
The Machine Heart Column
The Machine Heart Editorial Team
The PreFLMR model is a general-purpose pre-trained multimodal knowledge retriever that can be used to build multimodal RAG applications. The model is based on the Fine-grained Late-interaction Multi-modal Retriever (FLMR) published at NeurIPS 2023 and has undergone model improvements and large-scale pre-training on M2KR.

- Paper link: https://arxiv.org/abs/2402.08327
- DEMO link: https://u60544-b8d4-53eaa55d.westx.seetacloud.com:8443/
- Project homepage link: https://preflmr.github.io/
- Paper title: PreFLMR: Scaling Up Fine-Grained Late-Interaction Multi-modal Retrievers
BackgroundDespite the strong general image-text understanding capabilities demonstrated by multimodal large models (e.g., GPT4-Vision, Gemini, etc.), they still perform poorly when answering questions that require specialized knowledge. Even GPT4-Vision cannot answer knowledge-intensive questions (as shown in Figure 1), which has become a bottleneck for many enterprise-level applications.
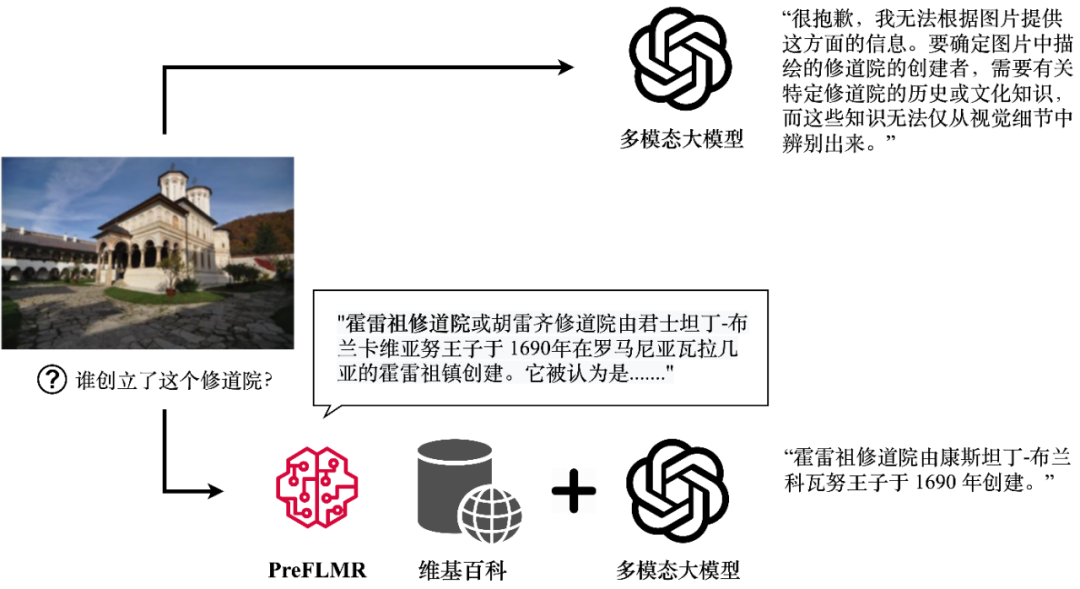
Figure 1: With the help of the PreFLMR multimodal knowledge retriever, GPT4-Vision can obtain relevant knowledge and generate correct answers. The figure shows the model’s actual output.To address this issue, Retrieval-Augmented Generation (RAG) provides a simple and effective solution to enable multimodal large models to become “domain experts”: first, a lightweight Knowledge Retriever obtains relevant specialized knowledge from professional databases (e.g., Wikipedia or enterprise knowledge bases); then, the large model takes this knowledge and the question as input to generate accurate answers. The knowledge “recall capability” of the multimodal knowledge extractor directly determines whether the large model can obtain accurate specialized knowledge when answering reasoning tasks.Recently, the Artificial Intelligence Laboratory of the Department of Information Engineering, University of Cambridgefully open-sourced the first pre-trained, general-purpose multimodal late-interaction knowledge retriever PreFLMR (Pre-trained Fine-grained Late-interaction Multi-modal Retriever). Compared to previous common models, PreFLMR has the following characteristics:1. PreFLMR is a general-purpose pre-trained model that can solve multiple sub-tasks such as text-to-text retrieval, image-text retrieval, and knowledge retrieval. After pre-training on millions of multimodal data, this model has achieved excellent performance in various downstream retrieval tasks. Additionally, as an excellent base model, PreFLMR can achieve outstanding performance with just a little training on private data to become a domain-specific model.
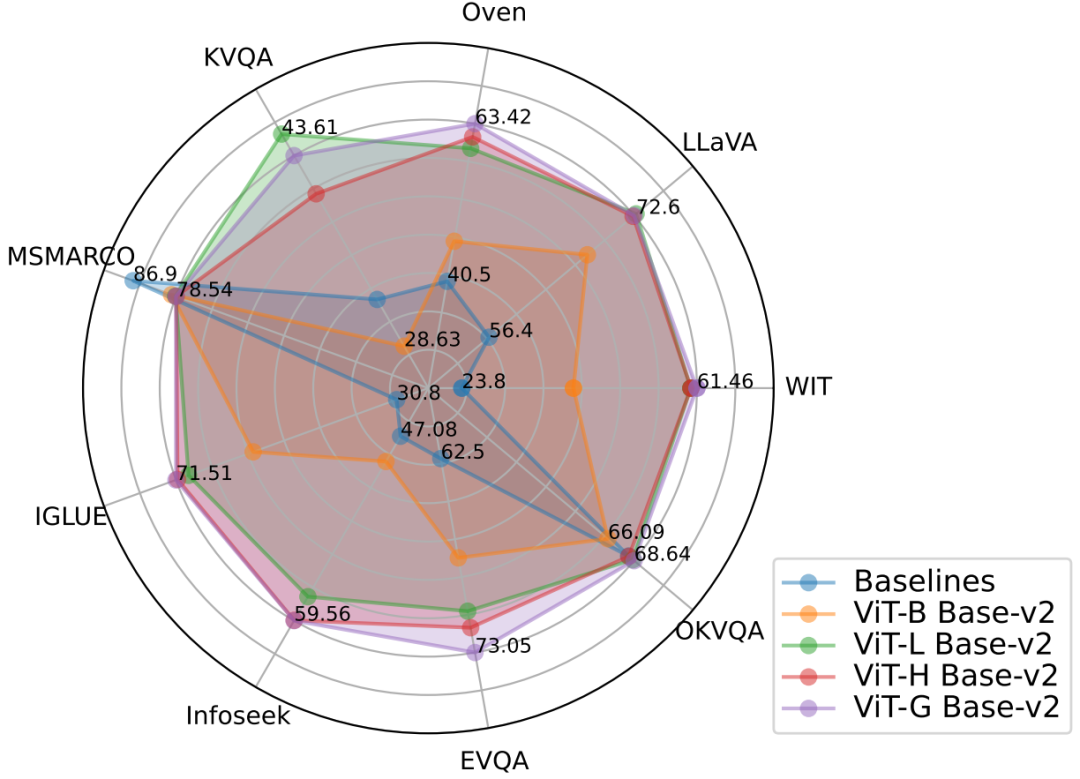
Figure 2: The PreFLMR model achieves excellent multimodal retrieval performance across multiple tasks, making it a powerful pre-trained base model.2. Traditional Dense Passage Retrieval (DPR) only uses a single vector to represent the query or document. The Cambridge team demonstrated in their NeurIPS 2023 paper that the single-vector representation design of DPR leads to the loss of fine-grained information, causing DPR to perform poorly on retrieval tasks that require precise information matching. Especially in multimodal tasks, the user’s query contains complex scene information, and compressing it into a one-dimensional vector greatly suppresses the expressive power of features. PreFLMR inherits and improves the structure of FLMR, giving it a unique advantage in multimodal knowledge retrieval.
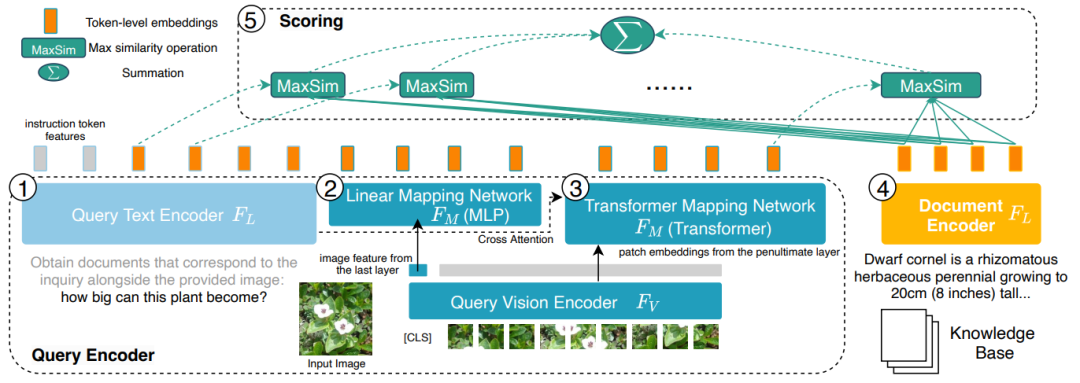
Figure 3: PreFLMR encodes queries (left 1, 2, 3) and documents (right 4) at the token level, providing an advantage in information granularity compared to the DPR system that compresses all information into a one-dimensional vector.3. PreFLMR can extract relevant documents from a large knowledge base based on user input instructions (e.g., “extract documents that can answer the following questions” or “extract documents related to the items in the image”), significantly improving the performance of multimodal large models in specialized knowledge question-answering tasks.


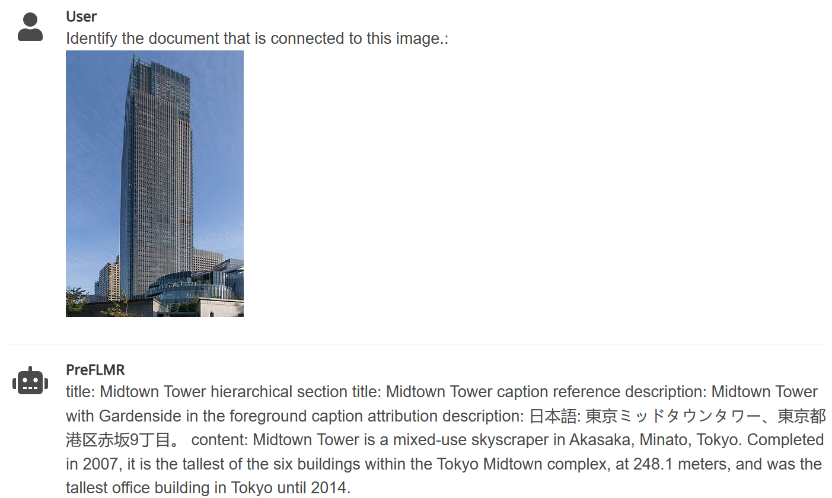
Figure 4: PreFLMR can simultaneously handle multimodal query tasks that extract documents based on images, questions, or both.The Cambridge team has open-sourced three different scales of models, with parameters ranging from small to large: PreFLMR_ViT-B (207M), PreFLMR_ViT-L (422M), PreFLMR_ViT-G (2B), for users to choose based on their actual needs.In addition to the open-sourced PreFLMR model itself, the project has made two significant contributions in this research direction:
- The project has simultaneously open-sourced a large-scale dataset for training and evaluating general knowledge retrievers, the Multi-task Multi-modal Knowledge Retrieval Benchmark (M2KR), which includes 10 widely studied retrieval sub-tasks and a total of over one million retrieval pairs.
- In the paper, the Cambridge team compared different sizes and performances of image encoders and text encoders, summarizing best practices for scaling parameters and pre-training multimodal late-interaction knowledge retrieval systems, providing empirical guidance for future general retrieval models.
The following text will briefly introduce the M2KR dataset, the PreFLMR model, and the analysis of experimental results.M2KR DatasetTo enable large-scale pre-training and evaluation of general multimodal retrieval models, the authors compiled ten publicly available datasets and converted them into a unified question-document retrieval format. The original tasks of these datasets included image captioning, multi-modal dialogue, etc. The figure below shows questions (first row) and corresponding documents (second row) for five of these tasks.

Figure 5: Some knowledge extraction tasks in the M2KR datasetPreFLMR Retrieval Model
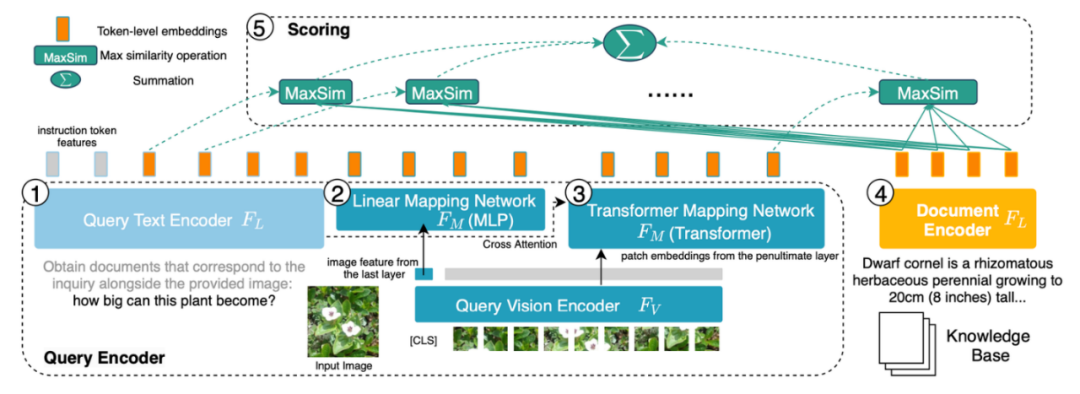
Figure 6: The structure of PreFLMR. Queries are encoded as token-level features. PreFLMR finds the nearest vector in the document matrix for each vector in the query matrix and computes the dot product, then sums these maximum dot products to obtain the final relevance score.The PreFLMR model is based on the Fine-grained Late-interaction Multi-modal Retriever (FLMR) published at NeurIPS 2023 and has undergone model improvements and large-scale pre-training on M2KR. Compared to DPR, FLMR and PreFLMR represent documents and queries using a matrix composed of all token vectors. Tokens include text tokens and image tokens projected into text space. Late interaction is an efficient algorithm for computing the correlation between two representation matrices. Specifically, for each vector in the query matrix, it finds the nearest vector in the document matrix and computes the dot product. Then it sums these maximum dot products to obtain the final relevance score. In this way, each token’s representation can explicitly influence the final relevance, preserving fine-grained information at the token level. Thanks to a dedicated late interaction retrieval engine, PreFLMR can extract 100 relevant documents from 400,000 documents in just 0.2 seconds, greatly enhancing usability in RAG scenarios.The pre-training of PreFLMR includes the following four stages:
- Text Encoder Pre-training: First, a late interaction text retrieval model is pre-trained on MSMARCO (a purely text knowledge retrieval dataset) as the text encoder for PreFLMR.
- Image-Text Projection Layer Pre-training: Second, the image-text projection layer is trained on M2KR while freezing other parts. This stage only uses projected image vectors for retrieval, aiming to prevent the model from overly relying on textual information.
- Continued Pre-training: Then, the text encoder and image-text projection layer are continuously trained on E-VQA, a high-quality knowledge-intensive visual question-answering task in M2KR. This stage aims to improve PreFLMR’s fine knowledge retrieval ability.
- General Retrieval Training: Finally, all weights are trained on the entire M2KR dataset, freezing the image encoder. Meanwhile, the parameters of the query text encoder and document text encoder are unlocked for separate training. This stage aims to enhance PreFLMR’s general retrieval capability.
At the same time, the authors demonstrate that PreFLMR can be further fine-tuned on sub-datasets (such as OK-VQA, Infoseek) to achieve better retrieval performance on specific tasks.Experimental Results and Longitudinal ExpansionBest Retrieval Results: The best performing PreFLMR model uses ViT-G as the image encoder and ColBERT-base-v2 as the text encoder, totaling two billion parameters. It achieves performance exceeding baseline models on seven M2KR retrieval sub-tasks (WIT, OVEN, Infoseek, E-VQA, OKVQA, etc.).Expanding visual encoding is more effective: The authors found that upgrading the image encoder ViT from ViT-B (86M) to ViT-L (307M) brought significant performance improvements, but expanding the text encoder ColBERT from base (110M) to large (345M) resulted in performance degradation and training instability. Experimental results indicate that for late interaction multimodal retrieval systems, increasing the parameters of the visual encoder yields greater returns. Additionally, using multi-layer cross-attention for image-text projection yields similar results to using a single layer, indicating that the design of the image-text projection network does not need to be overly complex.PreFLMR makes RAG more effective: In knowledge-intensive visual question-answering tasks, using PreFLMR for retrieval enhancement significantly improves the performance of the final system: achieving performance boosts of 94% and 275% on Infoseek and EVQA, respectively. After simple fine-tuning, models based on BLIP-2 can outperform the trillion-parameter PALI-X model and the Google API-enhanced PaLM-Bison+Lens system.ConclusionThe PreFLMR model proposed by the Cambridge Artificial Intelligence Laboratory is the first open-source general late-interaction multimodal retrieval model. After pre-training on millions of data in M2KR, PreFLMR demonstrates strong performance across multiple retrieval sub-tasks. The M2KR dataset, PreFLMR model weights, and code can all be obtained from the project homepage https://preflmr.github.io/.Additional Resources
- FLMR paper (NeurIPS 2023): https://proceedings.neurips.cc/paper_files/paper/2023/hash/47393e8594c82ce8fd83adc672cf9872-Abstract-Conference.html
- Code repository: https://github.com/LinWeizheDragon/Retrieval-Augmented-Visual-Question-Answering
- English blog: https://www.jinghong-chen.net/preflmr-sota-open-sourced-multi/
- FLMR Introduction: https://www.jinghong-chen.net/fined-grained-late-interaction-multimodal-retrieval-flmr/

© THE END
For reprints, please contact this public account for authorization
For submissions or inquiries: [email protected]