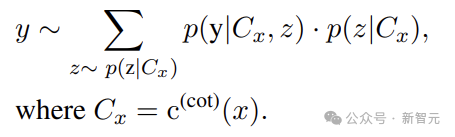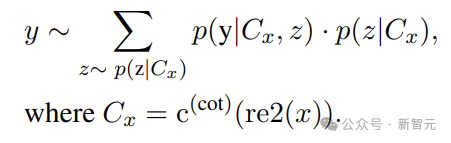MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and researchers in enterprises.
The vision of the community is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for the progress of beginners.
Reprinted from | New Intelligence
As we all know, the essence of humans is a repeater.
We follow the self-cultivation of a repeater: knock on the blackboard, highlight the key points, and say important things three times.
But, in fact, the same method works wonders for AI!
Research has shown that deliberately repeating a question—copying and pasting—significantly enhances the reasoning ability of LLMs.
Paper link: https://arxiv.org/pdf/2309.06275
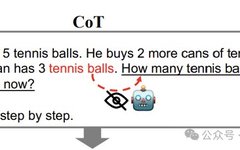
The author believes that, under normal circumstances, the key token in the question (such as ‘tennis balls’ here) cannot see the tokens that follow it (as shown above).
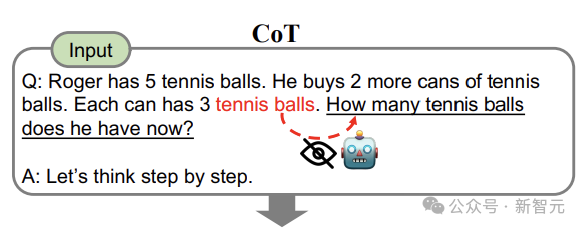
In contrast, using the re-reading (RE2) method allows ‘tennis balls’ to see the entire question it corresponds to (How many tennis balls does he have now?) in the second round, achieving a bidirectional understanding effect (as shown below).
Experiments show that in 112 experiments across 14 datasets, the RE2 technique consistently brings performance improvements, whether for instruction-tuned models (like ChatGPT) or untuned models (like Llama).
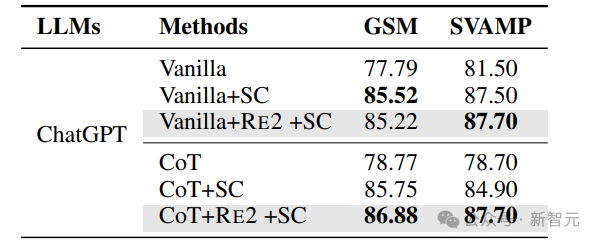
In practice, RE2 can be used independently and in conjunction with CoT (Let’s think step by step) and self-consistency (SC) methods.
The table below shows the impact of combining multiple methods on model performance. Although self-consistency aggregates multiple answers, the re-reading mechanism still helps improve in most scenarios.
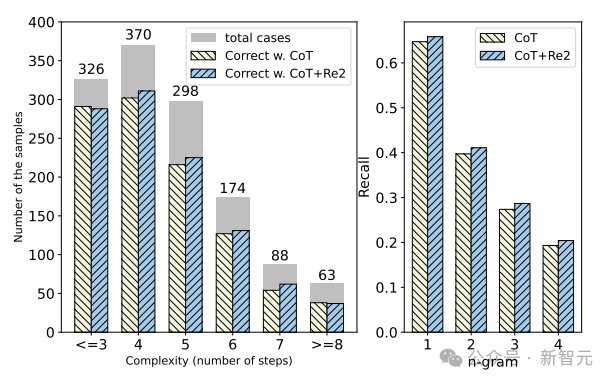
Next, we study the impact of input question complexity on the reasoning performance of CoT and RE2 prompts using the GSM8K dataset (with ChatGPT).
The complexity of the question is measured by calculating the reasoning steps present in the real explanations, and the results are shown in the figure below.
As the complexity of the question increases, the performance of all prompts generally declines, but the introduction of re-reading improves the LLM’s performance in dealing with various complex issues.
Additionally, the author also calculates the coverage between generations and input questions, proving that RE2 increases the recall rate of n-grams (n=1,2,3,4) in output explanations.
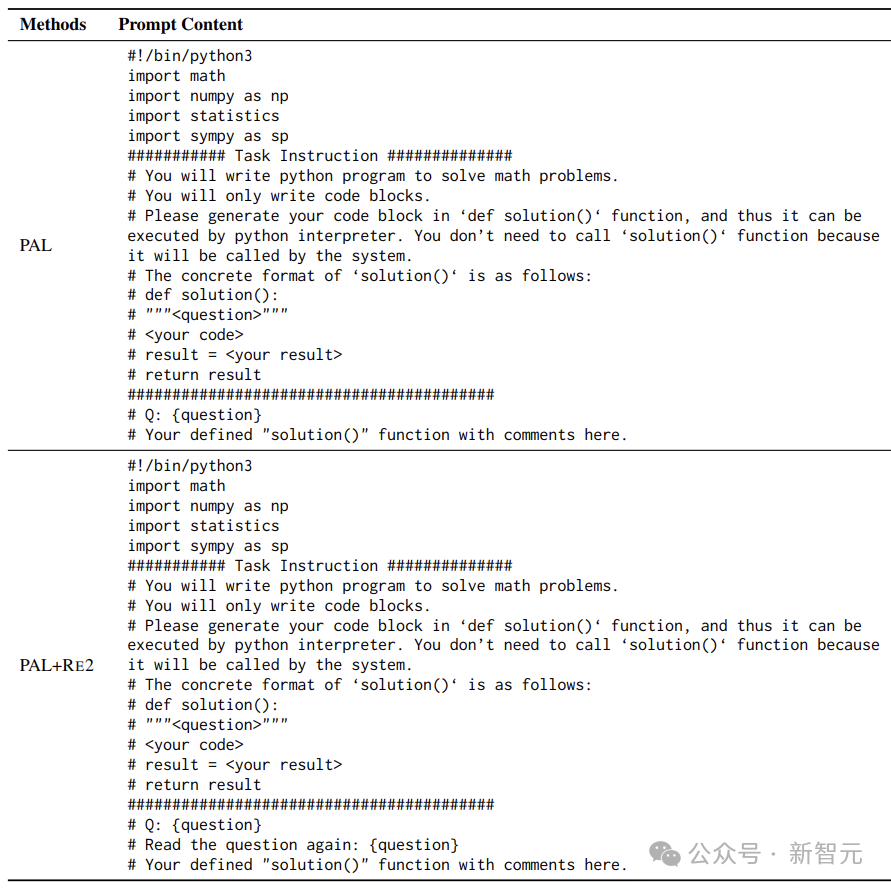
Important Things Should Be Said Twice
Existing reasoning research mainly focuses on designing diverse guiding prompts, while little attention is paid to understanding during the input phase.
In fact, understanding is the first step to solving problems and is crucial.
Most LLMs today use a unidirectional attention decoder-only architecture, which limits token visibility when encoding questions, potentially impairing global understanding of the question.
How to solve this problem? The author is inspired by human habits and attempts to have LLM re-read the input.
Unlike guiding models that reason in output with CoT, RE2 shifts the focus to input by processing the question twice, facilitating bidirectional encoding for unidirectional decoders, thus enhancing the LLM’s understanding process.
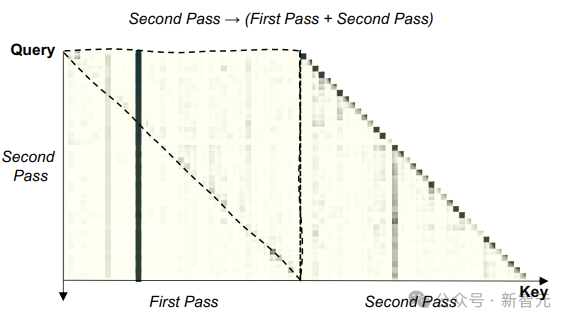
The above figure shows the attention distribution tested on the GSM8K dataset, with darker cells indicating higher attention.
The area within the dashed triangle above indicates that each token in the second round of input noticeably attends to the subsequent tokens in the first round, proving that the re-reading of LLM is expected to achieve bidirectional understanding of the question.
From another perspective, re-reading allows LLM to allocate more computational resources to input encoding, similar to increasing the depth of a neural network horizontally. Therefore, LLM with RE2 has a deeper understanding of the question.
Ordinary Reasoning
Using LLM with CoT prompts to solve reasoning tasks can be formulated as:
Where Cx represents the prompt input, derived from templates with CoT prompt instructions, and z represents the sampling principles in natural language.
Thus, LLM can decompose complex tasks into more manageable reasoning steps, treating each step as a component of the overall solution chain.
RE2 Reasoning
Inspired by human re-reading strategies, the above equation is rewritten as:
So RE2 in practical application looks like this:
Where {Input Query} is a placeholder for the input query, and the left part can contain other thought-provoking prompts.
Experiments
Due to the simplicity of RE2 and its emphasis on the input phase, it can be seamlessly integrated with various LLMs and algorithms, including few-shot, self-consistency, and various thought-provoking prompt strategies.
To validate the effectiveness and universality of RE2, researchers conducted 112 experiments across 14 datasets, covering arithmetic, common sense, and symbolic reasoning tasks.
Arithmetic Reasoning
The experiments considered the following seven arithmetic reasoning benchmarks:
The GSM8K benchmark for mathematical application problems, the SVAMP dataset with different structures of mathematical application problems, the ASDiv dataset with different mathematical application problems, the AQuA dataset for algebraic application problems, addition and subtraction math application problems for grades three to five, multi-step math problem datasets, and elementary math application problems for single operations.
The table above shows the arithmetic reasoning benchmark test results. * indicates cases where no techniques were used, but the results were better than those of CoT prompts.
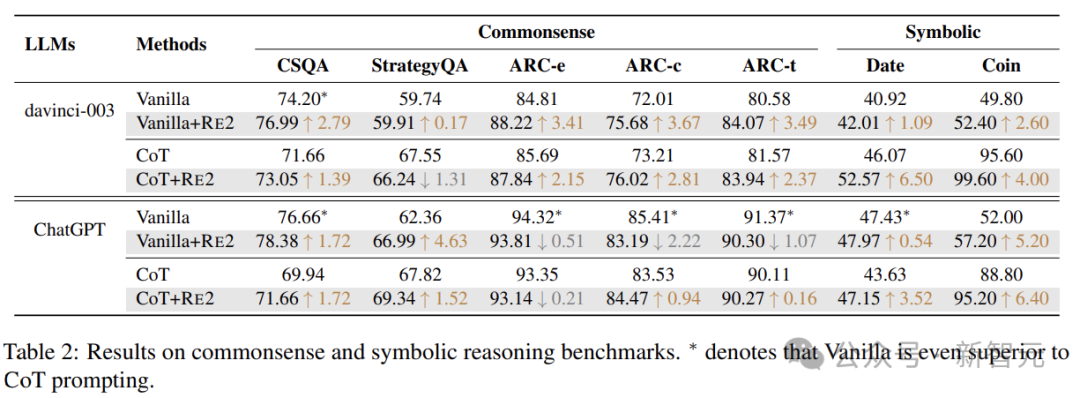
Common Sense and Symbolic Reasoning
For common sense reasoning, the experiments used the StrategyQA, ARC, and CSQA datasets.
The StrategyQA dataset includes questions that require multi-step reasoning;
The ARC dataset (ARC-t) is divided into two sets: the challenge set (ARC-c) and the simple set (ARC-e), with the former containing questions that are incorrectly answered by both retrieval and word co-occurrence algorithms;
The CSQA dataset consists of questions that require various common sense knowledge.
The experiments evaluated two symbolic reasoning tasks: date understanding and Coinflip. Date understanding is a subset of the BigBench dataset, while Coinflip is a question dataset that determines whether the coin is still heads up after the flip based on the steps given in the question.
The results indicate that, except for certain scenarios on ordinary ChatGPT, RE2 with a simple re-reading strategy consistently enhances the reasoning performance of LLMs.
RE2 demonstrates versatility across various LLMs (Text-Davinci-003, ChatGPT, LLaMA-2-13B, and LLaMA-2-70B), covering instruction fine-tuning (IFT) and non-IFT models.
The author also explored RE2’s performance in zero-shot and few-shot task settings, thought-provoking prompt methods, and self-consistency settings, highlighting its universality.
Prompting
The experiments rigorously evaluated RE2’s performance on two baseline prompting methods: Vanilla (no tricks added) and CoT (guided by a step-by-step thinking process).
For different tasks, the author designed answer format instructions in the prompts to standardize the structure of the final answers for precise extraction.
The decoding strategy for the experiments used greedy decoding with a temperature setting of 0, resulting in deterministic outputs.
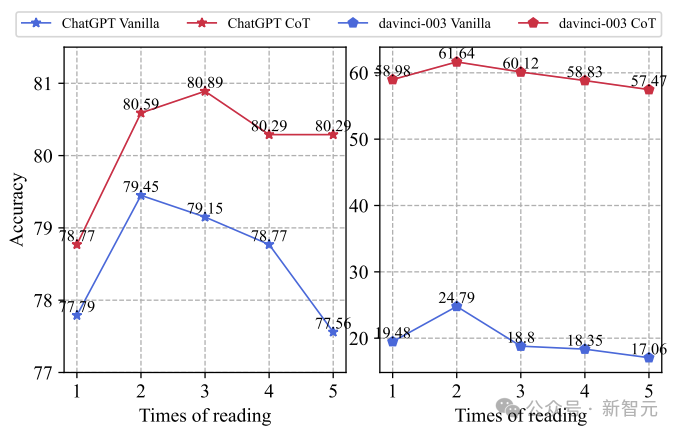
Finally, let’s explore the impact of the number of re-reads on reasoning performance:
The above figure shows how the performance of two different LLMs varies with the number of question re-reads. We find that re-reading twice improves performance, but afterward, as the number of re-reads increases, performance begins to decline.
Two possible reasons are speculated: i) excessive repetition of the question may serve as a demonstration, encouraging LLM to repeat the question rather than generate an answer, ii) repeating the question may significantly increase the inconsistency between reasoning and pre-training.
https://arxiv.org/pdf/2309.06275
Technical Group Invitation

△ Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction
(e.g., Xiao Zhang-Harbin Institute of Technology-Dialogue System)
to apply to join Natural Language Processing/Pytorch and other technical groups
About Us
MLNLP community is a grassroots academic community jointly built by machine learning and natural language processing scholars from home and abroad. It has now developed into a well-known community for machine learning and natural language processing, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing and the vast number of enthusiasts.
The community can provide an open exchange platform for relevant practitioners’ further education, employment, and research. Everyone is welcome to follow and join us.