“ With the expanding application of large language models (LLMs), Retrieval-Augmented Generation (RAG) has become a mature technology. The popularity of products like txt2sql and ChatBI highlights the increasing importance of query construction techniques. This article analyzes the process of query construction and illustrates, through examples, how to transform natural language questions into structured queries to enhance the accuracy and efficiency of information retrieval. This article aims to popularize relevant knowledge, and if you wish to implement similar products, I hope it can help you.”
What is Query Construction?
Imagine you ask a question like “Find movies about aliens released in 1980.” Query construction is about turning our plain language into a format that the database can understand. Why is it important? Because it serves as a bridge between humans and machines, allowing the database system to receive clear, executable instructions that match the user’s intent. Even the most advanced retrieval systems cannot find relevant results without good query construction.
Three Types of Data
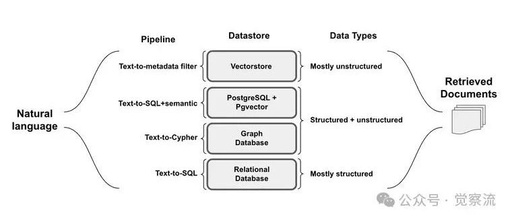
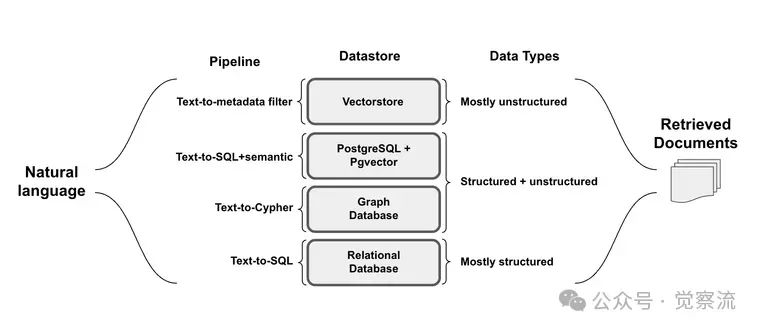
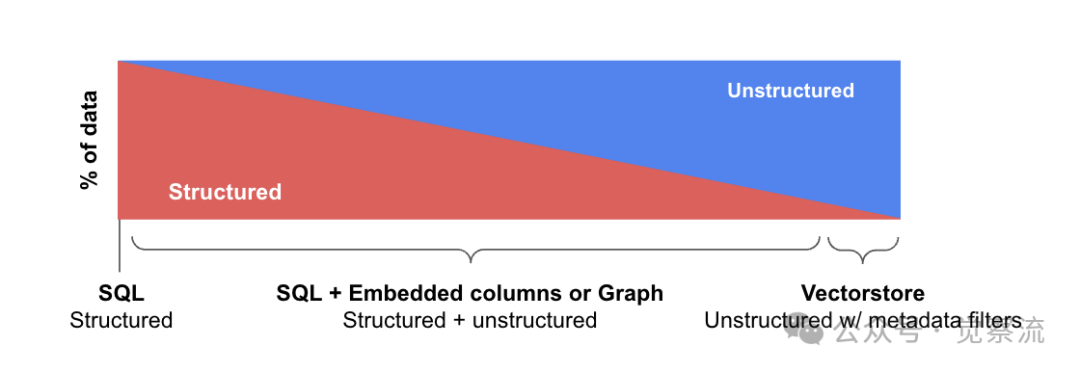
Structured Data: This type of data is organized in SQL and graph databases, like neatly arranged in tables or relationships, with information in fixed positions. For example, in a movie database, titles, release dates, and ratings are stored in separate columns, making filtering and sorting very precise.Semi-Structured Data: This type has both organized parts and free-form content, like JSON or XML files. Document databases are typical examples, where each entry has structured metadata, such as author and date, along with unstructured body content.Unstructured Data: Vector databases primarily handle this type of data, relying on semantic indexing and metadata filtering for retrieval. These systems excel at finding similar content, such as text documents and articles, where meaning is more important than exact matches.
Methods for Constructing Queries
The methods can vary based on the target database type and data structure.
1. Text to SQL
This involves transforming natural language questions into SQL queries for interacting with structured databases. Key steps include:Understanding the Database Schema: The system must first analyze the database structure, including tables, columns, and relationships, to understand data fields and their connections, enabling the generation of valid SQL syntax.
Query Construction Steps: Extract key entities and conditions from natural language input, map these elements to the corresponding database fields, then construct appropriate WHERE clauses and JOIN operations, finally validating the query syntax before execution.For example, “Find action movies released after 2020 with a rating above 8” can be transformed into the following SQL query:
SELECT title, release_year, rating
FROM movies
WHERE genre = 'action'
AND release_year > 2020
AND rating > 8;
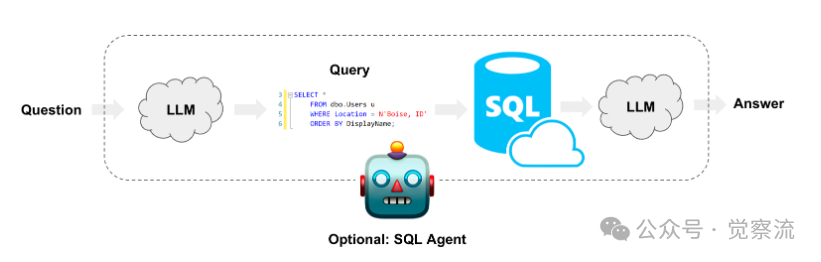
2. Metadata-Based Filtering
This method retrieves information from vector databases by combining semantic search with structured filtering. Key steps include:Query Components: Separating semantic search terms from filtering conditions, creating structured filters based on available metadata fields, and then combining both parts for precise document retrieval.Implementation Method: Analyzing filtering conditions in natural language input, constructing metadata filters using comparison operators, and then using them alongside semantic similarity searches.For example, “Find technical articles about machine learning published this year” would generate semantic search parameters for “machine learning” and metadata filters for the publication date.
3. Text to Cypher
This is a method for constructing queries for graph databases, focusing on relationship-based data structures. The main processes include:Graph Pattern Matching: Identifying entities and their relationships in natural language, mapping them to nodes and edges in the graph, and then constructing path-based queries using Cypher syntax.Query Construction Process: Analyzing relationship requirements in user queries, determining suitable graph traversal patterns, and constructing Cypher queries that capture complex relationships.For example, “Find all collaborators who worked on sci-fi movies with Christopher Nolan” can be transformed into a Cypher query that traverses the director-movie-genre relationship.
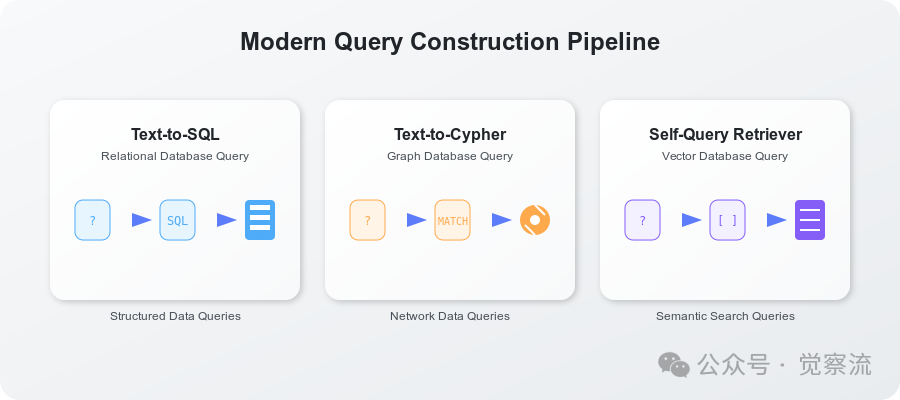
These methods work collaboratively in modern systems, often combining various technologies to achieve data retrieval across different storage types.
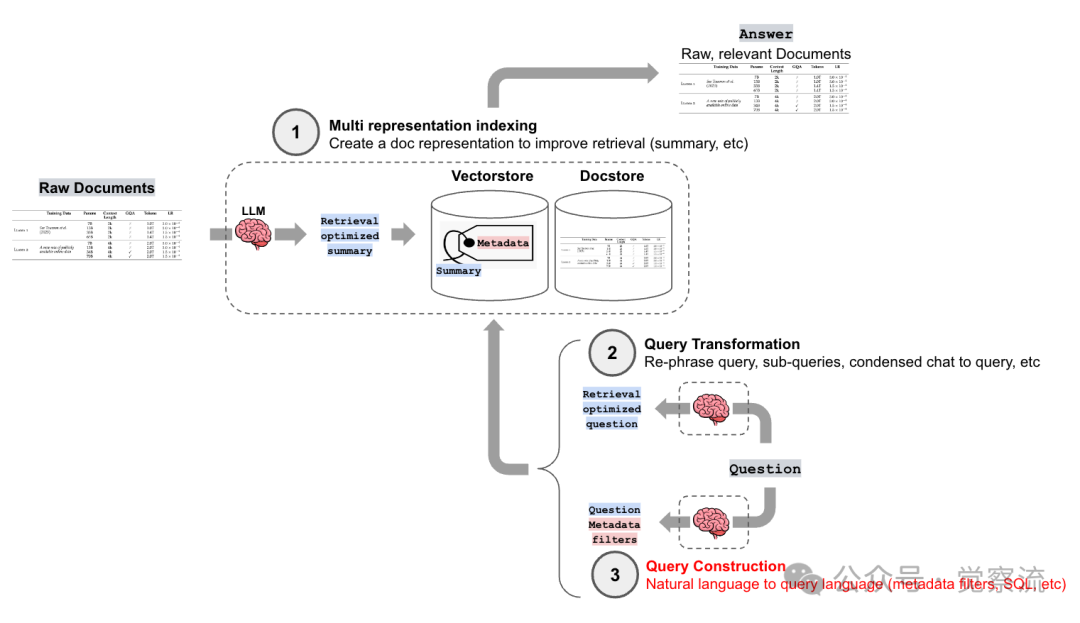
Implementing Query Construction in RAG
Build a RAG system with movie search functionality. This system can understand natural language queries about movies and translate them into structured SQL queries to retrieve relevant information from a PostgreSQL database. The system is specifically designed to handle queries about movie genres, release years, and ratings, with built-in pagination and sorting support.
Step 1: Set Up Project Structure
First, create a clear project structure with configuration files, main RAG implementation files, and test files separated.
movie_search/
├── config.py
├── movie_rag.py
└── test_queries.pyStep 2: Install Dependencies
Install necessary packages, including langchain for RAG processes, psycopg2 for PostgreSQL interaction, SQLAlchemy for database operations, and sentence-transformers for handling embeddings. These form the core framework of our RAG system.
# Install dependencies
pip install langchain langchain-community psycopg2-binary sqlalchemy sentence-transformersStep 3: Create Configuration (config.py)
Implement a DatabaseConfig class to manage database connection details. This separates configuration from core logic, making it easier to change database parameters.
class DatabaseConfig:
HOST = "localhost"
PORT = 5432
DATABASE = "movies_db"
USER = "your_username"
PASSWORD = "your_password"
@property
def connection_string(self):
return f"postgresql://{self.USER}:{self.PASSWORD}@{self.HOST}:{self.PORT}/{self.DATABASE}"Step 4: Implement RAG Process (movie_rag.py)
The MovieRAGPipeline class contains three main parts:parse_query(): Breaks down natural language queries into structured components (genre, year, limit, sort criteria).build_query(): Constructs SQL queries from the parsed components.process_query(): Coordinates the entire process from parsing to executing the query.
from typing import Dict
from langchain.sql_database import SQLDatabase
from langchain_community.embeddings import HuggingFaceEmbeddings
import re
class MovieRAGPipeline:
def __init__(self, connection_string: str):
self.db = SQLDatabase.from_uri(connection_string)
self.embeddings = HuggingFaceEmbeddings()
def parse_query(self, query: str) -> Dict:
components = {
"genre": None,
"year": None,
"limit": 5,
"sort_by": None
}
query = query.lower()
genres = ["comedy", "action", "drama", "sci-fi"]
for genre in genres:
if genre in query:
components["genre"] = genre
break
year_match = re.search(r'\b\d{4}\b', query)
if year_match:
components["year"] = int(year_match.group())
limit_match = re.search(r'top (\d+)', query)
if limit_match:
components["limit"] = int(limit_match.group(1))
return components
def build_query(self, components: Dict) -> str:
conditions = []
if components["genre"]:
conditions.append(f"genre = '{components['genre']}'")
if components["year"]:
conditions.append(f"year = {components['year']}")
where_clause = " AND ".join(conditions) if conditions else "TRUE"
return f"""
SELECT title, genre, year, rating
FROM movies
WHERE {where_clause}
ORDER BY rating DESC
LIMIT {components['limit']}
"""
def process_query(self, query: str) -> Dict:
try:
components = self.parse_query(query)
sql_query = self.build_query(components)
results = self.db.run(sql_query)
return {
'status': 'success',
'components': components,
'sql_query': sql_query,
'results': results
}
except Exception as e:
return {
'status': 'error',
'message': str(e)
}Step 5: Create Test Script (test_queries.py)
Create a comprehensive test script to validate the functionality of the process with various query patterns. This ensures the system can reliably handle different types of natural language input.
from config import DatabaseConfig
from movie_rag import MovieRAGPipeline
def test_pipeline():
config = DatabaseConfig()
pipeline = MovieRAGPipeline(config.connection_string)
test_queries = [
"List top 5 comedy movies from 2022",
"Show me comedy films released in 2022",
"What are the highest rated comedy movies from 2022",
]
for query in test_queries:
print(f"\nProcessing Query: {query}")
print("-" * 50)
result = pipeline.process_query(query)
if result['status'] == 'success':
print("\nExtracted Components:")
for key, value in result['components'].items():
print(f"{key}: {value}")
print("\nGenerated SQL Query:")
print(result['sql_query'])
print("\nResults:")
print(result['results'])
else:
print("Error:", result['message'])
print("\n" + "="*70 + "\n")
if __name__ == "__main__":
test_pipeline()Step 6: Create Database
The implementation also includes creating a PostgreSQL database with a movies table that has basic fields like title, genre, year, and rating, along with an embedding vector column. Sample data is also provided for testing functionality.1. Create Database and Table:
CREATE DATABASE movies_db;
CREATE TABLE movies (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
genre TEXT,
year INTEGER,
rating FLOAT,
embeddings vector(384)
);2. Insert Sample Data:
INSERT INTO movies (title, genre, year, rating) VALUES
('The Menu', 'comedy', 2022, 8.5),
('Glass Onion', 'comedy', 2022, 8.2),
('Everything Everywhere', 'comedy', 2022, 8.9);Step 7: Run Tests
The final step is to run the test script to verify that the entire process works as expected, demonstrating how natural language queries are transformed into SQL queries and executed.<span>python test_queries.py</span> Output:

Challenges of Query Construction
Query construction faces several challenges in database operations and information retrieval. Key challenges include:
-
• LLM Hallucination Problem: Models may generate fictitious elements when constructing queries, such as inventing non-existent tables and invalid relationships. This necessitates implementing strict validation processes using database metadata to ensure accuracy. -
• User Error Management: The system must handle user input errors, such as misspellings, inconsistent formats, and ambiguous terms. This requires robust error-handling mechanisms to ensure accurate interpretation of queries through fuzzy matching algorithms and clarification prompts. -
• Complex Query Handling: Managing multi-condition queries requires skillful handling of multiple WHERE clauses and JOIN operations while coordinating queries across different data stores, ensuring proper transaction management and consistency maintenance.
Advantages of Query Construction
Query construction offers numerous benefits that enhance data retrieval and system functionality. The main advantages include:
-
• Improved Accuracy: By generating structured queries, effective pattern matching, and preserving context, query construction significantly enhances retrieval precision, leading to more relevant results. -
• Enhanced Flexibility: This approach can flexibly switch between various database types and query languages, supporting hybrid search methods that combine exact matching and semantic matching for comprehensive data retrieval. -
• Efficient Data Access: Query construction optimizes resource utilization by reducing query execution time, better utilizing caches, and efficiently using memory, while also minimizing network bandwidth consumption and optimizing storage access patterns. -
• Understanding User Intent: The system retains semantic meaning during the transformation process, preserving user intent in structured formats and effectively handling complex relational queries. -
• Scalable Solutions: Query construction systems can effectively grow with organizational needs, handling increasing data volumes and supporting a growing user base, while easily integrating into existing systems and being compatible with modern cloud architectures.
Conclusion
In today’s data-driven world, query construction is vital for RAG systems. It builds a bridge between human communication and complex database operations, enabling these systems to provide accurate and relevant results. The importance of query construction in data retrieval, user interaction, and data relationship management is evident, as these features help RAG systems deliver relevant results while maintaining error handling and optimization.
Reference: https://blog.langchain.dev/query-construction
Welcome to like, to view, to follow. Follow for more exciting content
I am Si0Qi🐝, an internet practitioner passionate about AI. Here, I share my observations, thoughts, and insights. I hope that through my self-exploration process, I can inspire those who love AI, technology, and life, bringing you inspiration and deep reflection.
Looking forward to our unexpected encounter. Click 👇🏻 to follow