

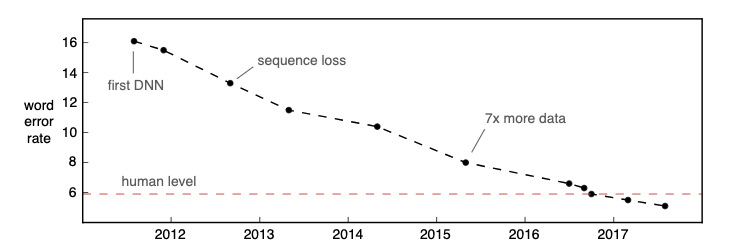
“In the next decade, we will deploy truly multilingual models in production environments, enabling developers to build applications that anyone can understand in any language, thereby truly unleashing the power of speech recognition worldwide.”
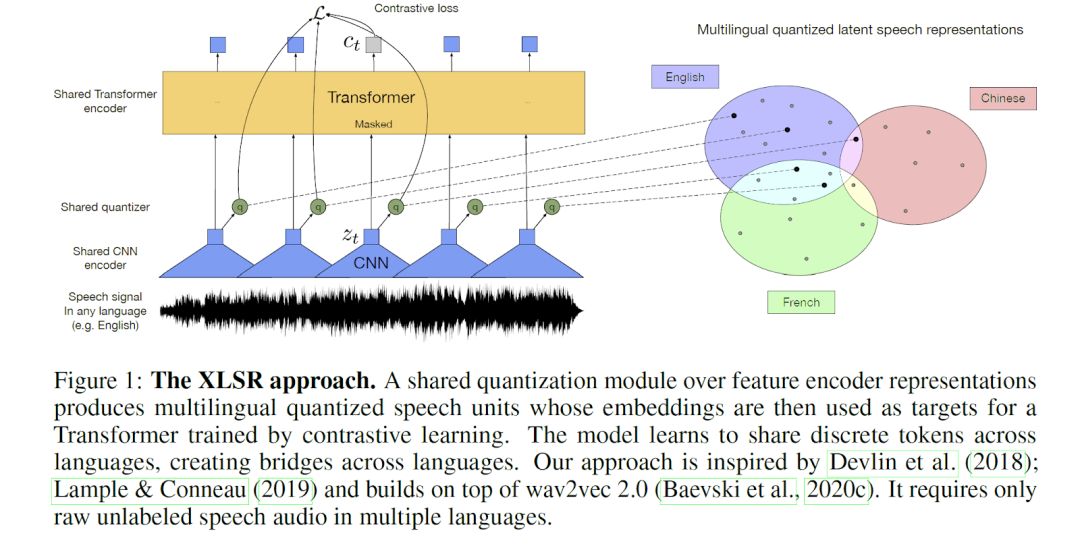
“In the next decade, we believe commercial ASR systems will output richer transcription objects that contain more than just simple words. Additionally, we expect this richer output to be recognized by standard organizations like W3C, so that all APIs will return similarly constructed outputs. This will further unleash the potential of voice applications for everyone in the world.”
Although the National Institute of Standards and Technology (NIST) has a long-standing tradition of exploring “rich transcription,” it has only scratched the surface in terms of standardizing and scalable formats for incorporating it into ASR outputs. The concept of rich transcription originally involved capitalization, punctuation, and diarization, but has somewhat expanded to include speaker roles and a range of non-verbal speech events. Anticipated innovations include transcriptions of overlapping speech from different speakers, different emotions, and other paralinguistic features, as well as transcribing information based on textual or linguistic diversity. Tanaka et al. depicted a scenario where users might wish to choose from different levels of richness in transcription options; clearly, the quantity and nature of the additional information we predict are customizable, depending on downstream applications.
Traditional ASR systems can generate multiple hypotheses grids during the process of recognizing spoken words, which have proven beneficial in human-assisted transcription, spoken dialogue systems, and information retrieval. Including n-best information in the rich output format will encourage more users to utilize ASR systems, thereby improving user experience. While there is currently no standard for constructing or storing additional information generated or potentially generated during the speech decoding process, CallMiner’s Open Voice Transcription Standard (OVTS) has taken solid steps in this direction, making it easier for enterprises to explore and choose multiple ASR vendors.
We predict that in the future, ASR systems will produce richer outputs in standard formats, thereby supporting more powerful downstream applications. For instance, ASR systems might output all possible grids, and applications can utilize this additional data to perform intelligent automated transcription while editing the transcription content. Similarly, ASR transcriptions that include additional metadata (such as detected regional dialects, accents, environmental noise, or emotions) can enable more robust search applications.
“In this decade, large-scale ASR (i.e., privatized, affordable, reliable, and fast) will become a part of everyone’s daily life. These systems will be able to search videos, index all the media content we engage with, and enable consumers with hearing impairments around the world to access every video. ASR will be the key to making every audio and video accessible and actionable.”


We may all be using a lot of audio and video software: podcasts, social media streams, online videos, real-time group chats, Zoom meetings, etc. However, the related content is actually seldom transcribed. Today, content transcription has become one of the largest markets for ASR APIs and will grow exponentially in the next decade, especially considering their accuracy and affordability. That said, ASR transcription is currently only used for specific applications (broadcast videos, certain meetings, and podcasts, etc.). Therefore, many people cannot access this media content, and it is challenging to find relevant information after broadcasts or events end.
In the future, this situation will change. As Matt Thompson predicted in 2010, to some extent, ASR will become cheap and widely popular, to the point where we will experience what he called “speechability.” We expect that almost all audio and video content will be transcribed in the future, and that this content will be immediately accessible, storable, and searchable at scale. However, the development of ASR will not stop there; we also hope that this content will be actionable. We want every audio and video we consume or participate in to provide additional context, such as insights automatically generated from podcasts or meetings, or automatic summaries of key moments in videos, etc. We hope that NLP systems can normalize the processing of the above.
“By the end of this century, we will have evolving ASR systems that function like a living organism, continuously learning with the help of humans or through self-supervision. These systems will learn from different channels in the real world to understand new words and language variants in real-time rather than asynchronously, self-debugging and automatically monitoring different usages.”

As ASR becomes mainstream and covers more use cases, human-machine collaboration will play a crucial role. The training of ASR models embodies this well. Today, open-source datasets and pre-trained models have lowered the entry barrier for ASR vendors. However, the training process remains quite simple: collect data, annotate data, train models, evaluate results, and improve models. But this is a slow process and is prone to errors in many cases due to difficulties in tuning or insufficient data. Garnerin et al. observed that the lack of metadata and inconsistencies in cross-corpus representation make it difficult to ensure equivalent accuracy in ASR performance, which is also an issue that Reid and Walker attempted to address when developing metadata standards.
In the future, humans will efficiently supervise ASR training through intelligent means, playing an increasingly important role in accelerating machine learning. The human-in-the-loop approach places human reviewers within the machine learning/feedback loop, allowing for continuous review and adjustment of model outputs. This will make machine learning faster and more efficient, resulting in higher quality outputs. Earlier this year, we discussed how improvements in ASR enable Rev’s human transcribers (known as “Revvers”) to perform post-editing on ASR drafts, thus enhancing productivity. Revver’s transcriptions can be directly input into improved ASR models, forming a virtuous cycle.
For ASR, one area where human language experts remain indispensable is inverse text normalization (ITN), where they convert recognized strings (like “five dollars”) into the expected written form (like “$5”). Pusateri et al. proposed a hybrid approach using “manual grammar and statistical models,” and Zhang et al. continued this line of thought using handcrafted FST-constrained RNNs.
“Like all AI systems, future ASR systems will adhere to stricter AI ethical principles to ensure that systems treat everyone equally, have a higher degree of interpretability, are accountable for their decisions, and respect the privacy of users and their data.”

Future ASR systems will follow four principles of AI ethics: fairness, interpretability, respect for privacy, and accountability.
Fairness: A fair ASR system can recognize speech regardless of the speaker’s background, socioeconomic status, or other characteristics. Notably, building such a system requires identifying and reducing biases in our models and training data. Fortunately, governments, NGOs, and businesses have begun creating infrastructures to recognize and mitigate biases.
Interpretability: ASR systems will no longer be “black boxes”: they will explain data collection and analysis, model performance, and output processes upon request. This additional transparency requirement can lead to better human oversight over model training and performance. Like Gerlings et al., we view interpretability from the perspective of a range of stakeholders (including researchers, developers, clients, and transcribers in the Rev case). Researchers may want to know why the output text was erroneous to mitigate the issue; while transcribers may need some evidence to justify why ASR came to a particular conclusion to help them assess its validity, especially in noisy situations where ASR may “hear” better than a human. Weitz et al. have taken significant preliminary steps to achieve interpretability for end-users in the context of audio keyword recognition. Laguarta and Subirana have incorporated clinician-guided interpretations into voice biomarker systems for Alzheimer’s detection.
Respect for Privacy: According to various U.S. and international laws, “voice” is considered “personal data,” and thus the collection and processing of voice recordings are subject to strict personal privacy protections. At Rev, we have already provided data security and control features, and future ASR systems will further respect the privacy of user data and model privacy. In many cases, this will likely involve pushing ASR models to the edge (on devices or browsers). Challenges in voice privacy are driving research in this area, and many jurisdictions, such as the EU, have already begun legislative work. The field of privacy-preserving machine learning is expected to draw attention to this critical aspect of technology, enabling it to be widely accepted and trusted by the public.
Accountability: We will monitor ASR systems to ensure they comply with the first three principles. This, in turn, requires investment in resources and infrastructure to design and develop the necessary monitoring systems and take action based on findings. Companies deploying ASR systems will be responsible for the use of their technologies and will make concrete efforts to comply with ASR ethical principles.
It is worth mentioning that as designers, maintainers, and consumers of ASR systems, humans will be responsible for implementing and enforcing these principles—yet another example of human-machine collaboration.
Reference Links:
https://thegradient.pub/the-future-of-speech-recognition/
https://awni.github.io/speech-recognition/