
In interpersonal communication, speech is one of the most natural and direct ways. With the advancement of technology, more and more people expect computers to have the ability to communicate verbally, which has led to increasing attention to voice recognition technology. Especially with the application of deep learning technology in voice recognition, the performance of voice recognition has significantly improved, making its widespread use a reality.

Voice Recognition Technology
Automatic speech recognition technology is simply a technology that uses computers to automatically convert speech signals into text. This technology is also the first and very important process for machines to understand human speech.
Voice recognition is an interdisciplinary field involving signal processing, pattern recognition, probability theory and information theory, vocal mechanisms, auditory mechanisms, artificial intelligence, and even human body language (such as facial gestures and actions that can help others understand when speaking). Its application areas are also very broad, such as voice input systems compared to keyboard input methods, voice control systems for industrial control, and intelligent dialogue query systems in the service sector. In today’s highly information-driven society, voice recognition technology and its applications have become an indispensable part of the information society.
Development History of Voice Recognition Technology
The research on voice recognition technology began in the 1950s. In 1952, Davis and others at AT&T Bell Labs successfully developed the world’s first experimental system capable of recognizing ten English digits: the Audry system.
The application of computers in the 1960s promoted the development of voice recognition technology, leading to two major research achievements: Dynamic Programming (DP) and Linear Prediction (LP), with the latter effectively solving the problem of speech signal generation models, which had a profound impact on the development of voice recognition technology.
In the 1970s, there were breakthrough advancements in the field of voice recognition. Linear Predictive Coding (LPC) technology was successfully applied to voice recognition by Itakura; Sakoe and Chiba applied the concept of dynamic programming to voice recognition and proposed the Dynamic Time Warping algorithm, effectively solving the problems of feature extraction and mismatched lengths of speech signals; they also proposed Vector Quantization (VQ) and Hidden Markov Model (HMM) theories. During this period, statistical methods began to be used to solve key problems in voice recognition, laying an important foundation for the subsequent maturity of large vocabulary continuous speech recognition technology for non-specific speakers.
In the 1980s, continuous speech recognition became one of the research focuses in voice recognition. Meyers and Rabiner developed the Level Building (LB) algorithm, a continuous speech recognition algorithm. Another significant development in the 1980s was that probabilistic statistical methods became the mainstream research method in voice recognition, characterized by the successful application of the HMM model in voice recognition. In 1988, Carnegie Mellon University (CMU) in the United States implemented a non-specific continuous speech recognition system SPHINX with 997 words using the VQ/HMM method. During this period, artificial neural networks were also successfully applied in voice recognition.
Entering the 1990s, with the arrival of the multimedia era, there was an urgent demand for voice recognition systems to transition from experimental to practical applications. Many developed countries, such as the United States, Japan, and South Korea, as well as renowned companies like IBM, Apple, AT&T, and NTT, invested heavily in the development and research of practical voice recognition systems. The most representative systems are IBM’s ViaVoice and Dragon’s Dragon Dictate, which have speaker adaptive capabilities, allowing new users to improve recognition rates without training on the entire vocabulary.
Currently, the United States takes a leading role in non-specific large vocabulary continuous speech recognition, while Japan leads in large vocabulary continuous speech neural network recognition and simulating artificial intelligence for speech post-processing.
China began researching speech technology in the late 1970s, but for a long time, it remained in a slow development phase. It wasn’t until the late 1980s that many domestic institutions, including the Institute of Acoustics, the Institute of Automation at the Chinese Academy of Sciences, Tsinghua University, Sichuan University, and Northwestern Polytechnical University, began to invest in this research. Most researchers focused on the theoretical research of speech recognition, as well as the study and improvement of models and algorithms. However, due to a late start and weak foundation, along with underdeveloped computer technology, China did not form its own characteristics in speech recognition research during the 1980s, nor did it achieve significant results or develop large-scale, high-performance experimental systems.
However, entering the 1990s, the pace of speech recognition research in China gradually caught up with international advanced levels. With the support of national science and technology projects such as the “Eighth Five-Year Plan” and “Ninth Five-Year Plan,” as well as the National Natural Science Foundation and the National 863 Program, China has achieved a series of results in the basic research of Chinese speech technology.
In the field of speech synthesis technology, iFlyTek has developed internationally leading core technologies; the Institute of Acoustics at the Chinese Academy of Sciences has also developed distinctive products based on long-term accumulation: in the field of speech recognition technology, the Institute of Automation at the Chinese Academy of Sciences has considerable technical advantages; the Institute of Linguistics at the Academy of Social Sciences also has a profound accumulation in Chinese linguistics and experimental language science. However, these achievements have not been well applied or transformed into industry; on the contrary, Chinese speech technology is facing increasingly severe challenges and pressures from international competitive environments in terms of technology, talent, and market.
Structure of Voice Recognition Systems
It mainly includes the sampling and preprocessing of speech signals, feature parameter extraction, the core part of speech recognition, and post-processing of speech recognition. The figure shows the basic structure of a voice recognition system.
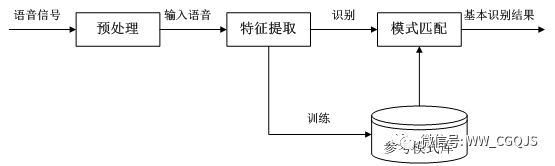
The process of voice recognition is a pattern recognition matching process. In this process, a voice model needs to be established based on human speech characteristics, analyzing the input speech signal and extracting the required features, thereby establishing the patterns needed for voice recognition. During the recognition process, the features of the input speech signal are compared with existing speech patterns based on the overall model of voice recognition, and a series of optimal matching patterns corresponding to the input speech are identified according to certain search and matching strategies. Then, based on the definitions of these pattern numbers, the recognition result can be obtained by looking up the table.
Classification of Voice Recognition Systems
According to the different recognition objects, voice recognition tasks can be roughly divided into three categories: isolated word recognition, keyword recognition (or keyword spotting), and continuous speech recognition.
The task of isolated word recognition is to recognize pre-known isolated words, such as “turn on” and “turn off”; the task of continuous speech recognition is to recognize any continuous speech, such as a sentence or a passage; while keyword detection in continuous speech targets continuous speech but does not recognize all words, only detecting the occurrence of known keywords, such as detecting the words “computer” and “world” in a passage.
Based on the targeted speaker, voice recognition technology can be divided into specific speaker recognition and non-specific speaker recognition. The former can only recognize the speech of one or a few individuals, while the latter can be used by anyone. Obviously, non-specific speaker recognition systems are more aligned with practical needs, but they are much more challenging than specific speaker recognition.
Additionally, based on the speech devices and channels, voice recognition can be classified into desktop (PC) voice recognition, telephone voice recognition, and embedded device (mobile phone, PDA, etc.) voice recognition. Different collection channels can distort the acoustic characteristics of human pronunciation, so recognition systems need to be constructed accordingly.
Types of Voice Recognition Technologies
Currently, representative voice recognition technologies mainly include Dynamic Time Warping (DTW), Hidden Markov Model (HMM), Vector Quantization (VQ), Artificial Neural Networks (ANN), and Support Vector Machines (SVM).
Dynamic Time Warping Algorithm (DTW)
is a simple and effective method in non-specific speaker voice recognition. This algorithm is based on the concept of dynamic programming and solves the problem of template matching with varying lengths of speech. When applying the DTW algorithm for voice recognition, the preprocessed and framed speech test signal is compared with the reference speech template to obtain their similarity, deriving the similarity between the two templates based on a certain distance measure and selecting the best path.
Hidden Markov Model (HMM)
is a statistical model in speech signal processing that evolved from Markov chains, making it a statistical recognition method based on parameter models. Since its model library is formed through repeated training to achieve the best model parameters that match the training output signals, rather than pre-stored pattern samples, and it uses the likelihood probability of the speech sequence to be recognized with the HMM parameters to reach the maximum value corresponding to the best state sequence as the recognition output, it is an ideal model for voice recognition.

Vector Quantization (VQ)
is an important signal compression method. Compared to HMM, vector quantization is mainly suitable for small vocabulary and isolated word speech recognition. The process involves forming a vector from several speech signal waveforms or scalar data of feature parameters for overall quantization in multi-dimensional space. The vector space is divided into several small regions, and a representative vector is sought for each small region. During quantization, vectors falling into small regions are replaced by this representative vector. The design of the vector quantizer involves training a good codebook from a large number of signal samples, finding good distortion measure definitions based on practical effects, and designing the best vector quantization system to achieve the maximum possible average signal-to-noise ratio with the least search and computation of distortion operations.
In practical applications, various methods to reduce complexity have been studied, including memoryless vector quantization, memory vector quantization, and fuzzy vector quantization methods.
Artificial Neural Networks (ANN)
is a new voice recognition method proposed in the late 1980s. It is essentially an adaptive nonlinear dynamic system that simulates the principles of human neural activity, possessing adaptability, parallelism, robustness, fault tolerance, and learning characteristics. Its powerful classification ability and input-output mapping capability are very attractive in voice recognition. Its method is an engineering model simulating the thought mechanism of the human brain, which is the opposite of HMM. Its classification decision-making ability and description ability for uncertain information are globally recognized, but its ability to describe dynamic time signals is still not satisfactory. Typically, MLP classifiers can only solve static pattern classification problems and do not involve time series processing. Although scholars have proposed many feedback structures, they are still insufficient to capture the dynamic characteristics of time series like speech signals. Due to the inability of ANN to adequately describe the temporal dynamic characteristics of speech signals, it is often combined with traditional recognition methods to leverage their respective advantages in voice recognition and overcome the shortcomings of both HMM and ANN.
In recent years, significant progress has been made in research on recognition algorithms that combine neural networks and hidden Markov models, with recognition rates approaching those of HMM recognition systems, further improving the robustness and accuracy of voice recognition.
Support Vector Machine (SVM)
is a new learning model based on statistical theory, employing the Structural Risk Minimization (SRM) principle to effectively overcome the shortcomings of traditional empirical risk minimization methods. It balances training error and generalization ability, demonstrating many superior performances in solving small sample, nonlinear, and high-dimensional pattern recognition problems, and has been widely applied in the field of pattern recognition.
Challenges and Countermeasures in Voice Recognition Technology
The development of voice recognition technology has not yet reached practical requirements, mainly reflected in the following aspects:
(1) Adaptability Issues.
The poor adaptability of voice recognition systems is manifested in a strong dependence on environmental conditions. Existing cepstral normalization techniques, relative spectrum (RASTA) techniques, and LINLOG RASTA techniques are adaptive training methods.
(2) Noise Issues.
When voice recognition systems are used in noisy environments, emotional or psychological changes in the speaker can lead to distorted pronunciation, changes in pronunciation speed and pitch, resulting in the Lombard effect. Common methods for noise suppression include spectral subtraction, environmental adaptation techniques, not correcting the speech signal but adjusting the recognizer model to fit the noise, and establishing noise models.
(3) Selection of Recognition Units.
Generally, the larger the vocabulary to be recognized, the smaller the units used should be.
(4) Endpoint Detection.
Endpoint detection of speech signals is the critical first step in voice recognition. Research shows that even in quiet environments, more than half of the recognition errors in voice recognition systems come from endpoint detectors. Improving endpoint detection technology hinges on finding stable speech parameters.
(5) Other issues include recognition speed problems, rejection issues, keyword detection technologies (i.e., removing filler words like “uh” and “ah” from continuous speech to obtain the actual speech parts for recognition), and the inability to respond correctly to user input errors.
Applications of Voice Recognition
Voice recognition can be applied in five main categories:
Office or business systems. Typical applications include filling out data forms, database management and control, enhancing keyboard functions, etc.
Manufacturing.
In quality control, voice recognition systems can provide a “hands-free” and “eyes-free” inspection of the manufacturing process (component checks).
Telecommunications.
A wide range of applications is feasible in dial phone systems, including automation of operator-assisted services, international and domestic remote e-commerce, voice call distribution, voice dialing, and classified ordering.
Medical.
The main application in this area is generating and editing professional medical reports through voice.
Others.
This includes voice-controlled games and toys, voice recognition systems assisting the disabled, and voice control of some non-critical functions in vehicles, such as in-vehicle traffic condition control systems and audio systems.
With the continuous development of mobile internet technology, especially the trend of miniaturization and diversification of mobile terminals, voice recognition has become one of the human-computer interaction means distinct from keyboards and touch screens. With the strengthening of voice recognition algorithm models and adaptability, it is believed that for a long time in the future, the application of voice recognition systems will become more widespread and in-depth, and more rich mobile terminal voice recognition products will enter people’s daily lives.
SourceSensor Technology

Previous Articles
Open Access | Measurement and Control Technology, Vol. 39, Issue 8, 2020, Special Issue on Machine Vision Technology
Open Access | Measurement and Control Technology, Vol. 39, Issue 12, 2020, Special Issue on Artificial Intelligence and Testing Assurance
Paper Recommendation | “Measurement and Control Technology” April Online First Papers
Paper Recommendation |“Measurement and Control Technology” 2020 Collection of Excellent Papers in Aerospace Field
Paper Recommendation |“Measurement and Control Technology” 2020 Collection of Excellent Papers in Computer and Automation Technology Field
Paper Recommendation | “Measurement and Control Technology” May 2021 Online First Paper Collection
[Forum] Academician Gao Jinjie: Intelligent Monitoring of Vibration Failures in Aero Engines
Academician Tan Jiubin: The Core Key is Solving the Problem of Ultra-Precision Measurement Capability
Article Recommendation | Design of an Intelligent Satellite Power Distribution Testing System
Article Recommendation | A Testing Method for Helicopter Rotor Vibration
Article Recommendation | Research on Fault-Tolerant Control of CNC Systems for Aero Engines
Article Recommendation | Research on the Application of Digital Phase-Locked Amplifiers in Atmospheric Transmission Instruments
Article Recommendation | Design and Application of an Anti-Icing Total Pressure/Static Pressure Probe Structure and Control System
Article Recommendation | Sun Zhiyan: Overview of the Development of Aero Engine Control Systems

