
The new generation visual generation paradigm “VAR: Visual Auto Regressive” is here! It allows GPT-style autoregressive models to surpass diffusion models in image generation for the first time, and observes Scaling Laws and Zero-shot Task Generalization similar to large language models:
Paper Title: “Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
This new work named VAR was proposed by researchers from Peking University and ByteDance, and has topped the GitHub and Paperwithcode popularity charts, gaining significant attention from peers:
Currently, the experience website, paper, code, and model have been released:
-
Experience website: https://var.vision/
-
Paper link: https://arxiv.org/abs/2404.02905
-
Open-source code: https://github.com/FoundationVision/VAR
-
Open-source model: https://huggingface.co/FoundationVision/var
Background Introduction
In natural language processing, autoregressive models like GPT and LLaMa series have achieved significant success, especially with Scaling Laws and Zero-shot Task Generalizability capabilities standing out, initially showcasing the potential towards “General Artificial Intelligence (AGI)”.
However, in the field of image generation, autoregressive models have lagged significantly behind diffusion models: recent models like DALL-E3, Stable Diffusion3, SORA belong to the diffusion family. Moreover, it remains unknown whether there exists a “Scaling Law” in the visual generation domain, meaning whether the test set loss shows a predictable power-law decrease as the model or training cost increases is still to be explored.
The powerful capabilities of GPT-style autoregressive models and Scaling Laws seem to be “locked” in the field of image generation:
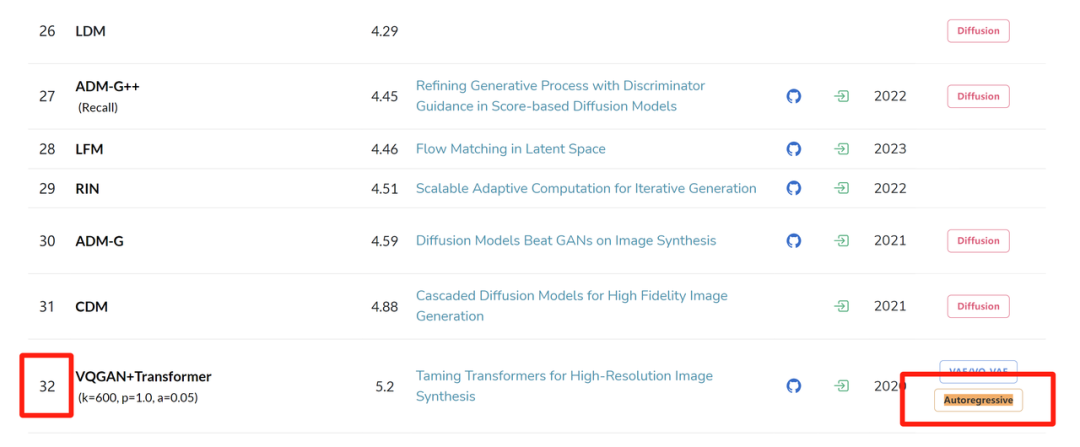
Autoregressive models lag behind many diffusion models in generation quality rankings
Targeting the “unlocking” of autoregressive model capabilities and Scaling Laws, the research team started from the intrinsic nature of the image modality, mimicking the logical sequence humans use to process images, proposing a completely new “visual autoregressive” generation paradigm: VAR, Visual AutoRegressive Modeling, which for the first time allows GPT-style autoregressive visual generation to surpass diffusion in terms of effectiveness, speed, and scaling capability, bringing Scaling Laws to the field of visual generation:

Core of VAR Method: Mimicking Human Vision, Redefining Image Autoregressive Sequence
When perceiving an image or creating a painting, humans often first overview the whole, then delve into details. This natural thought process from coarse to fine, from grasping the whole to fine-tuning the local is very intuitive:

Human perception of images (left) and the logical sequence from coarse to fine in creating artwork (right)
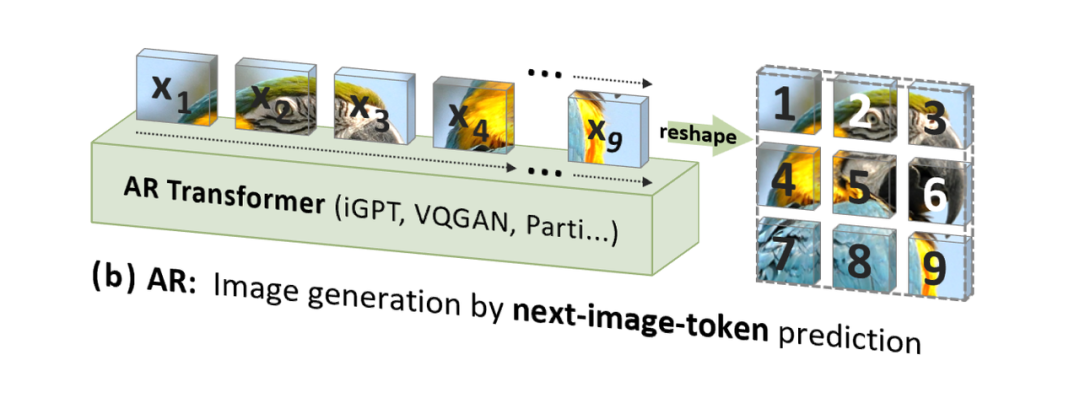
However, traditional image autoregressive (AR) models use a sequence that does not align with human intuition (but is suitable for computer processing), which is a top-down, row-by-row scanning raster order (also known as raster-scan order), to predict image tokens one by one:
VAR is “human-centered”, mimicking the logical sequence of human perception or creation of images, using a multi-scale sequence from whole to detail to gradually generate the token map:
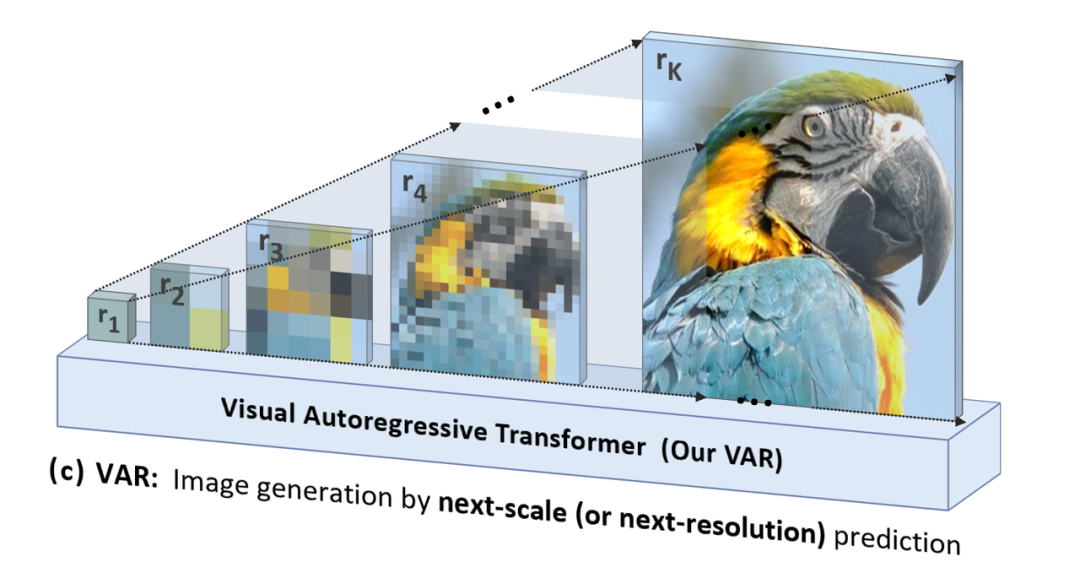
In addition to being more natural and intuitive for humans, another significant advantage brought by VAR is a substantial increase in generation speed: in each step of autoregression (within each scale), all image tokens are generated in parallel at once; across scales, it is autoregressive. This allows VAR to be dozens of times faster than traditional AR under the same model parameters and image sizes. Furthermore, experiments have shown that VAR exhibits stronger performance and scaling capability compared to AR.
VAR Method Details: Two-Stage Training
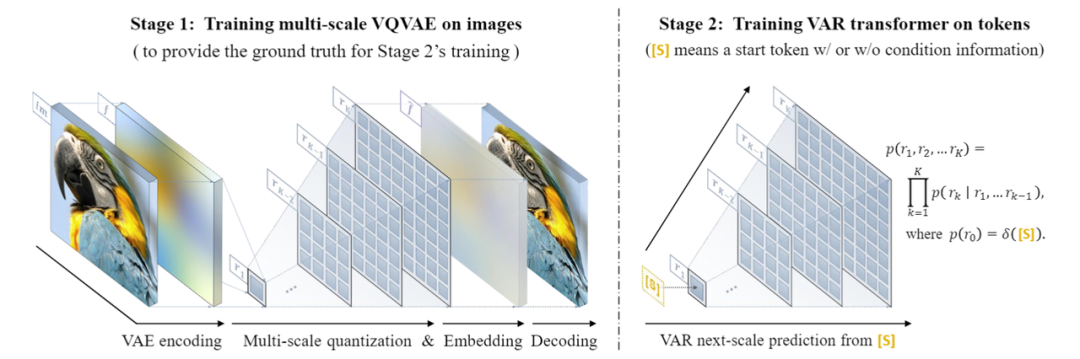
VAR trains a multi-scale quantization autoencoder (Multi-scale VQVAE) in the first stage, and a self-regressive transformer consistent with the GPT-2 structure (using AdaLN) in the second stage.
As shown in the left image, the details of the forward pass for VQVAE training are as follows:
-
Discrete Encoding: The encoder transforms the image into a discrete token map R=(r1, r2, …, rk), with resolutions from low to high
-
Continuous Encoding: r1 to rk is first converted to a continuous feature map through an embedding layer, then uniformly interpolated to the maximum resolution corresponding to rk, and summed
-
Continuous Decoding: The summed feature map is decoded to obtain the reconstructed image, and trained through a mixed loss of reconstruction + perception + adversarial three losses
As shown in the right image, after the VQVAE training is complete, the second stage of autoregressive transformer training will occur:
-
The first autoregressive step predicts the initial 1×1 token map using the starting token [S]
-
In each subsequent step, VAR predicts the next larger scale token map based on all historical token maps
-
During the training phase, VAR uses standard cross-entropy loss to supervise the probability predictions of these token maps
-
During the testing phase, the sampled token maps are processed through VQVAE for continuous encoding, interpolation summation, and decoding to obtain the final generated image
The authors state that VAR’s autoregressive framework is entirely new, while specific technical aspects draw from a series of classic techniques such as RQ-VAE’s residual VAE, StyleGAN and DiT’s AdaLN, and PGGAN’s progressive training. VAR is effectively standing on the shoulders of giants, focusing on innovation within the autoregressive algorithm itself.
Experimental Effect Comparison
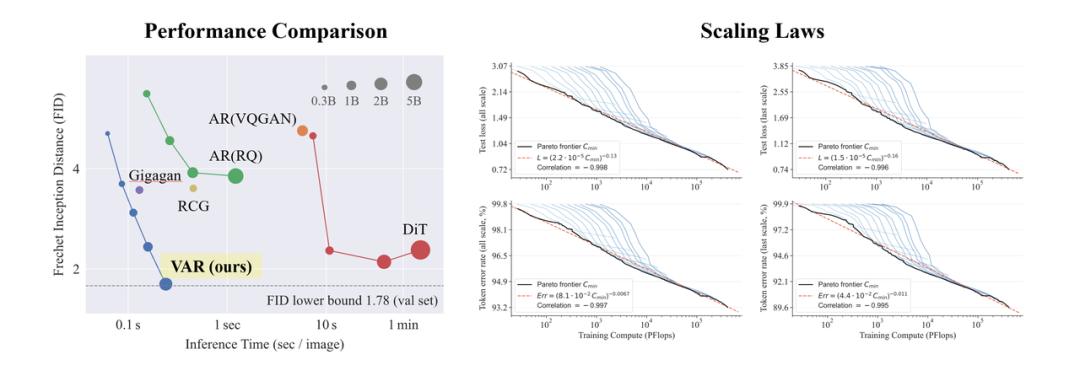
VAR was tested on Conditional ImageNet 256×256 and 512×512:
-
VAR significantly improved the performance of AR, turning the tide where AR lagged behind Diffusion
-
VAR only requires 10 steps of autoregressive steps, generating speed that greatly exceeds AR and Diffusion, even approaching the high efficiency of GAN
-
By scaling up, VAR reached SOTA levels, showcasing a completely new and promising family of generative models.

Notably, by comparing with SORA, Stable Diffusion 3’s foundational model Diffusion Transformer (DiT), VAR demonstrated:
-
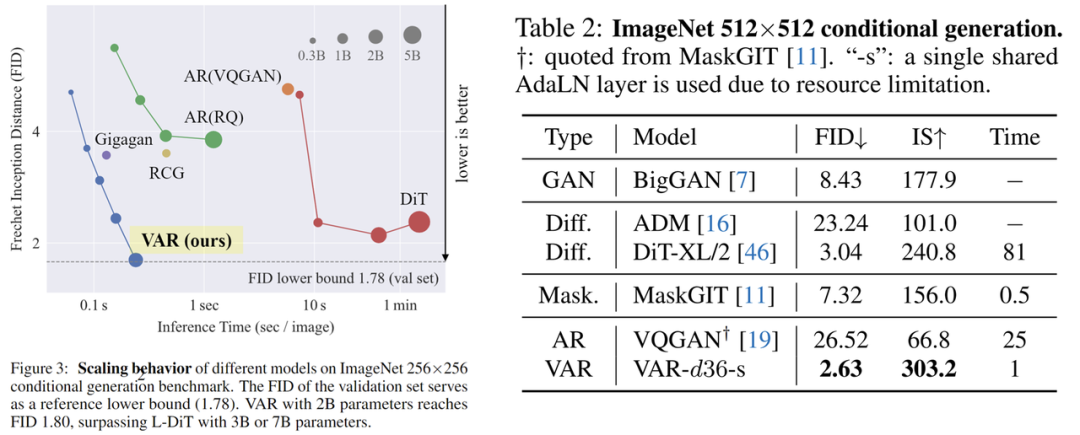
Better performance: After scaling up, VAR achieved FID=1.80, approaching the theoretical lower limit of FID 1.78 (ImageNet validation set), significantly outperforming DiT’s best of 2.10
-
Faster speed: VAR generates a 256 image in less than 0.3 seconds, which is 45 times faster than DiT; at 512, it’s 81 times faster than DiT
-
Better Scaling capability: As shown in the left image, DiT’s large model shows saturation after scaling to 3B, 7B, unable to approach the FID lower limit; while VAR, after scaling to 2 billion parameters, continuously improves performance, ultimately reaching the FID lower limit
-
More efficient data utilization: VAR only requires 350 epochs of training to exceed DiT’s 1400 epochs of training
These evidences of being more efficient, faster, and scalable than DiT bring more possibilities for the foundational architecture of the next generation of visual generation.
Scaling Law Experiment
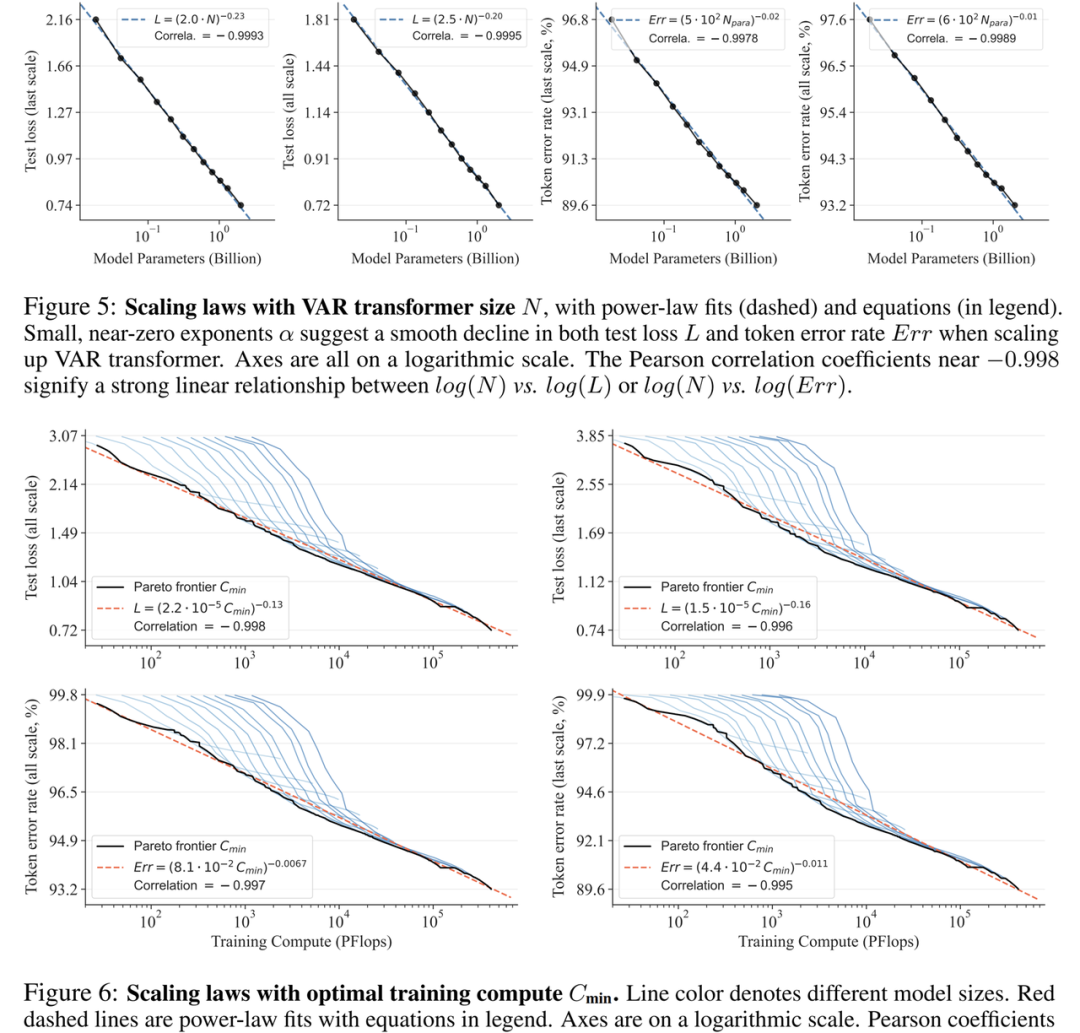
Scaling law is the “crown jewel” of large language models. Related research has confirmed that during the scaling up of autoregressive large language models, the cross-entropy loss L on the test set will predictably decrease with the model parameter count N, the number of training tokens T, and the computational cost Cmin, exhibiting a predictable decrease and showing a power-law relationship.
Scaling law not only makes it possible to predict the performance of large models based on small models, saving computational costs and resource allocation, but also reflects the strong learning capability of autoregressive AR models, where test set performance grows with N, T, and Cmin.
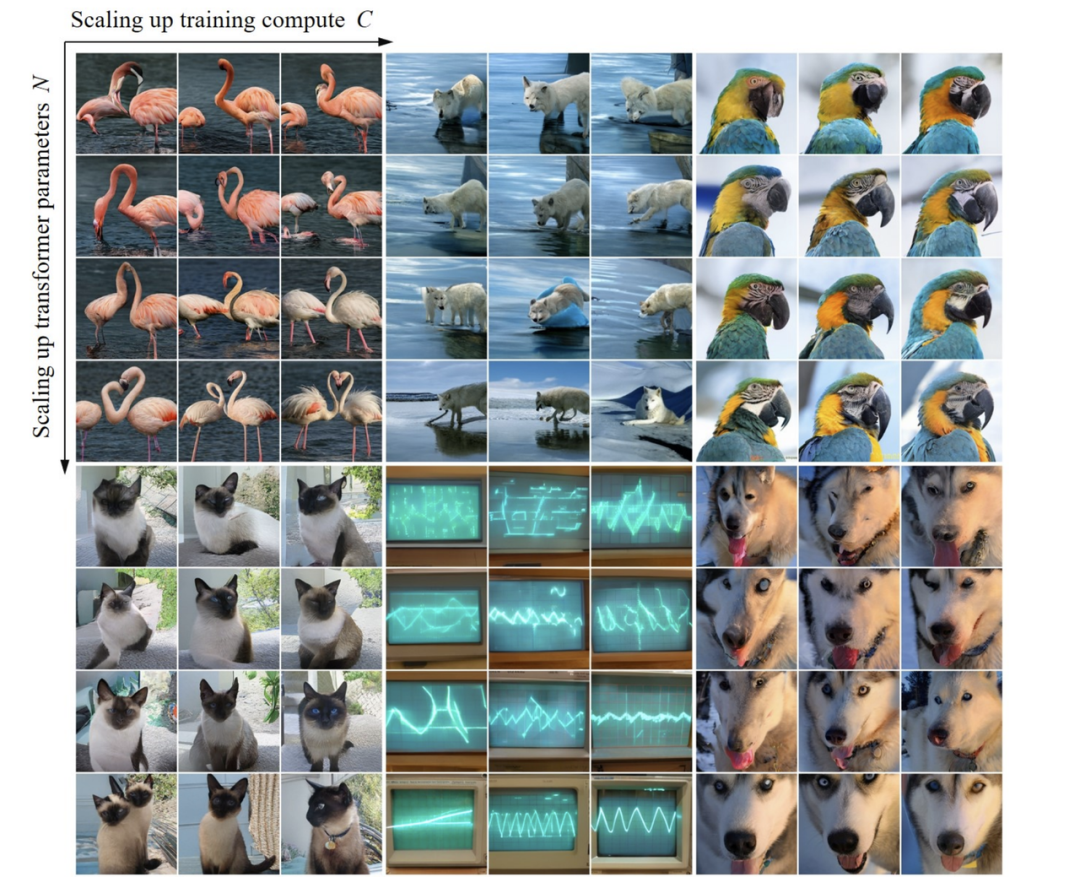
Through experiments, researchers observed that VAR exhibits a power-law scaling law almost identical to LLM: They trained models of 12 sizes, scaling model parameters from 18 million to 2 billion, with total computational loads spanning 6 orders of magnitude, and the maximum total token count reaching 305 billion, observing a smooth power-law relationship between test set loss L or test set error rate and N, and L and Cmin fitting well:
During the scale-up of model parameters and computational loads, the model’s generative capabilities can be seen to gradually improve (for example, the oscilloscope stripes below):
Zero-shot Experiment
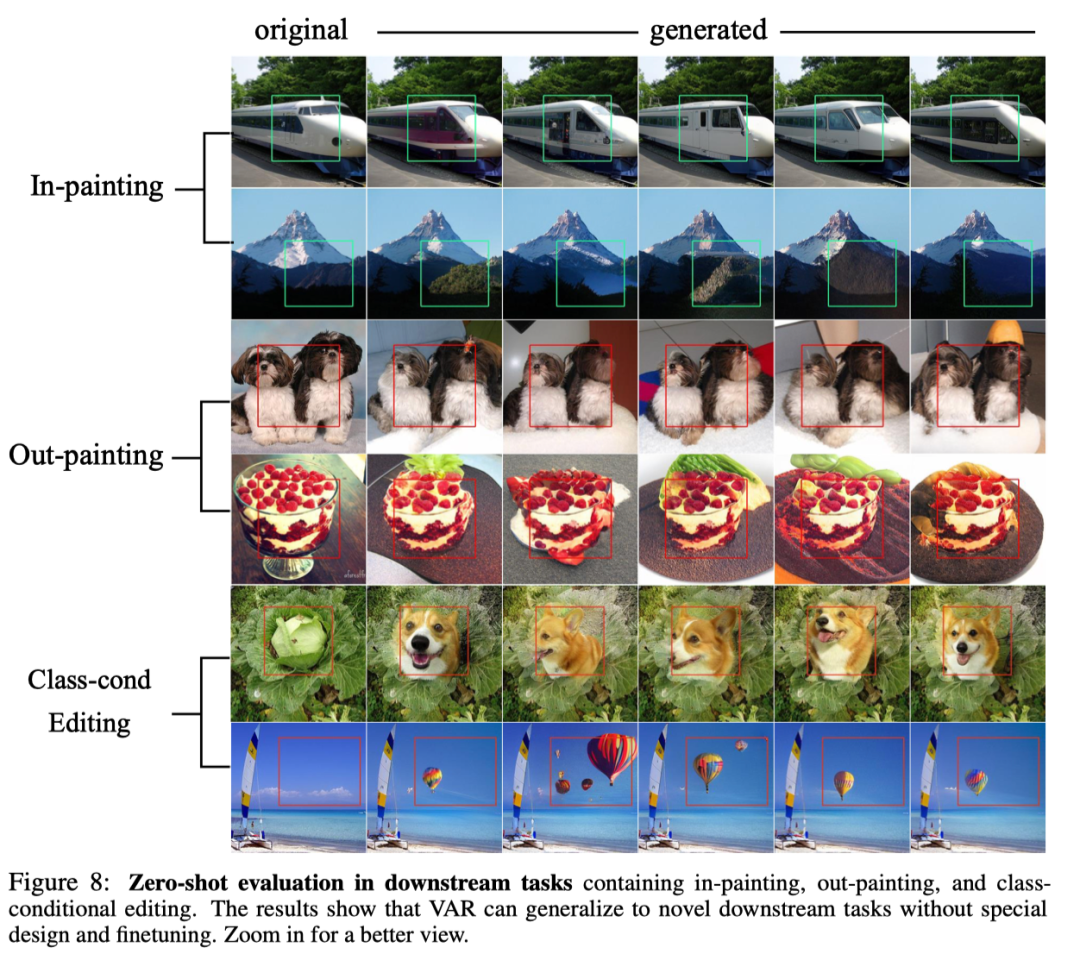
Thanks to the autoregressive model’s excellent ability to use the Teacher-forcing mechanism to force certain tokens to remain unchanged, VAR also exhibits a certain degree of zero-shot task generalization capability. The VAR Transformer, trained on conditional generation tasks, can generalize to some generative tasks without any fine-tuning, such as image inpainting, image outpainting, and class-condition editing, achieving certain results:
Conclusion
VAR provides a new perspective on how to define the autoregressive order of images, namely from coarse to fine, from global outline to local fine-tuning. While being intuitive, this autoregressive algorithm brings excellent results: VAR significantly enhances the speed and generation quality of autoregressive models, allowing autoregressive models to surpass diffusion models for the first time in multiple aspects. Meanwhile, VAR exhibits Scaling Laws and Zero-shot Generalizability similar to LLMs. The authors hope that the ideas, experimental conclusions, and open-source nature of VAR can contribute to the community in exploring the use of the autoregressive paradigm in the field of image generation and promote the development of future unified multimodal algorithms based on autoregression.
© THE END
Please contact this public account for authorization to reprint
For submissions or reporting inquiries: [email protected]