Follow the public account “ML_NLP“
Set as “Starred“, delivering heavy content promptly!
Reprinted from | 21dB Acoustics
Awni Hannun, an outstanding scientist at Zoom and former employee at Facebook and Baidu Silicon Valley, recently wrote a paper predicting the development of speech recognition technology in the next decade. In this paper, the author first reviews the timeline of speech recognition technology development over the past decade (2010-2020), then provides relevant experiences on how to make predictions, and finally predicts the research and application hotspots for speech recognition technology in the next ten years.
Paper link: https://arxiv.org/pdf/2108.00084.pdf
Review
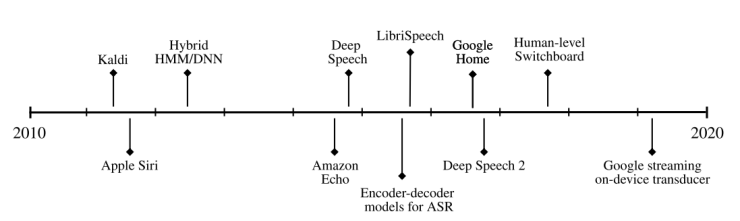
From 2010 to 2020, significant progress has been made in speech recognition and related technologies. Figure 1 shows the timeline of research, software, and application development in speech recognition over the past decade. This decade has witnessed the launch and popularity of mobile-based voice assistants. Devices like Amazon Alexa and Google Home have also been released and proliferated.
Figure 1 Timeline of speech recognition technology from 2010 to 2020
Due to the rise of deep learning, the word error rate of automatic speech recognition has significantly decreased, partly enabling these technologies. The key drivers of deep learning’s success in speech recognition are: 1) management of massive transcription datasets; 2) rapid advancements in graphics processing units; and 3) improvements in learning algorithms and model architectures.
Due to these factors, the word error rate of speech recognizers has continuously and significantly improved over the entire decade. In two recent research tests, automatic speech recognition has surpassed professional transcribers in word error rate metrics.
This significant progress raises the question: what can still be done in the next decade until 2030? Below, I will attempt to answer this question. However, before starting, I would like to first share some insights on the general issue of predicting the future. These insights come from mathematician (and computer scientist and electrical engineer) Richard Hamming, who was particularly adept at predicting the future of computation.
Insights on Predicting the Future
Richard Hamming made many predictions in his book “The Art of Doing Science and Engineering,” many of which have come true. Here are a few examples:
-
He predicted, “By 2020, it will be quite common for domain experts to write programs instead of computer experts.”
-
He predicted that neural networks “represent a solution to programming problems” and that “they may play an important role in the future of computing.”
-
He predicted the rise of general-purpose rather than specialized hardware, as well as analog digital and high-level programming languages.
-
Even before switches actually occurred, he anticipated the use of fiber optic cables instead of copper wires for communication.
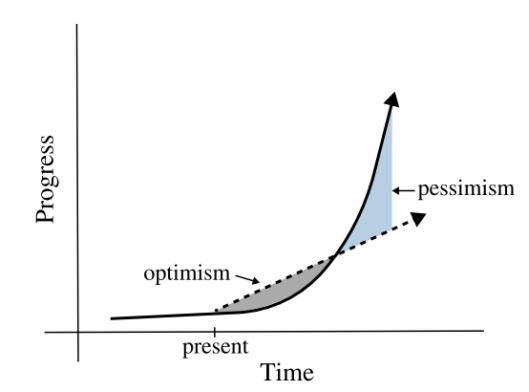
A common saying about technological predictions is that short-term predictions tend to be overly optimistic, while long-term predictions are often overly pessimistic. This is usually attributed to the fact that technological progress is exponential. Figure 2 shows an optimistic inference if we view progress as linearly related to time based on current assumptions. The progress of speech recognition over the past decade (2010-2020) has been driven by exponential growth along two key axes: computation (e.g., floating-point operations per second) and dataset size. Whether Figure 2 applies to the next decade of speech recognition remains to be seen.
Figure 2 Relationship between progress and time
I believe many of the predictions below will prove to be wrong. In some respects, especially regarding more controversial predictions, these indeed resemble wish lists for the future. On this note, let me conclude this section with a quote from computer scientist Alan Kay: The best way to predict the future is to invent it.
Predictions on Research Directions
Prediction: Semi-supervised learning will continue to exist. In particular, self-supervised pre-training models will become part of many machine learning applications, including speech recognition.
As a research scientist, part of my work involves hiring, which means conducting a large number of interviews. I have interviewed over a hundred candidates working on various machine learning applications. A significant portion of these, especially those focused on natural language applications, rely on pre-trained models as the foundation for their machine learning products or features. Self-supervised pre-training has become common in industrial applications. I predict that by 2030, self-supervised pre-training will be equally prevalent in speech recognition.
In the past three years, deep learning has been the year of semi-supervised and self-supervised learning. The field has undoubtedly learned how to use unlabeled data to improve machine learning models. Self-supervised learning has benefited many of the most challenging machine learning tasks. In language tasks, state-of-the-art transcription has been surpassed by self-supervised models. Self-supervised and semi-supervised learning are now common and have set records in computer vision and machine translation.
Speech recognition also benefits from semi-supervised learning. The first approach is self-supervised pre-training, whose loss function is based on contrastive predictive coding. The idea is simple: train models to predict future frames given past audio. The second approach is pseudo-labeling. Similarly, the idea is straightforward: use a trained model to predict labels for unlabeled data and then train a new model on the predicted labels. The reasons and mechanisms behind why pseudo-labels work are interesting research questions.
One of the main challenges of self-supervision is scale and generalization performance. Currently, only the top industry research laboratories have the funding to conduct large-scale supervised training. As a research direction, supervised learning is less accessible to most laboratories and industry.
Research significance: Considering that lightweight models can be effectively trained with less data, self-supervised learning will be easier to achieve. Related research directions include the sparsity of lightweight models, optimization for faster training, and effective methods that combine prior knowledge to improve sample efficiency.
Prediction: Most speech recognition will occur on-device or at the mobile edge.
This prediction has several reasons. First, keeping data on the device rather than sending it to a central server is more private. The trend of data privacy will bring about computational demands on-device. If models need to learn from user data, then training should take place on the device.
The second reason for preferring edge computing is latency. The difference between 10 milliseconds and 100 milliseconds is not large in absolute terms. However, the former is far below human perceptual latency, while the latter is far above it. Google has demonstrated a speech recognition system that operates on-device with accuracy nearly equivalent to that of a good server-side system. From a practical perspective, the imperceptible latency of on-device systems makes interactions feel more responsive, thus more attractive.
The final reason is 100% availability. Even without an internet connection or unstable service, the recognizer can still work, meaning it will always function. From the perspective of user interaction, there is a significant difference between products that are effective most of the time and those that work every time.
Research significance: On-device recognition requires models that are computationally lightweight and low power. Model quantization and knowledge distillation (training smaller models to mimic more accurate larger models) are two common techniques. Less commonly used sparsity is another way to generate lightweight models. In sparse models, most parameters (i.e., connections between hidden states) are zero and can be effectively ignored. Among these three techniques, I believe sparsity is the most promising research direction.
I believe we have already extracted the maximum value from quantization; even in unlikely scenarios where quantization is further reduced from 8 bits to 1 bit, we can only achieve an eightfold gain. For distillation, there is still much to learn. However, I believe revealing the mechanisms behind distillation will enable us to train small models directly, rather than taking a roundabout route of first training a large model and then training a second smaller model to mimic the large model.
Prediction: By 2030, possibly sooner, researchers will no longer publish papers like “Using Model Architecture Y to Improve Word Error Rate on Benchmark X.”
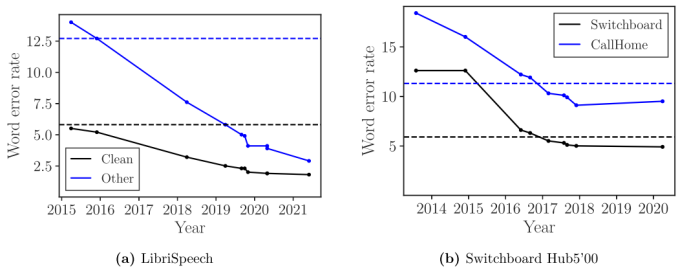
As you can see in Figure 3, the word error rates of the two most studied speech recognition benchmarks have saturated. Part of the issue is that we need more rigorous benchmarks for researchers to study. Two recently released benchmarks may stimulate further research in the field of speech recognition. However, I predict these benchmarks will quickly saturate with the expansion of models and computation.
Figure 3 Word error rates on two datasets
Another part of the problem is that we have reached a situation where improvements in word error rates on academic benchmarks are no longer related to practical value. A few years ago, the word error rates of the two benchmarks in Figure 3 surpassed those of humans. However, in most cases, humans understand speech better than machines. This means that word error rate as a measure of the quality of our speech recognition systems does not correlate well with the ability to understand human speech.
The final issue is that as models and datasets grow larger, along with increasing computational costs, state-of-the-art speech recognition research becomes increasingly difficult to access. Some well-funded industrial laboratories are quickly becoming the only places capable of conducting such research. As progress slows and drifts further from academia, this part of the field will continue to shift from research labs to engineering organizations.
Prediction: For downstream tasks that rely on speech recognizer output, transcription will be replaced by richer expressions. Examples of such downstream applications include dialogue agents, voice-based search queries, and digital assistants.
Downstream applications usually do not care about verbatim transcription; they care about semantic correctness. Therefore, improving the word error rate of speech recognizers does not typically improve the objectives of downstream tasks. One possibility is to develop a semantic error rate and use it to measure the quality of speech recognizers. This is a challenging but interesting research question.
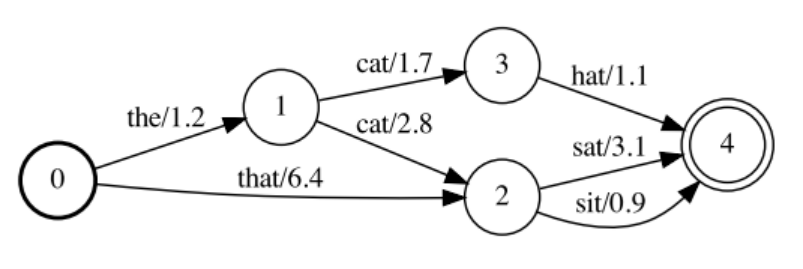
I think a more likely outcome is to provide richer expressions for downstream applications via speech recognition. For example, instead of passing a single transcription, passing a grid that captures the uncertainty of each possibility (as shown in Figure 4) may be more useful.
Figure 4 An example of a grid encoded based on speech recognition weighting
Prediction: By 2030, speech recognition models will be deeply personalized for individual users.
One of the main distinctions between automatic recognition of speech and human interpretation of speech lies in the use of context. Humans rely on a lot of contextual information when conversing with each other. This context includes the topic of conversation, what has been said in the past, background noise, and visual cues like lip movements and facial expressions. For short utterances (i.e., less than 10 seconds), we have already or are about to reach the optimal error rate for speech recognition. Our models are doing their best to utilize the available information in the data. To continue improving machines’ understanding of human speech, context needs to be a deeper part of the recognition process.
One way to achieve this is through personalization. Personalized models for individuals with speech impairments improved the word error rate by 64%. Personalization can significantly impact recognition quality, especially for groups or domains that are underrepresented in training data. I predict that by 2030, we will see more widespread personalization.
Research significance: On-device personalization requires training done locally, which in itself requires lightweight models and some form of weak supervision. Personalization requires models that can be easily customized based on a given user or context. The best way to incorporate such context into models remains an open research question.
Application Predictions
Prediction: By 2030, 99% of transcription voice services will be completed through automatic speech recognition. Human transcribers will perform quality control and correct or transcribe more difficult utterances. Transcription services include, for example, adding subtitles to videos, transcribing interviews, and transcribing lectures or speeches.
Prediction: Voice assistants will get better, but it will take time. Speech recognition is no longer the bottleneck for better voice assistants. The bottleneck is now entirely in the realm of language understanding, including the ability to maintain conversations, multiple context responses, and broader domain question answering. We will continue to make progress on these so-called AI-complete problems, but I do not believe they will be solved by 2030.
Will we live in smart homes, always listening and responding to every sound we make?
Will we wear augmented reality glasses and control them with our voice?
Conclusion
These predictions suggest that the next decade for the development of speech recognition and spoken understanding may be as exciting and significant as the previous decade. However, there are still many research questions to address before speech recognition reaches a state of being effective for everyone. Nevertheless, this is a goal worth striving for, as speech recognition technology is a key component for enabling smoother and more natural interactions.
Recommended Reading:
H.T. Kung's Useful Suggestions on Research
What is Transformer Positional Encoding?
17 PyTorch Implementations of Attention Mechanisms, Including Popular Papers from MLP and Re-Parameter Series
Click the card below to follow the public account “Machine Learning Algorithms and Natural Language Processing” for more information: