Auditory
Sound waves act on the auditory organs, causing sensory cells to become excited and triggering impulses in the auditory nerve that transmit information to the brain. After analysis by various levels of the auditory centers, this results in the sensation of hearing.
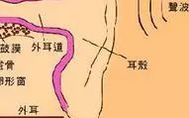
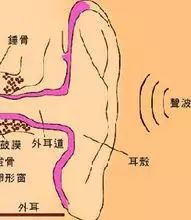
External sound waves are transmitted through a medium to the outer ear canal, then to the eardrum. The eardrum vibrates, and after amplification by the ossicles, the vibrations reach the inner ear, stimulating the hair cells within the cochlea (also known as auditory receptors) to produce neural impulses. These impulses travel along the auditory nerve to the auditory centers in the cerebral cortex, resulting in hearing. Hearing is the second most important sensory channel after vision. It plays a significant role in human life. The frequency range of sound waves that the human ear can perceive is (key point 16–20,000 Hertz), with (key point 1,000–3,000 Hertz) being the most sensitive. Apart from the visual analyzer, the auditory analyzer is the second most important long-distance analyzer for humans. From an evolutionary perspective, as the organs specialized for hearing developed, sound not only became a signal for animals to capture food or escape from danger, but also became a tool for communication among them.
 Auditory
Auditory
Properties of Sound
The sound waves conducted by air vibrations act on the human ear, producing the sensation of hearing. The sounds we hear have three properties, known as sensory characteristics: loudness, pitch, and timbre. Sound intensity refers to the loudness of a sound, determined by the physical property of sound waves known as amplitude, which is the maximum distance from the equilibrium position during vibration. The unit of sound intensity is called decibels, abbreviated as dB. 0 decibels refers to the smallest sound intensity detectable under normal hearing. Pitch refers to the highness or lowness of a sound, determined by the physical property of sound waves known as frequency, which is the number of vibrations per second. The unit of frequency is called Hertz, abbreviated as Hz. The range of pitch that normal human hearing can detect is quite broad, from a minimum of 20 Hertz to 20,000 Hertz. The long wave referred to in everyday language indicates low-frequency sounds, while short waves indicate high-frequency sounds. Sounds caused by a single frequency sine wave are pure tones, but most sounds are mixtures of many frequencies and amplitudes. The composite structure of mixed sounds and their constituent forms constitute the quality characteristics of sound, known as timbre. Timbre is the primary basis on which humans can distinguish between different sound sources producing the same pitch, such as male voices, female voices, piano sounds, and violin sounds performing the same melody, which sound different. The differences in timbre are determined by the physical properties of the sound-producing objects.
Adaptation and Fatigue of Hearing
Auditory adaptation occurs quickly, and recovery also happens rapidly. Auditory adaptation is selective, meaning it only occurs for the frequencies of sounds acting on the ear, while not affecting other sounds. If a sound acts continuously for a long time (such as several hours), it can lead to a significant decrease in auditory sensitivity, termed auditory fatigue. Auditory fatigue differs from auditory adaptation; it requires a long time to recover after the sound stops. If this fatigue occurs frequently, it can lead to hearing loss or even deafness. If only a small portion of frequencies is lost, it is called an auditory gap. If a larger portion of sound is lost, it is referred to as an auditory island. In severe cases, complete deafness can occur.
Sound Mixing and Masking
When two sounds reach the ear simultaneously, they mix, and the result varies due to differences in their frequencies and amplitudes. If the two sounds have roughly equal intensity but differ significantly in frequency, a mixed sound occurs. However, if the two sounds have similar intensity and close frequencies, a phenomenon called beating occurs, perceived as a fluctuation at the frequency difference of the two sounds. If the intensity of the two sounds differs significantly, only the louder sound can be perceived, a phenomenon known as sound masking. The effectiveness of sound masking is influenced by frequency and intensity. If both the masking sound and the masked sound are pure tones, the closer the frequencies, the greater the masking effect. Low-frequency sounds have a greater masking effect on high-frequency sounds than vice versa. Increasing the intensity of the masking sound enhances the masking effect and increases the range of frequencies covered; decreasing the intensity reduces the masking effect and the range of frequencies covered.
Infants’ HearingIn addition to providing rich visual stimulation, newborns should also receive ample auditory stimulation. At birth, vision and hearing are “each performing their duties,” and training infants in both visual and auditory skills aids in the “connection” between the senses, promoting the development of their perception. There are many types of sound toys that can enhance infants’ hearing, such as various music boxes, rattles, maracas, various shaped blow toys that produce sound, hand-cranked accordions, and various hanging toys that make sounds. When the baby is awake, parents can gently shake toys near the baby’s ears to produce sounds, guiding the baby to turn their head towards the sound source. In addition to using sound toys, adults can also clap their hands, imitate the sound of a cat’s “meow,” or a dog’s “woof” to engage the child, prompting them to turn their head towards the direction of the sound.
Various theories explain auditory phenomena and their mechanisms. How sound waves produce hearing has always been a topic of interest. A complete theory of hearing should elucidate the entire auditory mechanism. However, some classic theories of hearing only address how the ear distinguishes pitch, thus only representing a cochlear pitch theory. With the advancement of modern electronic computing technology and neurophysiology, although some understanding of the functions of the auditory centers has been achieved, overall, very little is known about how the auditory system processes auditory information from the periphery and how hearing is produced.
Machine Hearing (Speech Recognition)
[The idea of creating intelligent computers that can understand human language seems to be ultimately achievable, and the successful contributors are mathematicians.]
People often compare speech recognition to a “machine auditory system.” Communicating verbally with machines, allowing them to understand what you say, has been a long-held dream. Speech recognition technology enables machines to convert speech signals into corresponding text or commands through recognition and understanding processes. Speech recognition technology mainly includes three aspects: feature extraction technology, pattern matching criteria, and model training technology. Speech recognition technology has also been fully applied in the automotive internet sector; for example, in the Wing Card vehicle networking system, users can simply press a button to dictate to customer service personnel to set the destination for direct navigation, ensuring safety and convenience.
Speech recognition is an interdisciplinary field. Over the past two decades, significant progress has been made in speech recognition technology, moving from the laboratory to the market. It is expected that within the next ten years, speech recognition technology will penetrate various fields, including industry, home appliances, telecommunications, automotive electronics, healthcare, home services, and consumer electronics. The application of speech recognition dictation machines in some fields has been rated by the American news media as one of the top ten developments in computing in 1997. Many experts believe that speech recognition technology is one of the top ten important technological developments in the field of information technology from 2000 to 2010.
The fields involved in speech recognition technology include:signal processing, pattern recognition, probability theory and information theory, voice production mechanisms, auditory mechanisms, and artificial intelligence, etc.
History of Development
In 1952, researchers at Bell Labs, including Davis, successfully developed the world’s first experimental system capable of recognizing the pronunciations of ten English digits.
In 1960, British researchers, including Denes, successfully developed the first computer speech recognition system.
Large-scale speech recognition research made substantial progress after entering the 1970s, particularly in isolated word recognition with small vocabulary.
After entering the 1980s, research focus gradually shifted to large vocabulary, non-specific person continuous speech recognition. A significant change in research thinking occurred, moving from traditional standard template matching techniques to statistical model-based techniques (HMM). Additionally, the idea of introducing neural network technology into speech recognition problems was proposed again.
After entering the 1990s, there were no significant breakthroughs in the system framework of speech recognition, but substantial progress was made in the application and commercialization of speech recognition technology.
DARPA (Defense Advanced Research Projects Agency) was a ten-year plan funded by the U.S. Department of Defense’s Advanced Research Projects Agency in the 1970s, aimed at supporting the research and development of language understanding systems.
In the 1980s, the U.S. Department of Defense’s Advanced Research Projects Agency funded a ten-year DARPA strategic plan, which included speech recognition under noise and conversational (spoken) recognition systems, with recognition tasks set for a “(1,000-word) continuous speech database management.”
By the 1990s, this DARPA plan was still ongoing. Its research focus had shifted to the natural language processing component of recognition devices, with recognition tasks set for “air travel information retrieval.”
Japan also proposed grand goals related to speech recognition input-output natural language in its Fifth Generation Computer Plan in 1981. Although these goals were not achieved as expected, significant progress and strengthening of research related to speech recognition technology occurred.
Since 1987, Japan has proposed a new national project—advanced human-machine spoken interface and automatic telephone translation system.
Development in China
Research on speech recognition in China began in 1958, with the Institute of Acoustics of the Chinese Academy of Sciences using electronic tube circuits to recognize ten vowels. It wasn’t until 1973 that the Institute of Acoustics of the Chinese Academy of Sciences began computer speech recognition research. Due to the limitations of the conditions at that time, research on speech recognition in China remained in a slow development stage.
After entering the 1980s, with the gradual popularization and application of computer technology in China and further development of digital signal technology, many domestic units gained the basic conditions for researching speech technology. Meanwhile, internationally, after years of dormancy, speech recognition technology became a hot research topic again and developed rapidly. In this context, many domestic units began to invest in this research.
In March 1986, China’s High-Tech Development Plan (863 Plan) was launched, with speech recognition specifically listed as an important research topic within the intelligent computer system research. Supported by the 863 Plan, China began organized research on speech recognition technology and decided to hold a special conference on speech recognition every two years. From then on, China’s speech recognition technology entered an unprecedented stage of development.
Recognition Patterns
The speech recognition methods during this period primarily adopted traditional pattern recognition strategies. Among them, the research by the Soviet Union’s Velichko and Zagoruyko, Japan’s Maki and Chiba, and the work of Ban Takara in the United States were the most representative.
The Soviet research laid the foundation for the application of pattern recognition in the field of speech recognition;
Japan’s research demonstrated how to use dynamic programming techniques for nonlinear time matching between the speech pattern to be recognized and standard speech patterns;
Ban Takara’s research proposed how to extend linear predictive analysis techniques (LPC) for feature extraction of speech signals.
Databases
In the development of speech recognition research, relevant researchers designed and produced speech databases for various languages based on their pronunciation characteristics, including Chinese (including different dialects) and English. These speech databases can provide sufficient and scientific training speech samples for domestic and foreign research institutions and universities conducting research on Chinese continuous speech recognition algorithms, system design, and industrialization work. Examples include: MIT Media Lab Speech Dataset, Pitch and Voicing Estimates for Aurora 2, Congressional Speech Data, Mandarin Speech Frame Data, and speech data for testing blind source separation algorithms.
Technological Development
Currently, the IBM speech research group, which leads in large vocabulary speech recognition, began its research on large vocabulary speech recognition in the 1970s. AT&T’s Bell Labs also began a series of experiments related to non-specific person speech recognition. This research lasted for ten years, resulting in establishing methods for creating standard templates for non-specific person speech recognition.
Significant progress achieved during this period includes:
1) The maturity and continuous improvement of the Hidden Markov Model (HMM) technology has become the mainstream method for speech recognition.
2) Research on knowledge-based speech recognition has received increasing attention. In continuous speech recognition, in addition to recognizing acoustic information, various language knowledge (such as morphology, syntax, semantics, and dialogue context) is increasingly used to assist in further recognizing and understanding speech. Additionally, statistical probability-based language models have emerged in the field of speech recognition research.
3) The rise of research on the application of artificial neural networks in speech recognition. Most of these studies adopt multi-layer perceptrons based on the backpropagation algorithm (BP algorithm). Artificial neural networks have the ability to distinguish complex classification boundaries, which is evidently beneficial for pattern classification. Especially in telephone speech recognition, due to its broad application prospects, it has become a hot topic in current speech recognition applications.
Additionally, the technology for continuous speech dictation machines for personal use is also becoming more refined. The most representative examples are IBM’s ViaVoice and Dragon’s Dragon Dictate systems. These systems have speaker adaptive capabilities, allowing new users to improve recognition rates without needing to train on the entire vocabulary.
Development of Speech Recognition Technology in China: 1) In Beijing, there are research institutions and universities such as the Institute of Acoustics of the Chinese Academy of Sciences, the Institute of Automation, Tsinghua University, and North China Transportation University. Other universities like Harbin Institute of Technology, University of Science and Technology of China, and Sichuan University have also begun to take action.
2) Currently, many speech recognition systems have been successfully developed in China. These systems have distinct performance characteristics.
• In the area of isolated word recognition with large vocabulary, the most representative system is the THED-919 specific person speech recognition and understanding real-time system, developed in collaboration between Tsinghua University’s Department of Electronic Engineering and China Electronics Device Company in 1992.
• In continuous speech recognition, in December 1991, the Computer Center of Sichuan University implemented a theme-restricted specific person continuous English-Chinese speech translation demonstration system on a microcomputer.
• In the area of non-specific person speech recognition, there is the voice-controlled telephone directory system developed by the Department of Computer Science and Technology at Tsinghua University in 1987, which has been put into practical use.
Classification Applications
According to the different objects of recognition, speech recognition tasks can generally be divided into three categories: isolated word recognition, keyword recognition (also known as keyword spotting), and continuous speech recognition. The task of isolated word recognition is to recognize known isolated words, such as “turn on” and “turn off”; the task of continuous speech recognition is to recognize any continuous speech, such as a sentence or a paragraph; the task of keyword detection in continuous speech focuses on continuous speech but does not recognize all words, only detecting where known keywords appear, such as detecting the words “computer” and “world” in a paragraph.
According to the targeted speaker, speech recognition technology can be divided into specific person speech recognition and non-specific person speech recognition. The former can only recognize the speech of one or a few individuals, while the latter can be used by anyone. Clearly, non-specific person speech recognition systems better meet practical needs, but they are much more difficult to implement than specific person recognition.
Additionally, according to speech devices and channels, it can be divided into desktop (PC) speech recognition, telephone speech recognition, and embedded device (mobile phones, PDAs, etc.) speech recognition. Different collection channels can distort the acoustic characteristics of a person’s pronunciation, necessitating the construction of respective recognition systems.
The application fields of speech recognition are very broad, with common application systems including: speech input systems, which, compared to keyboard input methods, align better with human daily habits, being more natural and efficient; speech control systems, which use speech to control device operations, making them faster and more convenient than manual control, applicable in various fields such as industrial control, voice dialing systems, smart appliances, and voice-controlled smart toys; intelligent dialogue query systems, which operate based on customer speech to provide natural, friendly database retrieval services, such as home services, hotel services, travel agency services, ticket booking systems, medical services, banking services, stock inquiry services, and more.
Recognition Methods
The primary method for speech recognition is the pattern matching method.
In the training phase, users sequentially say each word in the vocabulary list and store the feature vectors as templates in the template library.
In the recognition phase, the feature vectors of the input speech are sequentially compared for similarity with each template in the template library, and the one with the highest similarity is output as the recognition result.
Main Issues
Speech recognition mainly faces the following five issues:
1) Recognition and understanding of natural language. First, continuous speech must be decomposed into units such as words and phonemes; secondly, rules for understanding semantics must be established.
2) Large amount of speech information. Speech patterns differ not only between different speakers but also for the same speaker; for example, a speaker’s speech information differs when speaking casually versus when speaking seriously. A person’s speaking style changes over time.
3) Ambiguity of speech. When a speaker talks, different words may sound similar. This is common in both English and Chinese.
4) The phonetic characteristics of individual letters or words are influenced by context, altering their accent, pitch, volume, and pronunciation speed.
5) Environmental noise and interference seriously affect speech recognition, resulting in low recognition rates.
Front-End Processing
Front-end processing refers to processing the raw speech before feature extraction, partially eliminating noise and the effects of different speakers, allowing the processed signal to better reflect the essential characteristics of speech. The most common front-end processing methods include endpoint detection and speech enhancement. Endpoint detection refers to distinguishing between speech and non-speech signal periods in the speech signal, accurately determining the starting point of the speech signal. After endpoint detection, subsequent processing can focus solely on the speech signal, which is crucial for improving model accuracy and recognition rates. The main task of speech enhancement is to eliminate the impact of environmental noise on speech. Currently, the general method used is Wiener filtering, which performs better than other filters under high noise conditions.
Acoustic Features
Extracting and selecting acoustic features is a crucial aspect of speech recognition. The extraction of acoustic features is both a process of significant information compression and a signal unwrapping process aimed at improving the partitioning capability of the pattern classifier. Due to the time-varying nature of speech signals, feature extraction must be performed over a short segment of the speech signal, referred to as a frame, which is considered a stationary analysis interval. The offset between frames is typically taken as 1/2 or 1/3 of the frame length. Usually, signals undergo pre-emphasis to enhance high frequencies and are windowed to avoid edge effects at the short-term speech segments.
LPC
Linear Predictive Coding starts from the human voice production mechanism, studying the short tube cascade model of the vocal tract, and posits that the system’s transfer function conforms to the form of an all-pole digital filter. Thus, the signal at time n can be estimated as a linear combination of the signals from previous time points. By minimizing the mean square error (LMS) between the actual speech sampling values and the predicted sampling values, the linear predictive coefficients (LPC) can be obtained. There are various methods for calculating LPC, including the autocorrelation method (Durbin’s method), covariance method, and lattice method. The computational efficiency ensures the widespread use of this acoustic feature. Other similar acoustic features include Linear Spectral Pairs (LSP), reflection coefficients, etc.
CEP
Using homomorphic processing methods, applying the discrete Fourier transform (DFT) to speech signals, taking the logarithm, and then performing the inverse transform (iDFT) yields cepstral coefficients. For LPC cepstrum (LPCCEP), after obtaining the filter’s linear predictive coefficients, they can be computed using a recursive formula. Experiments have shown that using cepstrum improves the stability of feature parameters.
Mel
Unlike LPC and other acoustic features derived from studying human voice production mechanisms, Mel-frequency cepstral coefficients (MFCC) and perceptual linear prediction (PLP) are acoustic features driven by research on the human auditory system. Studies on human auditory mechanisms have found that when two pitches of similar frequency are emitted simultaneously, a person can only hear one pitch. The critical bandwidth refers to the bandwidth boundary that causes a sudden change in subjective perception; when the frequency difference between two pitches is less than the critical bandwidth, a person perceives the two pitches as one, known as the masking effect. The Mel scale is one of the measurement methods for this critical bandwidth.
MFCC
First, the time-domain signal is converted to the frequency domain using FFT, then the logarithmic energy spectrum is convolved with a triangular filter bank distributed according to the Mel scale, and finally, the outputs from each filter are subjected to discrete cosine transform (DCT) to obtain the first N coefficients. PLP uses the Durbin method to calculate LPC parameters, but the DCT method is also applied to the logarithmic energy spectrum of auditory stimuli when calculating autocorrelation parameters.
Acoustic Models
The model of a speech recognition system typically consists of two parts: acoustic models and language models, corresponding to the calculation of probabilities from speech to phonemes and from phonemes to words. This section and the next will introduce technologies related to acoustic models and language models.
HMM Acoustic Modeling: The concept of Markov models is a discrete-time finite state automaton, while the Hidden Markov Model (HMM) refers to a Markov model where the internal states are not visible to the outside world, and only the output values at each time point can be observed. In the context of speech recognition systems, the output values are usually the acoustic features calculated from each frame. Using HMM to characterize speech signals requires two assumptions: first, the transition of internal states depends only on the previous state; second, the output values depend only on the current state (or the current state transition). These assumptions greatly reduce the complexity of the model. The scoring, decoding, and training algorithms for HMM are the forward algorithm, Viterbi algorithm, and forward-backward algorithm.
Typically, HMM in speech recognition uses a left-to-right, self-looping, and crossing topology to model recognition units. A phoneme is modeled as an HMM with three to five states, and a word is formed by serially combining multiple phonemes’ HMMs. The model for continuous speech recognition consists of HMMs combining words and silence.
Contextual Modeling: Coarticulation refers to the phenomenon where one sound is influenced by adjacent sounds, causing changes. From the perspective of voice production mechanisms, this means that the characteristics of the vocal organs gradually change when transitioning from one sound to another, resulting in differences in the frequency spectrum compared to other conditions. Contextual modeling methods consider this influence during modeling, allowing for more accurate representation of speech. Modeling that only considers the influence of the preceding sound is called Bi-Phone, while considering both the preceding and following sounds is called Tri-Phone.
In English, contextual modeling typically uses phonemes as units. Since some phonemes have similar influences on subsequent phonemes, model parameters can be shared through clustering of phoneme decoding states. The clustering results are called senones. Decision trees are used to efficiently map triphones to senones, determining which senone should be used for the HMM state by answering a series of questions regarding the categories of preceding and following sounds (vowel/consonant, voiced/unvoiced, etc.).
Language Models
Language models are primarily divided into rule-based models and statistical models. Statistical language models reveal the inherent statistical laws within language units using probabilistic methods, among which N-Gram is simple, effective, and widely used.
N-Gram: This model is based on the assumption that the appearance of the nth word is only related to the preceding N-1 words and not to any other words. The probability of the entire sentence is the product of the probabilities of each word appearing. These probabilities can be obtained by directly counting the occurrences of N words appearing together in a corpus. Commonly used are bigrams (Bi-Gram) and trigrams (Tri-Gram).
The performance of language models is typically measured using cross-entropy and perplexity. Cross-entropy indicates the difficulty of recognizing text with the model, or viewed from the perspective of compression, how many bits on average are required to encode each word. Perplexity indicates the average branching number represented by the model, and its reciprocal can be considered as the average probability of each word. Smoothing refers to assigning a probability value to unseen N-grams to ensure that every word sequence can receive a probability value from the language model. Common smoothing techniques include Laplace estimation, deleted interpolation smoothing, Katz smoothing, and Kneser-Ney smoothing.
Search
In continuous speech recognition, searching involves finding a sequence of word models to describe the input speech signal, resulting in a word decoding sequence. The search relies on scoring from acoustic models and language models. In practical applications, it is often necessary to assign a high weight to the language model based on experience and set a penalty score for long words.
Viterbi: The Viterbi algorithm, based on dynamic programming, calculates the posterior probability of the decoded state sequence for the observed sequence at each time point, retaining the path with the highest probability and recording the corresponding state information at each node for later backward retrieval of the word decoding sequence. The Viterbi algorithm solves the nonlinear time alignment of HMM model state sequences and acoustic observation sequences in continuous speech recognition without losing the optimal solution, thus becoming the fundamental strategy for speech recognition searches.
Due to the unpredictable nature of future situations in speech recognition, heuristic pruning based on objective functions is difficult to apply. Because of the time-aligned nature of the Viterbi algorithm, the paths at the same time correspond to the same observation sequence, making them comparable. Beam search retains only the top few paths with the highest probabilities at each time point, significantly improving search efficiency. This time-aligned Viterbi-Beam algorithm is currently the most effective algorithm for speech recognition searches. N-best search and multi-pass search: To leverage various knowledge sources in the search, multiple passes are typically conducted. The first pass uses low-cost knowledge sources to generate a candidate list or word candidate grid, upon which a second pass using higher-cost knowledge sources is conducted to obtain the best path. The previously mentioned knowledge sources include acoustic models, language models, and phonetic dictionaries, which can be used for the first search. To achieve more advanced speech recognition or spoken understanding, higher-cost knowledge sources, such as 4-gram or 5-gram models, higher-order contextual models, inter-word correlation models, segment models, or syntactic analysis, are often employed for re-scoring. Many of the latest real-time large vocabulary continuous speech recognition systems utilize this multi-pass search strategy.
N-best search generates a candidate list, retaining the best N paths at each node, which increases computational complexity to N times. A simplified approach retains a few word candidates at each node but may lose suboptimal candidates. A compromise method is to consider only two-word-long paths, retaining k paths. The word candidate grid provides multiple candidates in a more compact form, and modifications to the N-best search algorithm can yield a candidate grid generation algorithm.
The forward-backward search algorithm is an example of applying multi-pass search. After performing a forward Viterbi search using simple knowledge sources, the forward probabilities obtained during the search can be used for calculating the objective function in the backward search, allowing for the use of heuristic A algorithms for efficient backward searching to obtain N candidates.
System Implementation
The requirements for selecting recognition units in speech recognition systems are accurate definitions, sufficient data for training, and general applicability. English typically adopts contextual phoneme modeling, while the coarticulation in Chinese is less severe, allowing for syllable modeling. The size of the training data required by the system is related to model complexity. If the model is overly complex beyond the capacity of the provided training data, performance will sharply decline.
Dictation machines: Large vocabulary, non-specific person, continuous speech recognition systems are commonly referred to as dictation machines. Their architecture is based on the HMM topology established on the aforementioned acoustic models and language models. During training, the model parameters for each recognition unit are obtained using the forward-backward algorithm, and during recognition, the units are concatenated into words, with silence models added between words and the language model introduced as transition probabilities between words, forming a cyclic structure, with Viterbi algorithm used for decoding. Given the ease of segmentation in Chinese, segmentation is performed first, followed by decoding each segment, which is a simplification method to improve efficiency.
Dialogue systems: Systems designed for human-machine spoken dialogue are referred to as dialogue systems. Due to current technological limitations, dialogue systems are often narrow domain systems with limited vocabulary, covering topics such as travel inquiries, ticket booking, database retrieval, etc. The front end consists of a speech recognizer that generates N-best candidates or word candidate grids, which are analyzed by a syntactic analyzer to obtain semantic information, followed by a dialogue manager determining the response information, and output by a speech synthesizer. Given the limited vocabulary of current systems, keyword extraction methods can also be used to obtain semantic information.
Robust Adaptation
The performance of speech recognition systems is affected by many factors, including different speakers, speaking styles, environmental noise, and transmission channels. Improving system robustness involves enhancing the system’s ability to overcome these influences, ensuring stable performance under different application environments and conditions; adaptation aims to automatically and specifically adjust the system based on different sources of influence, gradually improving performance during use. The following introduces solutions to different factors affecting system performance.
Solutions can be divided into two categories based on methods targeting speech features (hereafter referred to as feature methods) and model adjustment methods (hereafter referred to as model methods). The former seeks better, more robust feature parameters or incorporates specific processing methods based on existing feature parameters. The latter utilizes a small amount of adaptive corpus to correct or transform the original speaker-independent (SI) model into a speaker-adaptive (SA) model.
Speaker-adaptive feature methods include speaker normalization and speaker subspace methods, while model methods include Bayesian methods, transformation methods, and model merging methods.
Noise in speech systems includes environmental noise and electronic noise introduced during recording. Feature methods to improve system robustness include speech enhancement and finding features that are insensitive to noise interference, while model methods include parallel model combination (PMC) methods and artificially introducing noise during training. Channel distortion includes variations in microphone distance during recording, using microphones with different sensitivities, different gains in preamplifiers, and various filter designs. Feature methods include subtracting the long-term average from the cepstral vector and RASTA filtering, while model methods include cepstral shifting.
Recognition Engine
Microsoft has applied its self-developed speech recognition engine in both Office and Vista, and the use of the Microsoft speech recognition engine is completely free, leading to many speech recognition applications developed based on it, such as “Voice Game Master,” “Voice Control Expert,” “Open Sesame,” and “Guard Speech Recognition System.” Among these, the “Guard Speech Recognition System” is the only one capable of controlling microcontroller-based hardware!
In 2009, Microsoft released the Windows 7 operating system, which significantly promoted speech recognition software!
Performance Indicators
Indicators
The performance indicators of speech recognition systems mainly include four aspects: 1) Vocabulary range: This refers to the range of words or phrases that the machine can recognize. If there are no restrictions, the vocabulary range can be considered infinite. 2) Speaker restrictions: Whether the system can only recognize the speech of specified speakers or can recognize the speech of any speaker. 3) Training requirements: Whether training is required before use, i.e., whether the machine needs to “listen” to given speech first and how many training sessions are needed. 4) Correct recognition rate: The percentage of correctly recognized instances on average, which is related to the previous three indicators.
Summary
The above has introduced various technical aspects involved in implementing speech recognition systems. These technologies have achieved good results in practical use, but how to overcome various factors affecting speech still requires deeper analysis. Currently, dictation systems cannot fully replace keyboard input, but the maturity of recognition technology simultaneously drives research into higher-level speech understanding technologies. Given the different characteristics of English and Chinese, how to apply technologies developed for English to Chinese is also an important research topic, while issues unique to Chinese, such as tonal variations, remain to be resolved.
Recent Developments
In recent years, especially since 2009, with the advancement of deep learning research in the field of machine learning and the accumulation of large data corpora, speech recognition technology has made rapid progress.
1) New technological developments: 1) The introduction of deep learning research from the field of machine learning into the training of speech recognition acoustic models, using multi-layer neural networks pre-trained with RBM, has significantly improved the accuracy of acoustic models. In this area, researchers from Microsoft have made breakthrough progress, achieving a 30% reduction in speech recognition error rates using deep neural network models (DNN), marking the fastest advancement in speech recognition technology in nearly 20 years.
2) Currently, most mainstream speech recognition decoders have adopted decoding networks based on finite state machines (WFST), which can unify language models, dictionaries, and shared acoustic phoneme sets into a large decoding network, greatly improving decoding speed and providing a foundation for real-time applications of speech recognition.
3) With the rapid development of the internet and the widespread application of mobile terminals, it is now possible to acquire large amounts of text or speech data from multiple channels, providing abundant resources for training language models and acoustic models in speech recognition, making the construction of general large-scale language models and acoustic models feasible. In speech recognition, the matching and richness of training data are among the most important factors driving the improvement of system performance; however, the annotation and analysis of corpora require long-term accumulation and sedimentation. With the advent of the era of big data, the accumulation of large-scale corpus resources will be elevated to a strategic height.
2) New technological applications: Recently, applications of speech recognition on mobile terminals have been the hottest, with voice dialogue robots, voice assistants, and interactive tools emerging one after another. Many internet companies have invested human, material, and financial resources into research and application in this area, aiming to quickly capture customer groups through the novel and convenient mode of voice interaction.
Currently, Apple’s Siri leads the way in foreign applications.
In China, systems such as iFlytek, Yunzhisheng, Shengda, Jietong Huasheng, Sogou Voice Assistant, Ziding Interpretation, and Baidu Voice have adopted the latest speech recognition technologies, and many other relevant products on the market have directly or indirectly embedded similar technologies.