
Click the “Little White Learns Vision” above, and choose to add “Bookmark” or “Pin“
Important content delivered firstEditor’s Recommendation
This article explores logic gate networks aimed at machine learning tasks through learning combinations of logic gates. These networks consist of logic gates such as AND and XOR. To achieve effective training, this article proposes differentiable logic gate networks, an architecture that combines real-valued logic with continuous parameterization relaxation of networks.
Reprinted from丨Machine Heart
With the successful application of neural networks, various research and institutions have been committed to achieving fast and efficient computation, especially during inference. Various technologies have emerged, including reducing computational precision, binary, and sparse neural networks. In this paper, researchers from Stanford University, Salzburg University, and other institutions aim to train a different architecture widely used in the computing field: logic gate networks.
The challenge of training discrete component networks like logic gates is that they are non-differentiable, and thus generally cannot be optimized through standard methods like gradient descent. The researchers propose a method that is a non-gradient optimization method, such as evolutionary training, which is suitable for small models but not for large ones.
This work explores logic gate networks for machine learning tasks. These networks consist of logic gate circuits such as “AND” and “XOR”, which can execute tasks quickly. The difficulty with logic gate networks is that they are typically non-differentiable, preventing training via gradient descent. Therefore, the emergence of differentiable logic gate networks aims to enable effective training. The resulting discrete logic gate networks achieve fast inference speeds, processing over a million MNIST images per second on a single CPU core. This paper was selected for NeurIPS 2022.

-
Paper link: https://arxiv.org/pdf/2210.08277.pdf
-
Project link: https://github.com/Felix-Petersen/difflogic
NYU Computer Science Professor Alfredo Canziani stated: Learnable combinatorial networks composed of logic gates (like AND and XOR) allow for very fast task execution and hardware implementation.

Only three months have passed since the paper was published, and the author Felix Petersen stated that the official implementation of this research has been released. They launched the difflogic project, which is a library for differentiable logic gate networks based on PyTorch. Moreover, after optimization, the current training speed is 50-100 times faster than the initial speed, thanks to the highly optimized CUDA kernels provided by this research.
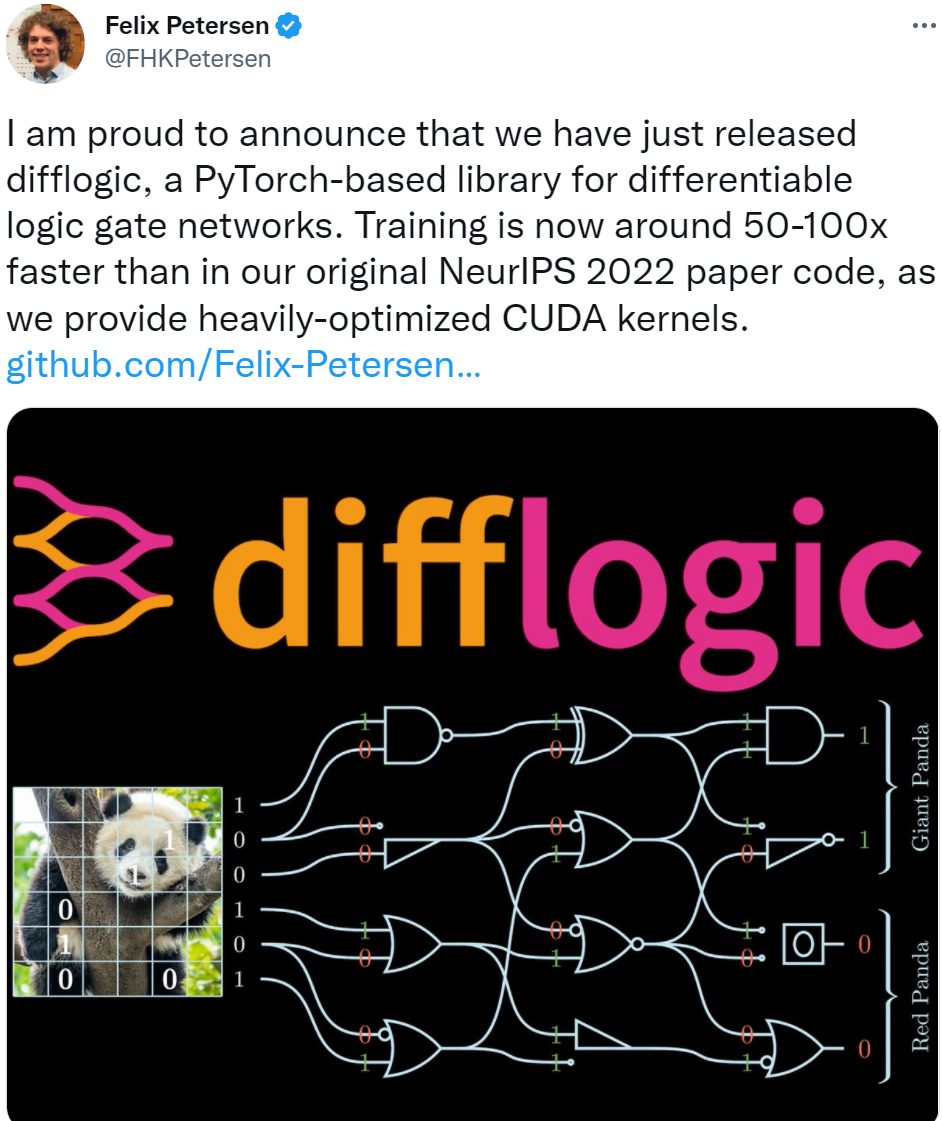
Project Introduction

Difflogic is a library based on Python 3.6+ and PyTorch 1.9.0+ for training and inference using logic gate networks. The installation code for this library is as follows:
pip install difflogicIt is important to note that using difflogic also requires CUDA, the CUDA toolkit (for compilation), and torch >= 1.9.0 (matching the CUDA version).
Below is an example of defining a differentiable logic network model for the MNIST dataset:
from difflogic import LogicLayer, GroupSumimport torch
model = torch.nn.Sequential( torch.nn.Flatten(), LogicLayer(784, 16_000), LogicLayer(16_000, 16_000), LogicLayer(16_000, 16_000), LogicLayer(16_000, 16_000), LogicLayer(16_000, 16_000), GroupSum(k=10, tau=30))This model takes a 784-dimensional input and returns k=10, corresponding to the 10 classes of MNIST. The model can be trained using torch.nn.CrossEntropyLoss, similar to training other neural network models in PyTorch. It is worth noting that the Adam optimizer (torch.optim.Adam) can be used for training, with the recommended default learning rate being 0.01 instead of 0.001. Finally, it is also important to note that compared to traditional MLP neural networks, the number of neurons in each layer of logic gate networks is much higher, as the latter is very sparse.
To delve deeper into the details of these modules, here are some more detailed examples:
layer = LogicLayer( in_dim=784, # number of inputs out_dim=16_000, # number of outputs device='cuda', # the device (cuda / cpu) implementation='cuda', # the implementation to be used (native cuda / vanilla pytorch) connections='random', # the method for the random initialization of the connections grad_factor=1.1, # for deep models (>6 layers), the grad_factor should be increased (e.g., 2) to avoid vanishing gradients)Model Inference
During training, the model should remain in PyTorch training mode, i.e., .train(), which keeps the model differentiable. Now there are two modes for fast inference:
-
The first option is to use PackBitsTensor. PackBitsTensors allow for efficient dynamic execution of trained logic gate networks on the GPU.
-
The second option is to use CompiledLogicNet. CompiledLogicNet allows for efficient execution of fixed-trained logic gate networks on the CPU.
Below are some experimental examples included in the experiments directory. main.py is used for execution, and main_baseline.py contains the baseline of the neural network.
MNIST
python experiments/main.py -bs 100 -t 10 --dataset mnist20x20 -ni 200_000 -ef 1_000 -k 8_000 -l 6 --compile_model
python experiments/main.py -bs 100 -t 30 --dataset mnist -ni 200_000 -ef 1_000 -k 64_000 -l 6 --compile_model
# Baselines:
python experiments/main_baseline.py -bs 100 --dataset mnist -ni 200_000 -ef 1_000 -k 128 -l 3
python experiments/main_baseline.py -bs 100 --dataset mnist -ni 200_000 -ef 1_000 -k 2048 -l 7CIFAR-10
python experiments/main.py -bs 100 -t 100 --dataset cifar-10-3-thresholds -ni 200_000 -ef 1_000 -k 12_000 -l 4 --compile_model
python experiments/main.py -bs 100 -t 100 --dataset cifar-10-3-thresholds -ni 200_000 -ef 1_000 -k 128_000 -l 4 --compile_model
python experiments/main.py -bs 100 -t 100 --dataset cifar-10-31-thresholds -ni 200_000 -ef 1_000 -k 256_000 -l 5
python experiments/main.py -bs 100 -t 100 --dataset cifar-10-31-thresholds -ni 200_000 -ef 1_000 -k 512_000 -l 5
python experiments/main.py -bs 100 -t 100 --dataset cifar-10-31-thresholds -ni 200_000 -ef 1_000 -k 1_024_000 -For more information, please refer to the original project.
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the "Little White Learns Vision" WeChat public account to download the first Chinese version of the OpenCV extension module tutorial on the internet, covering more than twenty chapters including extension module installation, SFM algorithms, stereo vision, target tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the "Little White Learns Vision" WeChat public account to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, face recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the "Little White Learns Vision" WeChat public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
You are welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will be gradually subdivided in the future). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format, otherwise, you will not be approved. After adding successfully, you will be invited into the relevant WeChat group according to your research direction. Please do not send advertisements in the group, otherwise, you will be kicked out. Thank you for your understanding~