

This article is approximately 5500 words long and is recommended for an 11-minute read.
This paper proposes a pseudo-graph structure by relaxing the pattern constraints on data and relationships in traditional KGs.

1. Research Motivation
Retrieval-Augmented Generation (RAG) provides a cost-effective knowledge updating strategy for large language models (LLMs) by integrating external retrieval libraries, thus expanding the knowledge boundaries of LLMs. However, the quality of data essentially determines the upper limit of retrieval performance. Therefore, how to mine and organize vast knowledge while ensuring data quality from the source is the primary issue in the current RAG research field.
Knowledge Refinement is commonly used in the indexing phase before retrieval because it can remove irrelevant or redundant information, significantly reducing the storage costs of knowledge bases. For example, in RAG methods based on Knowledge Graphs (KGs), text is often transformed into KGs to capture deep semantics between different granular knowledge islands. This knowledge refinement method, which aggregates concepts, can provide LLMs with related structured contextual information by explicitly revealing implicit relationships, thus supporting more complex reasoning.
However, in most cases, constructing strict and complete KGs is extremely difficult and unnecessary, as LLMs themselves possess powerful semantic understanding capabilities and can perform structured reasoning on flexible semi-structured data. To this end, we relaxed the strict constraints of KG schema on data and relationship patterns and constructed a morphological structure between traditional KGs and chunk splitting – the pseudo-graph (PG).
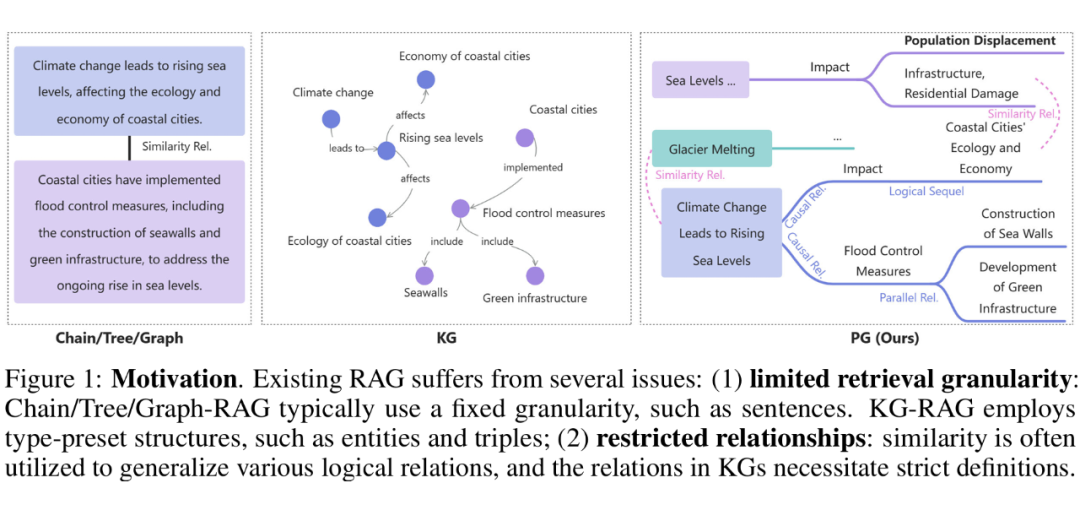
As shown in Figure 1, we connect different granular knowledge extracted from multiple news documents in a marked logical manner to form an optimized, knowledge-dense, and flexible representation retrieval knowledge structure PG. This intermediate morphological structure retains the knowledge and compressibility of KGs while also possessing the generality of ordinary chunk divisions, effectively avoiding the distraction of the generator’s attention by irrelevant noise information.
Next, we incorporated PG into the preprocessing RAG framework. The proposed PG-RAG not only ensures that LLMs can quickly access background information, reducing response generation latency, but also effectively filters out irrelevant details, enhancing the relevance of recall and response content. Specifically, in the retrieval phase, PG-RAG mimics the human behavior of flipping through notes, using the pseudo-graph index to adaptively walk through the pseudo-graph knowledge base, collecting and integrating structured contextual information into LLMs, alleviating the hallucination generation phenomenon caused by evidence absence.
Experimental results show that under a text reduction rate of up to 2.64 in single-document tasks, PG-RAG significantly outperforms the current best benchmark KGP-LLaMA on all key evaluation metrics, with an overall performance improvement of approximately 11.6%. Among them, the BLEU score improved by about 14.3%, and the QE-F1 increased by about 23.7%. In multi-document scenarios, the average performance of PG-RAG is at least about 2.35% higher than the best benchmark. Meanwhile, its BLEU and QE-F1 steadily improved by about 7.55% and 12.75%.
2. Background Review
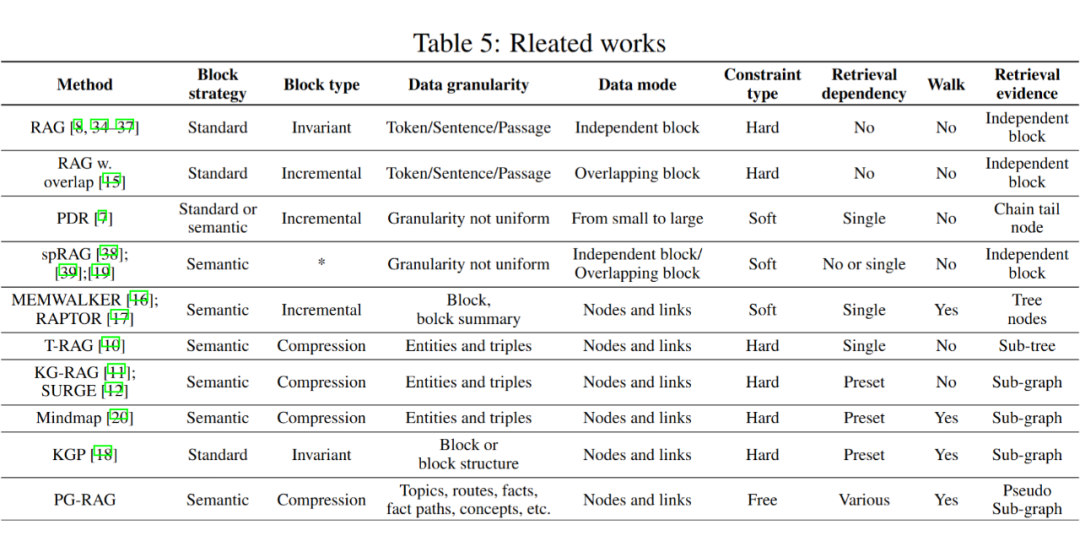
In knowledge base construction, i.e., the indexing phase, we first need to clean and extract the original data, converting it into a unified pure text format. We also need to chunk the text to fit the context limitations in LLMs, and then obtain the embeddings of the chunks for subsequent vector retrieval. As shown in the table above, existing indexing construction methods are mainly divided into the following categories:
1. Standard chunking divides data into fixed-size chunks;
2. Chained chunking allows for linear associations between chunks, with small chunks used for retrieval and large chunks for recall;
3. Tree-based chunking, such as MEMWALKER and RAPTOR, forms a hierarchical retrieval structure by extracting and consolidating paragraphs and their summaries into a summary tree; unlike incremental indexing construction methods that add global information;
4. Compression-based indexing construction strategies refine and organize text, filtering out noise while preserving the relationships between knowledge. For example, T-RAG enhances context by extracting entities and their affiliations to form an entity tree;
5. Some methods simplify the schema of KGs to reduce the complexity of knowledge construction, making it easier to maintain. For example, Graph-RAG and KGP perform knowledge fusion using a “clustering + semantic edge” method on fixed chunks, but such knowledge refinement lacks exploration and representation of the rich relationships between knowledge.
Our proposed PG-RAG utilizes the general learning capability of LLMs to autonomously organize document content, directly using the generated clear and coherent hierarchical mind map as the knowledge (pseudo-graph) index that needs to be retained in long-term memory, avoiding the inherent or human preset schema constraints.
Specifically, the essence of the pseudo-graph indexing construction strategy is to establish a simple and commonly used memory schema based on KGs without schema restrictions: it guides knowledge from broad supertopics to gradually focus on specific topics, routing through multiple explicit keyword paths to specific facts, and then extending to more similar or complementary related facts. This method allows PG to maintain a global perspective while having the potential to deeply mine local details.
3. Construction of the Pseudo-Graph

3.1 Extraction and Verification of Factual Check Items (FCIs)
Extracting FCIs: We first transform the original text into verifiable factual check text containing FCIs (extracted by LLMs). It is important to note that LLMs focus on identifying key facts that can verify the original text. This goal-oriented verification extraction method allows LLMs to concentrate on verifiable facts that can directly support or refute the original statement, thus avoiding hallucinations caused by missing context or misinterpretation as much as possible.
These information items can be fine-grained (such as specific data, dates, and locations) or coarse-grained (such as opinions or policies). Pre-transforming the text in this way before generating the mind map ensures that factual knowledge is not overlooked.

Verifying FCIs: To ensure that the extracted FCIs are consistent with the original text, we sequentially verify the FCIs obtained from each article. Specifically, we used a comprehensive evaluation function combining BERT-Score and ROUGE-L metrics to assess the performance of FCIs in terms of semantic similarity and detail recall against the original text:
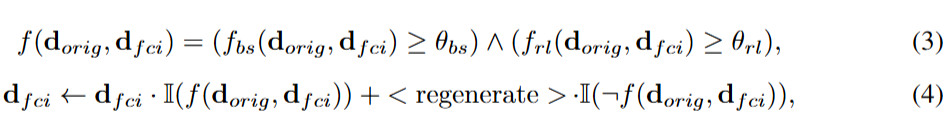
For the original text that did not pass verification, we regenerate FCIs using LLMs until verification is successful.
3.2 Mind Map Generation (Organizing Knowledge Within Documents)
We convert the verified FCIs into a hierarchical mind map:
-
Input the verified FCIs and their corresponding main themes (MT) into LLMs.
-
Prompt LLMs to transform FCIs into a mind map centered around MT. The resulting mind map is clear in expression and coherent in context, linking various types of knowledge such as the document’s topics, keywords (routes), and facts into multiple knowledge routing chains (fact paths).
3.3 Knowledge Fusion (Building Relationships Between Documents)
We cluster and link multiple independent mind maps to form a pseudo-graph network:
-
Learning Knowledge Embeddings (Building Mind Map Index): By extracting and stitching node attributes along the fact paths, we generate an embedding vector for each node containing rich contextual information to capture knowledge from the topic to that node:
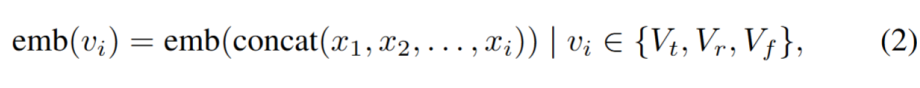
-
Building Clusters: Calculate the similarity between node embedding vectors, clustering similar nodes into one category and assigning a unique super node to each category.
-
Knowledge Linking: Establish similar links between intra-class nodes and corresponding super nodes, enhancing the network’s navigability and information accessibility by relating previously isolated mind maps through similar themes or complementary facts.

Through these three steps, we achieved the extraction, organization, and fusion of knowledge, forming a flexible structured knowledge network for indexing. Compared to strict KGs (which have data pattern constraints, such as fixing “The Biography of Steve Jobs” to the entity type of book title or book), the pseudo-graph relaxes data pattern constraints, allowing data to be adaptively divided according to different contexts. For example, “The Biography of Steve Jobs” can serve as different types of nodes:
-
Providing a topic entity as the starting point for the mind map. For example, the following fact paths demonstrate “The Biography of Steve Jobs” as a topic, connecting specific content in the biography:
-
“The Biography of Steve Jobs” -> Jobs’ life story -> …
-
“The Biography of Steve Jobs” -> Jobs’ career -> …
-
“The Biography of Steve Jobs” -> Jobs’ personal life -> …
-
Providing fact entities that are directly related to the topic with detailed data or descriptions. For example, under the theme of “The American Publisher Simon & Schuster Releases Publishing News”, “The Biography of Steve Jobs” can directly serve as a fact entity related to the publication information:
-
“The American Publisher Simon & Schuster Releases Publishing News” -> Published Book -> “The Biography of Steve Jobs”
-
Serving as a routing entity that acts as an intermediary information node between topic entities and fact entities, helping to clarify and guide the knowledge transmission path. For example, in the theme of “Biography Reading Records”, “The Biography of Steve Jobs” can be used for navigation, demonstrating the insights brought by the biography:
-
“Biography Reading Records” -> “The Biography of Steve Jobs” -> Insights -> Innovative Spirit …
-
“Biography Reading Records” -> “The Biography of Steve Jobs” -> Insights -> Leadership …
-
“The American Publisher Simon & Schuster Releases Publishing News” -> “The Biography of Steve Jobs” -> Release Date -> …
-
“The American Publisher Simon & Schuster Releases Publishing News” -> “The Biography of Steve Jobs” -> Market Response -> …
At the same time, the pseudo-graph also relaxes the preset constraints of relationships. Relationships in KGs are usually predefined and highly constrained, while the pseudo-graph adopts a more general and flexible representation of relationships. Compared to fixed similarity relationships or predefined complex relationships, the navigation lines of the pseudo-graph can implicitly represent richer types of relationships, including parallel, causal, logical subsequent, etc. These relationships are automatically determined based on the context and content of the data itself, accurately reflecting the actual connections between knowledge points.
4. Retrieval with Pseudo-Graph
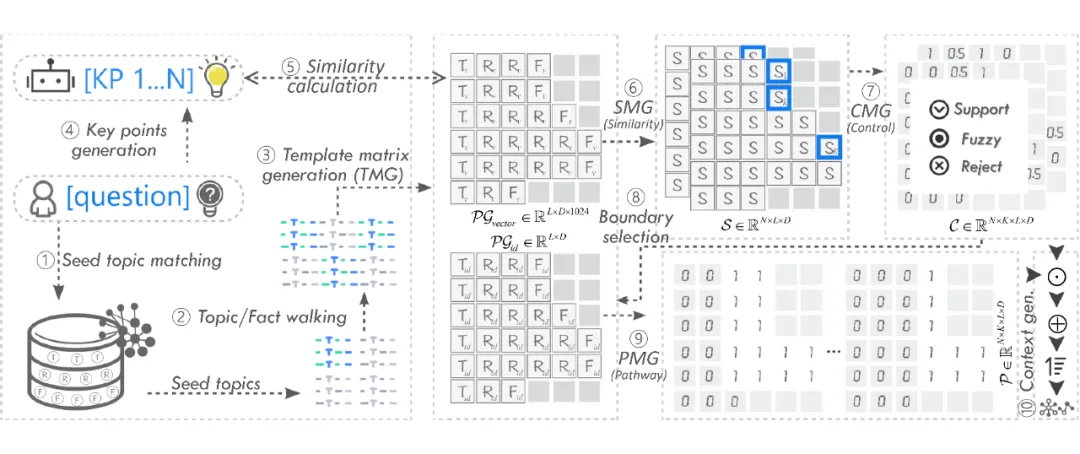
4.1 Key Information Localization
We first use LLMs to convert queries into key answering points (KPs) to assist the retriever in recalling specific information from the PG knowledge base. For example, for a simple factual query like “What is the trend of dry eye disease?”, the answering point could be “The trend of dry eye disease is increasing or decreasing”. For queries like “What environmental factors may exacerbate dry eye symptoms in children?”, the model can generate multi-faceted answering points such as screen time and indoor air quality, ensuring a comprehensive response.
4.2 Reverse DFS Context Expansion
Once key points are identified, people typically select further context for evidence refinement. Our designed pseudo-graph retrieval algorithm (PGR) references this retrieval intuition, performing reverse DFS search at the anchor nodes located on the pseudo-graph. For instance, for the question “What flood prevention measures has Beijing implemented?”, PGR first locates the fact path “Beijing -> Flood Prevention Measures -> Work Stoppage”, and then, starting from the anchor node “Work Stoppage”, the routing node “Flood Prevention Measures” can more comprehensively support the query.
For detailed questions like “What is the difference between work stoppage and production stoppage in flood prevention measures?”, the node “Production Stoppage” under “Flood Prevention Measures” has a higher contribution than “Class Suspension” and can serve as an anchor node to supplement knowledge supporting the question. At the same time, to improve efficiency, we simulate the natural selection method of gradually performing DFS from the anchor node in the matrix, pre-loading the IDs required for walking and evaluating the vectors needed as a template matrix for parallel execution of candidate node importance evaluation and selection. The ID template matrix records the complete path IDs from root node to leaf node. The vector template matrix stores the knowledge embeddings at corresponding positions.
4.3 Control Matrix Generation
For each anchor node, we generate a control matrix to assess the contribution of candidate nodes to that node. The specific control conditions are as follows:
-
Support: If the similarity difference is less than the support threshold (e.g., 0.03), the contribution weight of the candidate node is set to 1.
-
Ambiguous: If the similarity difference is between the support threshold and the ambiguous threshold (e.g., 0.05), the contribution weight is set to 0.5.
-
Reject: If the similarity difference exceeds the ambiguous threshold, the contribution weight is set to 0.
Next, we calculate the contribution value of candidate nodes, contribution weight × node importance (similarity of node to KP), and then perform initial restrictions on the walking boundaries:
-
Starting from the anchor node, traverse left, calculate and record contribution values until reaching a position where the contribution value is 0, determining the left boundary.
-
Then traverse other rows from the left boundary to the right, calculating and recording contribution values, stopping at the position where the contribution value is 0, thus not expanding subsequent child nodes, ultimately generating the control matrix (CM) corresponding to that anchor node.
4.4 Path Matrix Generation
To further refine the reachable range starting from the anchor node, ensuring that control and selection are performed only on reachable candidate nodes, we extract the path range from the anchor node to the upper limit parent node (in the control matrix generation process, the last non-zero contribution value node position traversed to the left from the anchor node is the upper limit “parent node” position).
In the template matrix, we can trace the path from any leaf node to the parent node by left traversing the rows. To explore the paths of child nodes reachable from any parent node, we only need to find all positions in the ID template matrix where the ID equals that parent node ID, which serves as the index for common parent nodes. By traversing to the right from these index positions, we can find all traversal paths starting from that parent node. In the ID matrix, all paths of common parent nodes typically appear in consecutive rows.
Thus, the DFS from any leaf node to a certain parent node can be transformed into determining the boundaries of local continuous rows containing that parent node. Specifically, the left boundary is the column index of the upper limit parent node, while the upper and lower boundaries are determined by the starting and ending row indices of the common parent.
Next, we traverse to the right in parallel from these boundary positions until we find a non-empty ID to determine the right boundary, then set the values within the area to 1, and the rest to 0, forming a path matrix (PM) indicating the connected candidates starting from that anchor node.
4.5 Structured Context Generation
Dyeing Matrix: We perform a dot multiplication between the control matrix CM corresponding to each anchor node and the path matrix PM to generate a dyeing matrix. Specifically, a node is only “dyed” when selected, and the intensity of its coloring depends on the similarity of that node to the key points (KP) and its support for the anchor node. The same node can be dyed multiple times based on different queries or anchor nodes, with varying degrees of dyeing.
Aggregation Matrix: By stacking all dyeing matrices from anchor nodes, we form an aggregation matrix. Each element in this matrix records the total “color intensity” of the candidate node across multiple subgraphs guided by anchor nodes, i.e., the total contribution value for the query.
Context Selection: We select the row with the highest total contribution value from the aggregation matrix (fact path) and integrate it into a mind map format in the knowledge base to support answering questions.


5. Summary of Experimental Highlights
5.1 Dataset
In this experiment, we selected three question-answering (QA) datasets from the CRUD-RAG benchmark to evaluate the performance of the RAG system in knowledge-intensive applications, including the model’s ability to answer single-document factual questions and to reason by integrating information from multiple documents:
-
Single-Document QA focuses on fact-based question answering, examining the model’s ability to precisely locate and extract relevant information.
-
Two-Document QA tests whether the model can utilize information from two documents for reasoning and integration.
-
Three-Document QA contains questions that require the model to synthesize information from three documents simultaneously, further increasing the difficulty of the task and demanding deeper understanding and analysis capabilities from the model.
5.2 Baselines
-
Base Model (w/o RAG): GPT-3.5
-
Traditional RAG: Keyword Retrieval (BM25), Dense Retrieval (DPR), Hybrid Search (BM25+DPR), Hybrid Search + Re-ranking
-
Tree-based RAG: Tree Traversal, Collapsed Tree Retrieval
-
Graph-based RAG: Graph-RAG, KGP
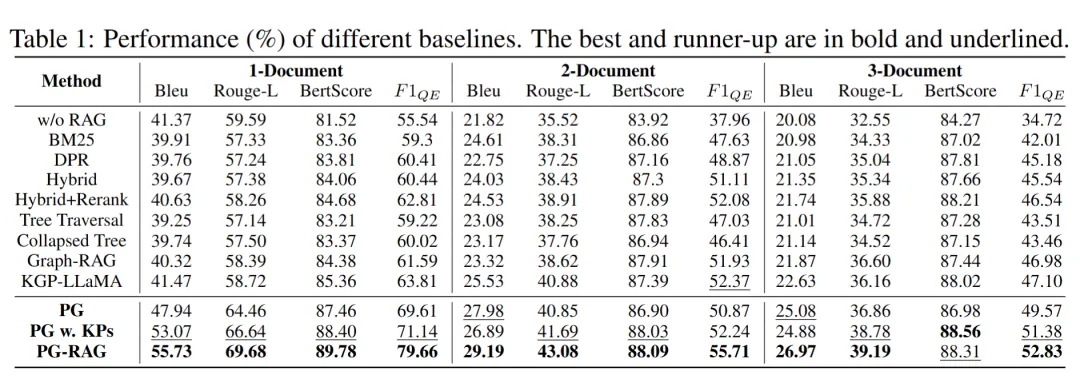
5.3 Overall Comparison
-
Traditional RAG methods perform well, outperforming the direct use of base generative models, especially those employing hybrid re-ranking mechanisms.
-
Tree-based RAG methods perform poorly on large datasets due to poor aggregation effects, information overload from individual nodes, and high noise.
-
Graph-based RAG methods (Graph-RAG and KGP) outperform other baseline methods in multi-document tasks, but the advantage is not significant in single-document tasks.
-
PG-RAG benefits from its refined pseudo-graph structure and walking-based context expansion mechanism, performing excellently across tasks of varying difficulty.
5.4 Knowledge Construction Method Analysis
-
Traditional RAG only performs simple chunking, while tree-based and graph-based RAG establish relational information between chunks through fusion algorithms but do not change the original embedding distribution of knowledge. PG-RAG, by utilizing LLMs for semantic segmentation, achieves a more dispersed factual embedding distribution conducive to clustering, i.e., knowledge fusion.
-
RAPTOR Cluster performs poorly on large datasets, and KNN clustering is time-consuming, while the knowledge fusion speed and effectiveness of the PG-RAG method are excellent.
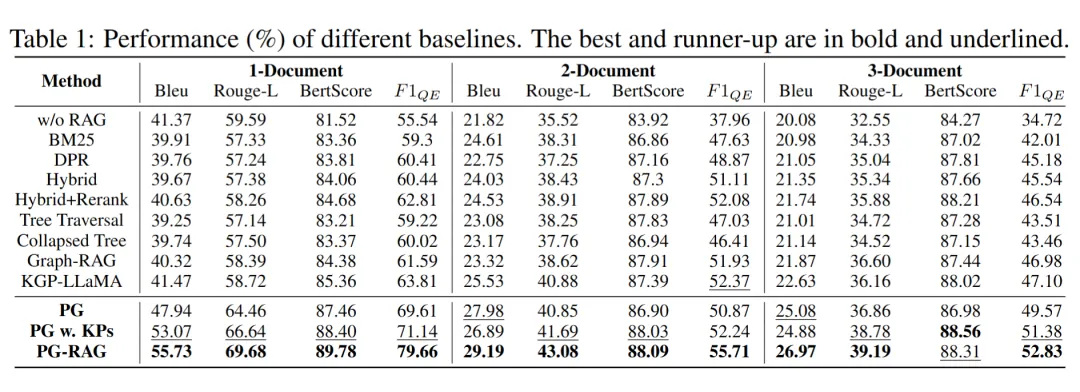
5.5 Knowledge Construction Result Analysis
The fused pseudo-graph exhibits excellent knowledge granularity and density, containing rich knowledge nodes and retaining high-quality relationships. Most importantly, compared to the invariant data chunking strategy, PG-RAG achieves a knowledge compression rate of up to 2.64, effectively reducing the interference of irrelevant information.
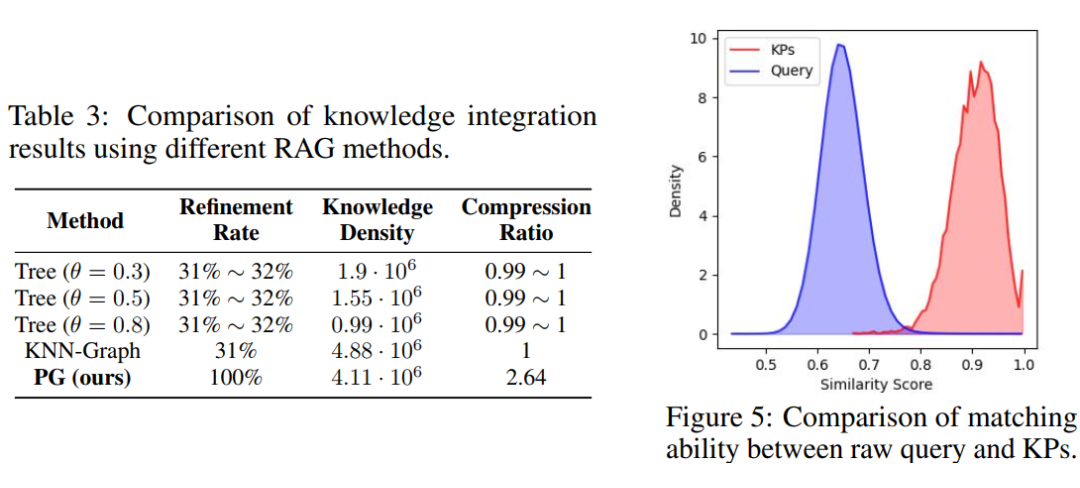
5.6 Pseudo-Graph Retrieval Impact Analysis
Compared to directly using the original query, the KPs used by PGR can more accurately reflect the query intent, improving the recall rate of evidence. Moreover, the complexity of performing DFS on the matrix structure is O(m+3n), which is superior to the traditional DFS complexity of O(m×n), as the tree depth n is typically small, around 3 to 5.
6. Conclusion
The pseudo-graph structure proposed in this paper aims to construct a more flexible and adaptive knowledge network by relaxing the pattern constraints on data and relationships in traditional KGs. It can flexibly partition data according to context, represent diverse relationships, and form a more comprehensive and systematic knowledge index, thereby improving the organization and access efficiency of knowledge and supporting complex reasoning and analysis tasks.
About Us
Data Party THU, as a data science public account backed by the Tsinghua University Big Data Research Center, shares the latest trends in cutting-edge data science and big data technology innovations, continuously disseminating data science knowledge, and striving to build a talent aggregation platform for data, creating the strongest group in China’s big data.

Weibo: @Data Party THU
WeChat Video Account: Data Party THU
Today’s Headlines: Data Party THU