust representations. GANs excel at providing this perceptual compression. They achieve this by projecting high-dimensional redundant data from pixel space into a hyperspace known as latent space. The latent vectors in latent space are compressed forms of the original pixel images, effectively serving as substitutes for the original images.
More specifically, the autoencoder (AE) structure captures perceptual compression. In AEs, the encoder projects high-dimensional data into latent space, while the decoder recovers images from latent space.
In the second phase of learning, image generation methods must be able to capture the semantic structure present in the data. This conceptual and semantic structure preserves the context and relationships of various objects within the image. Transformers excel at capturing semantic structures in text and images. The combination of the generalization capabilities of transformers and the detail-preserving abilities of diffusion models offers the best of both worlds, providing the ability to generate fine-grained, highly detailed images while retaining the semantic structure within the images.
In LDM, the autoencoder captures the perceptual structure of the data by projecting it into latent space. The authors use a special loss function to train this autoencoder, known as “perceptual loss.” This loss function ensures that reconstruction is confined within the image manifold and reduces the blurriness that may arise when using pixel space loss (e.g., L1/L2 loss).
Diffusion models learn the data distribution by gradually removing noise from normal distribution variables. In other words, DMs adopt a reverse Markov chain of length T. This also means that DMs can be modeled as a series of T denoising autoencoders over time steps T = 1, …, T. This is represented by εθ in the equation. Note that the loss function depends on the latent vector rather than pixel space.
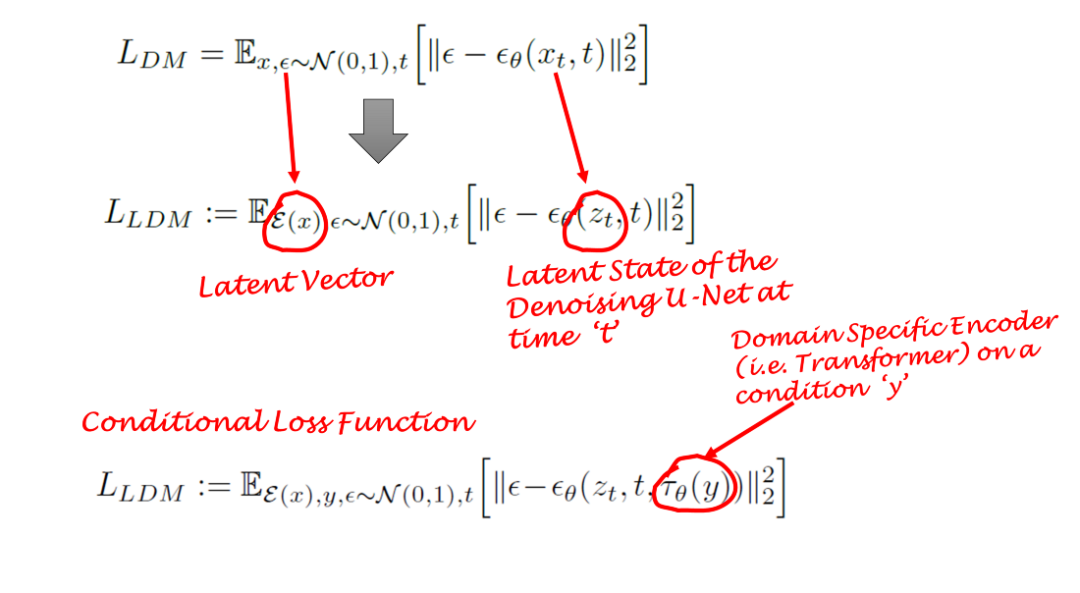
Diffusion models are conditional models that rely on priors. In image generation tasks, the prior is typically text, images, or semantic maps. To obtain the latent representation for this scenario, a transformer (e.g., CLIP) is used to embed text/images into latent vector ` τ `. Therefore, the final loss function depends not only on the latent space of the original image but also on the conditional latent embedding.
The backbone of LDM is a U-Net autoencoder with sparse connections that provides a cross-attention mechanism [6]. The transformer network encodes the conditional text/image into latent embeddings and then maps them to the intermediate layers of U-Net through cross-attention layers. This cross-attention layer implements attention (Q,K,V) = softmax(QKT/✔)V, where Q, K, and V are learnable projection matrices.
We use the latest official implementation of LDM v4 in Python to generate images. In text-to-image synthesis, LDM uses a pre-trained CLIP model [7], which provides transformer-based universal embeddings for various modalities such as text and images. The output of the transformer model is then input into LDM’s Python API ` diffusers `. There are also some parameters that can be adjusted (e.g., number of diffusion steps, seed, image size, etc.). Diffusion loss
The same setup applies to image-to-image synthesis; however, a sample image needs to be input as a reference image. The generated image is semantically and visually similar to the reference image. This process is conceptually similar to style-based GAN models, however, it performs better in retaining the semantic structure of the image.

We have introduced the latest developments in the field of image generation, known as Latent Diffusion Models. LDMs are robust in generating high-resolution images with fine details across different backgrounds while retaining the semantic structure of the images. Therefore, LDM represents an advancement in image generation, particularly in deep learning. If you are still curious about “Stable Diffusion Models,” it is simply a renaming of LDMs applied to high-resolution images, utilizing CLIP as the text encoder.
GitHub link: https://github.com/azad-academy/stable-diffusion-model-tutorial
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "OpenCV Extension Module Chinese Tutorial" in the backend of the "Beginner's Guide to Visuals" public account to download the first OpenCV extension module tutorial in Chinese, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Visual Practical Projects 52 Lectures
Reply "Python Visual Practical Projects" in the backend of the "Beginner's Guide to Visuals" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to assist in quickly learning computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the backend of the "Beginner's Guide to Visuals" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GANs, algorithm competitions, etc. (these will gradually be subdivided). Please scan the WeChat number below to join the group, with a note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Visual SLAM". Please follow the format for notes, otherwise, it will not be approved. After successful addition, you will be invited to join relevant WeChat groups based on your research direction. Please do not send advertisements in the group, or you will be removed from the group. Thank you for your understanding~