
Using RNN for Long-Term Time Series Forecasting, Is It Better Than Transformer SOTA?
This article introduced today comes from South China University of Technology, proposing an RNN-based long-term time series forecasting model that outperforms the SOTA Transformer series models.

Paper Title: SegRNN: Segment Recurrent Neural Network for Long-Term Time Series Forecasting
Download Link:https://arxiv.org/pdf/2308.11200v1.pdf
In long-term time series forecasting tasks, Transformer series models dominate, while RNN-based models have gradually faded away. The main reason is that RNNs are serially computed, and long-term forecasting requires serial iteration over many rounds, leading to high computational complexity. Moreover, as iterations proceed, information from the time series is continuously lost, affecting the final prediction. In the Decoder stage, the serial nature of RNNs can also cause error accumulation problems.
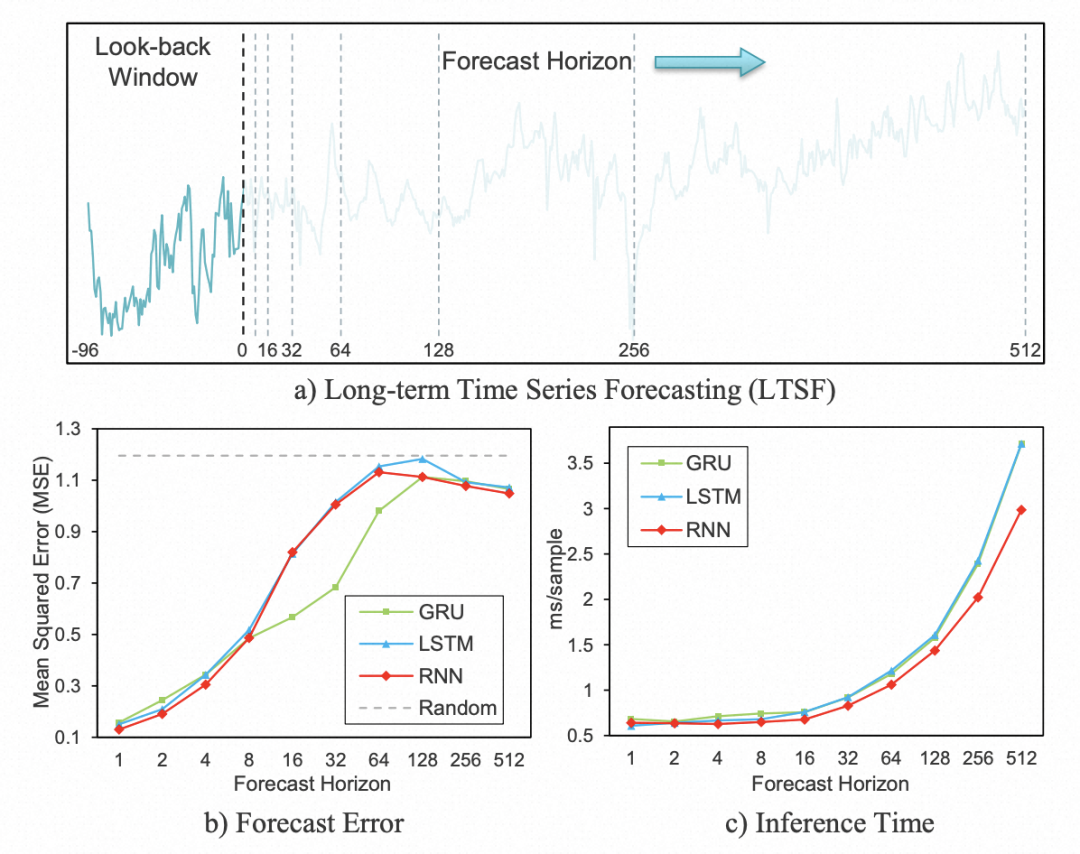
So, is it really impossible to effectively apply RNNs, which are inherently suitable for time series modeling, to long-term time series forecasting? This article proposes a simple RNN-based long-term time series forecasting model, which reduces the number of serial iterations in the Encoder stage by using slicing; in the Decoder stage, it alleviates the error accumulation problem by adopting parallel multi-step forecasting.
In traditional RNN models, iteration is computed based on each time step, which can lead to excessively long iteration paths in long-term forecasting. To alleviate this issue, this paper draws on the idea of PatchTST, proposing to slice the time series before inputting it into the RNN.
Specifically, the time series is first divided into multiple segments, each segment is encoded through a fully connected layer and activation function to generate embeddings that serve as inputs to the RNN. The specific model of the RNN uses the GRU computation method. The overall Encoder structure is shown in the left diagram below.
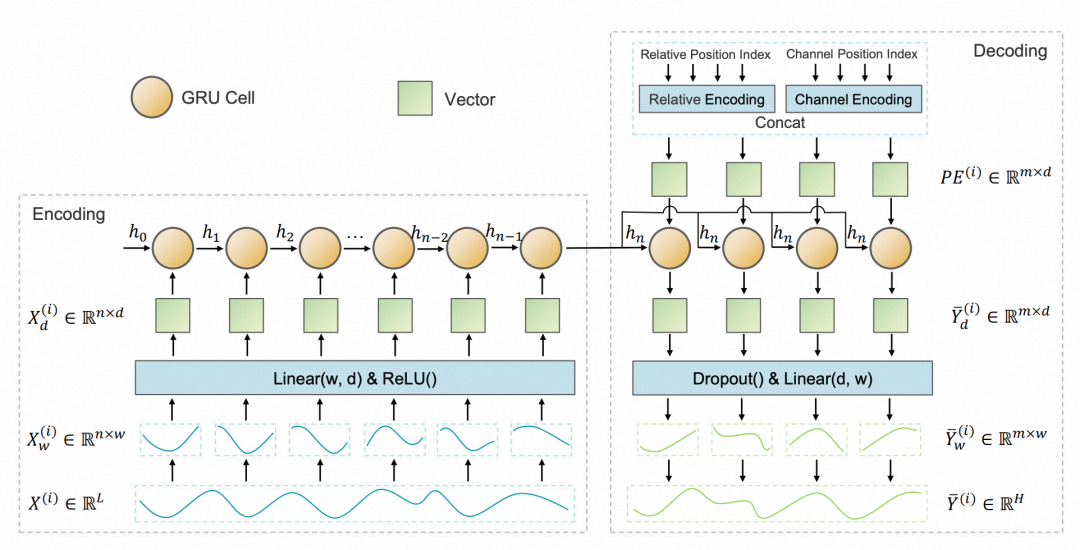
For the Decoder, the paper adopts a parallel prediction approach. In previous RNNs during the Decoder stage, the prediction result from the previous moment is often used as the input for the next moment, which leads to error accumulation and low computational efficiency. To solve this problem, the paper directly changes to a multi-step parallel prediction method, inputting the encoded results from the Encoder into multiple MLP layers to obtain predictions for multiple time steps in parallel.
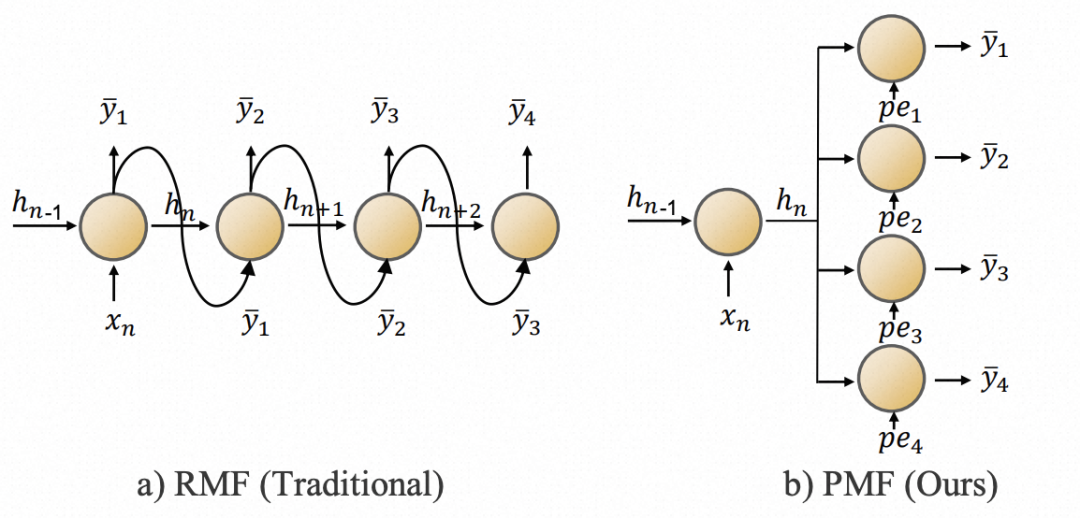
This method may cause the model to be unable to perceive the sequence order of each time step. To address this issue, the paper incorporates position embedding in the Decoder section. Additionally, due to the use of a multivariate independent modeling approach, the paper further adds channel position embedding for each sequence. These two types of position embeddings are concatenated with the encoded results from the Encoder and then passed to the MLP to obtain the prediction results.

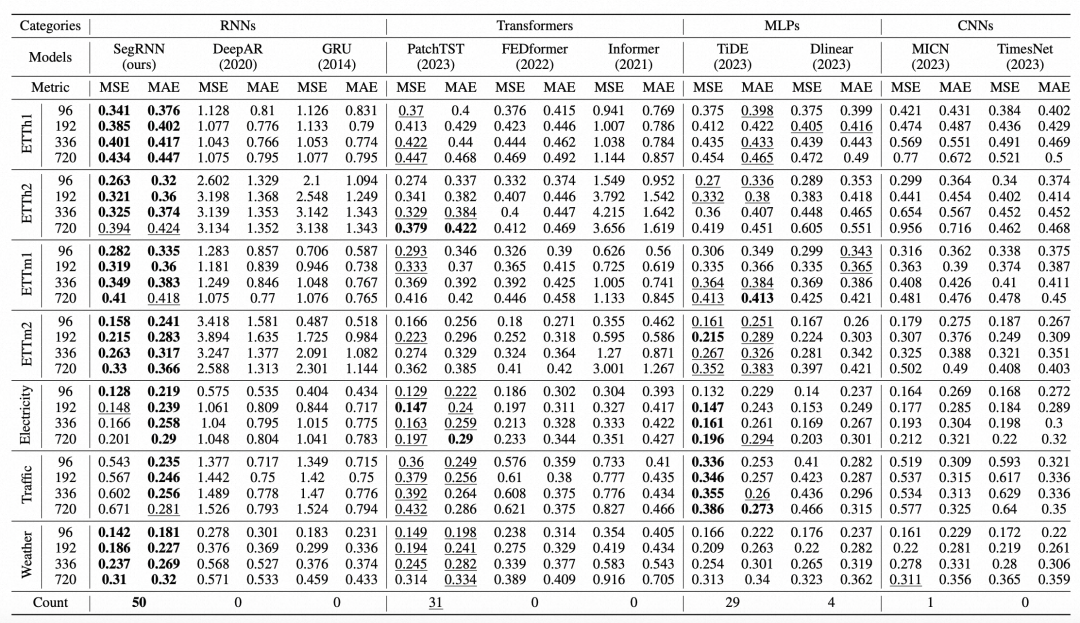
The paper compares the proposed model with the performance of four types of models: RNN-based models, Transformer-based models, CNN-based models, and Linear models. Firstly, among RNN models, the proposed method significantly outperforms methods like DeepAR and GRU. In comparison with SOTA Transformer models, it also shows considerable advantages, validating that RNNs can indeed solve long-term time series forecasting problems.

END
