

Source: DeepHub IMBA
This article is approximately 3600 words long, and it is recommended to read it in 7 minutes.
In this article, we will use the visualization library renumics-spotlight to visualize the multi-dimensional embeddings of the FAISS vector space in 2-D, and explore the possibility of improving the accuracy of RAG responses by changing certain key vectorization parameters.
As the performance of open-source large language models continues to improve, there has been a significant enhancement in capabilities such as code writing and analysis, recommendations, text summarization, and question answering (QA). However, when it comes to QA, LLMs often fall short on relevant questions that are not trained on the data, as many internal documents are kept confidential within companies to ensure compliance, trade secrets, or privacy. When querying these documents, LLMs can hallucinate, generating irrelevant, fabricated, or inconsistent content.
One available technique to address this challenge is Retrieve-Augmented Generation (RAG). It involves enhancing the response generation process by referencing authoritative knowledge bases outside of its training data sources before generating a response. RAG applications include a retrieval system that fetches relevant document snippets from a corpus, and an LLM that uses the retrieved snippets as context to generate responses. Therefore, the quality of the corpus and its representation in vector space (known as embeddings) plays a crucial role in the accuracy of RAG.
In this article, we will use the visualization library renumics-spotlight to visualize the multi-dimensional embeddings of the FAISS vector space in 2-D, and explore the possibility of improving the accuracy of RAG responses by changing certain key vectorization parameters. For the LLM we selected, we will use TinyLlama 1.1B Chat, a compact model with the same architecture as Llama 2. Its advantages include lower resource usage and faster runtime, without a proportional decrease in accuracy, making it an ideal choice for quick experiments.
System Design
The QA system consists of two modules, as shown in the figure.
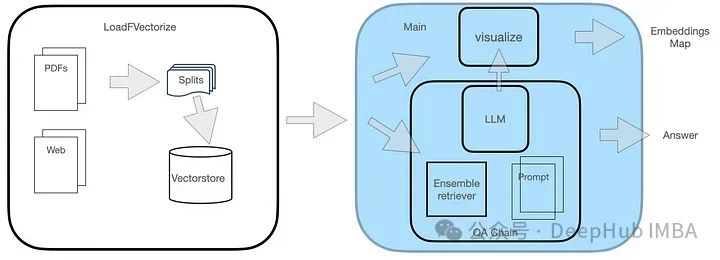
The LoadFVectorize module loads PDF or web documents for initial testing and visualization. The second module loads the LLM and instantiates FAISS retrieval, then creates a retrieval chain containing the LLM, retriever, and custom query prompt. Finally, we visualize its vector space.
Code Implementation
1. Install Necessary Libraries
The renumics-spotlight library uses UMAP-like visualization to reduce high-dimensional embeddings to more manageable 2D visualizations while preserving key attributes. We have previously introduced the use of UMAP, but this time we will integrate it into a fully functional real-world project as a complete system design. First, we need to install the necessary libraries:
pip install langchain faiss-cpu sentence-transformers flask-sqlalchemy psutil unstructured pdf2image unstructured_inference pillow_heif opencv-python pikepdf pypdf pip install renumics-spotlight CMAKE_ARGS="-DLLAMA_METAL=on" FORCE_CMAKE=1 pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dirThe last line above installs the llama-cpp-python library with Metal support, which will be used to load TinyLlama with hardware acceleration on M1 processors.
2. LoadFVectorize Module
The module includes three functions:
load_doc handles loading online PDF documents, splitting each block into 512 characters with a 100-character overlap, and returning a list of documents.
vectorize calls the load_doc function above to get the list of document blocks, creates embeddings, and saves them to the local directory opdf_index, while returning a FAISS instance.
load_db checks if the FAISS library is on disk in the directory opdf_index and attempts to load it, ultimately returning a FAISS object.
The complete code for this module is as follows:
# LoadFVectorize.py
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.document_loaders import OnlinePDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
# access an online pdf
def load_doc() -> 'List[Document]':
loader = OnlinePDFLoader("https://support.riverbed.com/bin/support/download?did=7q6behe7hotvnpqd9a03h1dji&version=9.15.0")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
return docs
# vectorize and commit to disk
def vectorize(embeddings_model) -> 'FAISS':
docs = load_doc()
db = FAISS.from_documents(docs, embeddings_model)
db.save_local("./opdf_index")
return db
# attempts to load vectorstore from disk
def load_db() -> 'FAISS':
embeddings_model = HuggingFaceEmbeddings()
try:
db = FAISS.load_local("./opdf_index", embeddings_model)
except Exception as e:
print(f'Exception: {e}\nNo index on disk, creating new...')
db = vectorize(embeddings_model)
return db3. Main Module
The main module initially defines the following template for the TinyLlama prompt:
<|system|>{context}</s><|user|>{question}</s><|assistant|>
Additionally, using the quantized version of TinyLlama from TheBloke can significantly reduce memory usage; we choose to load the quantized LLM in GGUF format.
Then, using the FAISS object returned from the LoadFVectorize module, we create a FAISS retriever, instantiate RetrievalQA, and use it for querying.
# main.py
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain_community.llms import LlamaCpp
from langchain_community.embeddings import HuggingFaceEmbeddings
import LoadFVectorize
from renumics import spotlight
import pandas as pd
import numpy as np
# Prompt template
qa_template = """<|system|> You are a friendly chatbot who always responds in a precise manner. If answer is unknown to you, you will politely say so. Use the following context to answer the question below: {context}</s> <|user|> {question}</s> <|assistant|> """
# Create a prompt instance
QA_PROMPT = PromptTemplate.from_template(qa_template)
# load LLM
llm = LlamaCpp(
model_path="./models/tinyllama_gguf/tinyllama-1.1b-chat-v1.0.Q5_K_M.gguf",
temperature=0.01,
max_tokens=2000,
top_p=1,
verbose=False,
n_ctx=2048
)
# vectorize and create a retriever
db = LoadFVectorize.load_db()
faiss_retriever = db.as_retriever(search_type="mmr", search_kwargs={'fetch_k': 3}, max_tokens_limit=1000)
# Define a QA chain
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=faiss_retriever,
chain_type_kwargs={"prompt": QA_PROMPT}
)
query = 'What versions of TLS supported by Client Accelerator 6.3.0?'
result = qa_chain({"query": query})
print(f'--------------\nQ: {query}\nA: {result["result"]}')
visualize_distance(db,query,result["result"])The visualization of the vector space itself is handled by the last line of the above code visualize_distance:
visualize_distance accesses the properties of the FAISS object __dict__, where index_to_docstore_id itself is a key index dictionary for the values of docstore-ids, and the total document count used for vectorization is represented by the index object’s property ntotal.
vs = db.__dict__.get("docstore")
index_list = db.__dict__.get("index_to_docstore_id").values()
doc_cnt = db.index.ntotalBy calling the method reconstruct_n of the index object, an approximate reconstruction of the vector space can be achieved.
embeddings_vec = db.index.reconstruct_n()With the docstore-id list as index_list, we can find the relevant document objects and use them to create a list that includes docstore-id, document metadata, document content, and its embeddings in the vector space of all ids:
doc_list = list()
for i,doc-id in enumerate(index_list):
a_doc = vs.search(doc-id)
doc_list.append([doc-id,a_doc.metadata.get("source"),a_doc.page_content,embeddings_vec[i]])We then create a DataFrame (DF) with column headers from the list, and we will use this DF for visualization.
df = pd.DataFrame(doc_list,columns=['id','metadata','document','embedding'])Before proceeding with visualization, we also need to combine the question and answer, creating a separate DF for the question and answer, and then merging it with the above DF, allowing us to highlight where the question and answer appear during visualization:
# add rows for question and answer
embeddings_model = HuggingFaceEmbeddings()
question_df = pd.DataFrame(
{
"id": "question",
"question": question,
"embedding": [embeddings_model.embed_query(question)],
})
answer_df = pd.DataFrame(
{
"id": "answer",
"answer": answer,
"embedding": [embeddings_model.embed_query(answer)],
})
df = pd.concat([question_df, answer_df, df])Here, we use np.linalg.norm to calculate the distance size on the embeddings of the document and the question:
question_embedding = embeddings_model.embed_query(question)
# add column for vector distance
df["dist"] = df.apply(
lambda row: np.linalg.norm(
np.array(row["embedding"]) - question_embedding
),axis=1,)Since spotlight can visualize the DF, we can call it directly.
spotlight.show(df)This step will launch spotlight in a browser window.
Running Tests
1. Basic Tests
Here are the sample questions we selected:
What versions of TLS supported by Client Accelerator 6.3.0?The correct answer is:
Client Accelerator 6.3.0 supports TLS 1.1 or 1.2.The following additional information may be included in the response.
You must enable this capability using the following CLI command on the Client Accelerator:(config) # policy id <id-number> ssl backend client-tls-1.2 Even though TLS 1.1 is not mentioned in the syntax of this command, using this command automatically enables support for both TLS 1.1 and 1.2.
Next, let’s see how TinyLlama responds to the above question:
Client Accelerator 6.3.0 supports TLS 1.1 or 1.2 as the default supported TLS versions with Client Accelerator. You must enable this capability using the following CLI command on the Client Accelerator:“`(config) # policy id <id-number> ssl backend client-tlss1.2“`Note that this command only applies to TLS 1.1 or TLS 1.2. If you need to support older TLS versions, you can use the ssl backend command with the client-tlss1.0 or client-tlss1.1 option instead.
It seems to be very similar to the actual answer, but it is not entirely correct since these TLS versions are not their defaults.
So let’s see from which paragraphs it found the answer?
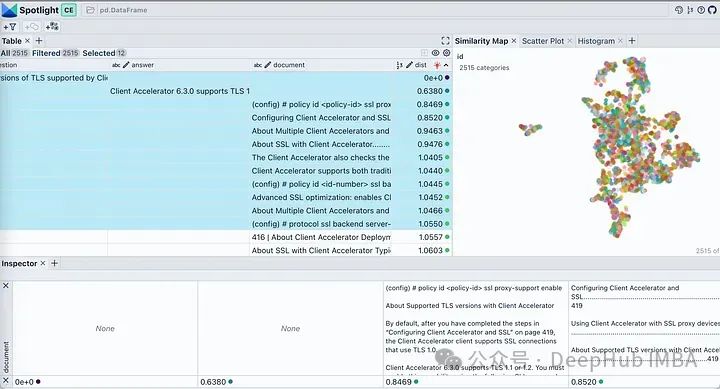
In spotlight, you can use the visible button to control the columns displayed. Sort the table by “dist” to show the question, answer, and the most relevant document snippets at the top. Looking at the embeddings of our documents, it describes almost all document blocks as a single cluster. This is reasonable since our original PDF is a deployment guide for a specific product, so it is not surprising that it is considered a single cluster.
Click on the filter icon in the Similarity Map tab to highlight only the selected list of documents, with the rest displayed in gray, as shown below.
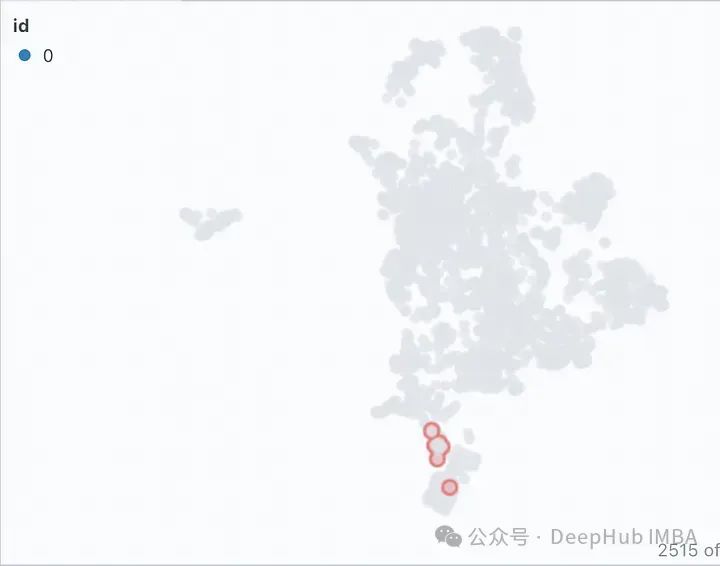
2. Testing Block Size and Overlap Parameters
Since the retriever is a key factor affecting RAG performance, let’s take a look at several parameters that influence the embedding space. The TextSplitter’s block size (1000,2000) and/or overlap (100,200) parameters differ during document splitting.
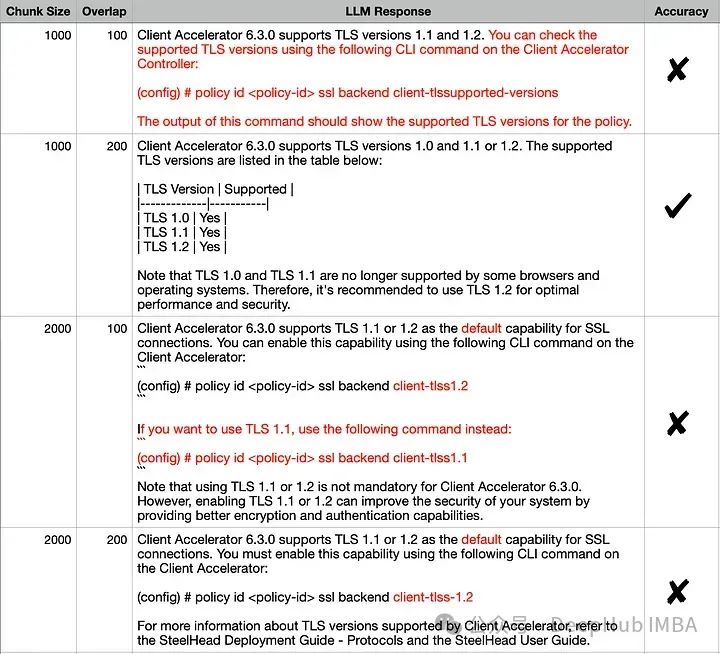
The outputs for all combinations seem similar, but if we carefully compare the correct answer and each response, the accurate answer is (1000,200). The incorrect details in the other responses have been highlighted in red. Let’s try to explain this behavior using visualized embeddings:
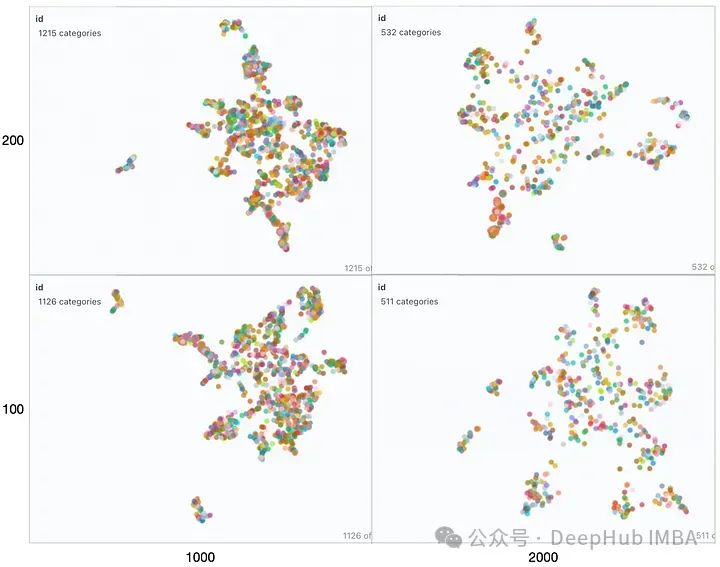
From left to right, as the block size increases, we can observe that the vector space becomes sparse and the blocks are smaller. From bottom to top, the overlap gradually increases, and there is no significant change in the features of the vector space. In all these mappings, the entire set still presents more or less as a single cluster with only a few outliers present. This is reflected in the generated responses, which are very similar.
If the query is at the center of the cluster, the responses are likely to change significantly when these parameters vary, due to different nearest neighbors. If the RAG application cannot provide the expected answer for certain questions, analyzing these questions by generating visualizations similar to the above may help find optimal ways to partition the corpus to improve overall performance.
To further illustrate, we will visualize the vector spaces of two Wikipedia documents from unrelated fields (Grammy Awards and JWST telescope).
def load_doc():
loader = WebBaseLoader(['https://en.wikipedia.org/wiki/66th_Annual_Grammy_Awards','https://en.wikipedia.org/wiki/James_Webb_Space_Telescope'])
documents = loader.load()
...Only the above code has been modified, while the rest remains unchanged. Running the modified code, we obtain the vector space visualization shown below.
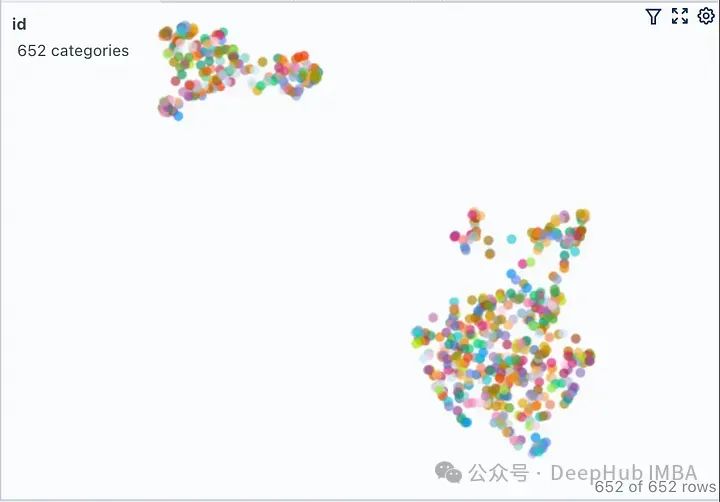
Here, there are two different non-overlapping clusters. If we were to ask a question outside of either cluster, obtaining context from the retriever would not only be unhelpful for the LLM, but it is also likely to be detrimental. Let’s pose the same question as before and see what “hallucinations” our LLM generates.
Client Accelerator 6.3.0 supports the following versions of Transport Layer Security (TLS):
-
TLS 1.2
ewline TLS 1.3
ewline TLS 1.2 with Extended Validation (EV) certificates
ewline TLS 1.3 with EV certificates
ewline TLS 1.3 with SHA-256 and SHA-384 hash algorithms
Here we use FAISS for vector storage. If you are using ChromaDB and want to know how to perform similar visualizations, renumics-spotlight is also supported.
Conclusion
Retrieve-Augmented Generation (RAG) allows us to leverage the capabilities of large language models to achieve good results even when the LLM has not been trained on internal documents. RAG involves retrieving many relevant document blocks from a vector database, which the LLM then uses as context for generation. Therefore, the quality of the embeddings will play an important role in RAG performance.
In this article, we demonstrated and visualized the impact of several key vectorization parameters on the overall performance of the LLM. Using renumics-spotlight, we showed how to represent the entire FAISS vector space and then visualize the embeddings. The intuitive user interface of Spotlight helps us explore the vector space based on questions, leading to a better understanding of the LLM’s responses. By adjusting certain vectorization parameters, we can influence its generation behavior to improve accuracy.
Editor: Yu Tengkai
Proofreader: Liang Jincheng
