
RAG (Retrieval-Augmented Generation) is a technical architecture that combines information retrieval and generation models. Its basic working principle is to enhance the output of the generation model through the retrieval of relevant information, thereby improving the accuracy and relevance of the generated content.
Working Principle:
-
Information Retrieval:
-
When a user inputs a query, the system first finds documents or information related to the query from the knowledge base through the retrieval module (such as a vector database). This step usually employs vectorization techniques to convert text into vector representations for similarity search.
Generation Model:
-
The retrieved information is input into the generation model along with the user’s query, and the generation model generates the final answer or content based on this information. The generation model typically uses large pre-trained models (such as GPT, BERT, etc.) that can understand context and generate natural language text.
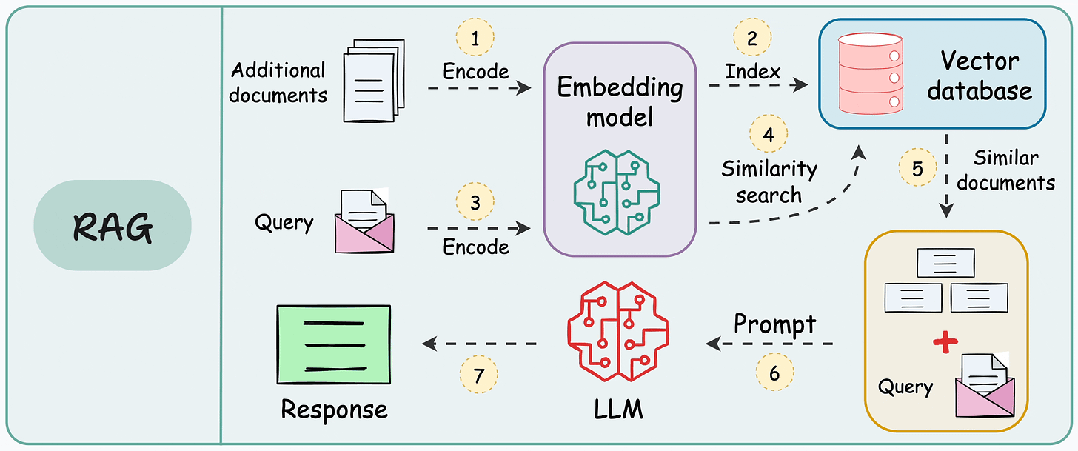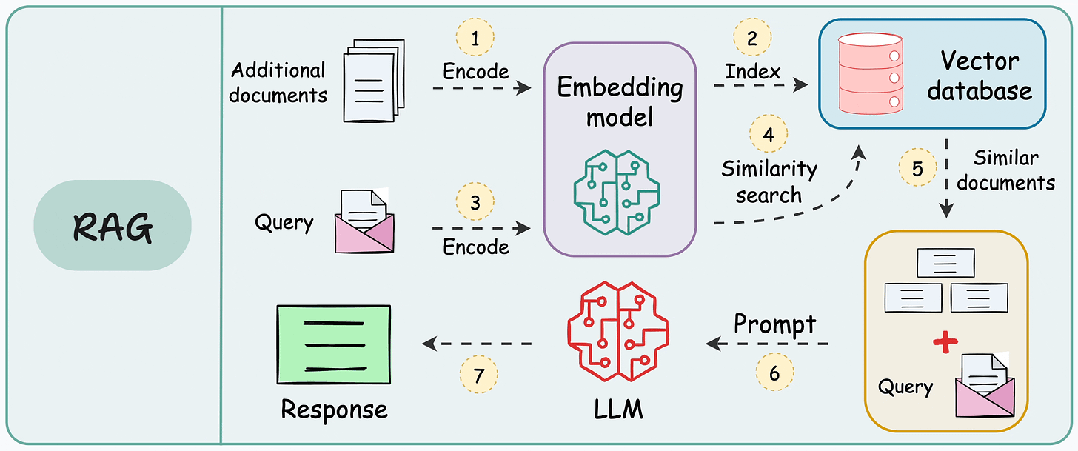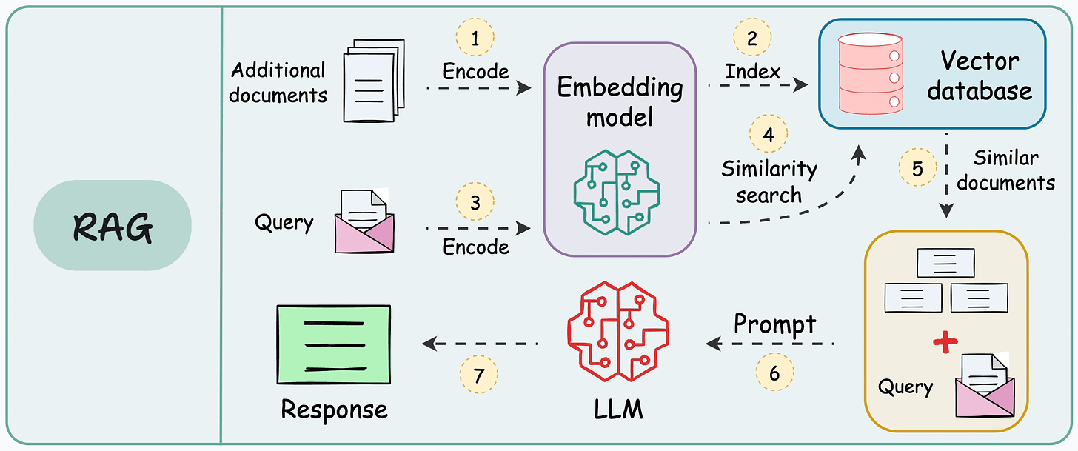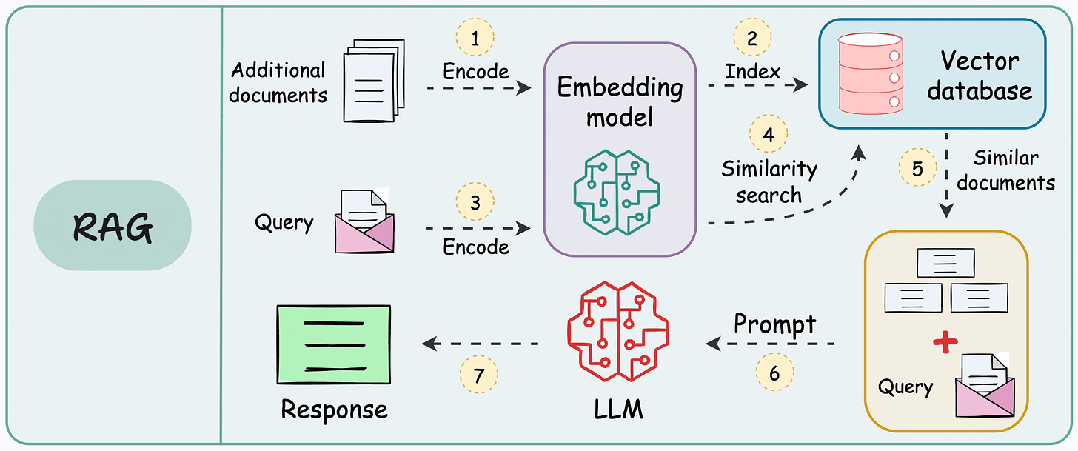
Technical Architecture:
-
LlamaIndex:
-
As a powerful tool, LlamaIndex helps build enterprise-level private knowledge bases, supporting efficient information retrieval and management. It provides a flexible API that allows users to quickly build and query the knowledge base. Generation model
Generation Model:
-
Typically uses large pre-trained models (such as GPT, BERT, etc.) for text generation, which are trained on large-scale datasets and possess good language understanding and generation capabilities. Vector database
Vector Database:
-
An efficient data structure for storing and retrieving documents, supporting fast similarity searches. Common vector databases include FAISS, Pinecone, and Weaviate.
Project Implementation and Model Optimization:
Personal AI Supercomputing:
20 Billion Parameter Model:
-
With the improvement of computing power, individuals or small enterprises can also use large-scale pre-trained models for AI application development. For example, a startup uses a 20 billion parameter model to provide users with personalized content recommendation services.
-
7B Private Model:Through privatization deployment, enterprises can use smaller models (such as 7B parameter models) in local environments to meet specific business needs. For instance, a healthcare institution utilizes a 7B model for patient data analysis and health recommendation generation.
2. Current Defects of Large Models
Common issues with current models:
-
Insufficient Accuracy: Although there are rich pre-trained models available, these models are often trained on publicly available internet data, which may not meet the needs for privatized enterprise content.
-
Limitations of Pre-trained Models: Pre-trained models, while possessing some knowledge, still lack specificity and depth in certain fields. For example, an educational institution found that general models performed poorly when handling specialized subject content.
-
Hallucination Phenomenon: Generation models sometimes produce inaccurate or false information, mainly due to insufficient precision and lack of knowledge in specific fields, leading to decreased accuracy in generated content. For example, a customer service system generated incorrect information when answering complex questions.
3. Solutions Consideration
-
RAG: By integrating a private knowledge base, the model’s generation capability is enhanced. This allows for the use of external knowledge to improve the quality of generated content without altering the base model. For instance, a company combined its internal knowledge base with the generation model using RAG technology, significantly improving the accuracy of customer support.
-
Fine-tuning: Fine-tuning the base model (LoRA (Low-Rank Adaptation)) can adapt and optimize the model for specific fields or industries, generating a new model (such as vertical models, specialized models, industry models). For example, a healthcare institution fine-tuned the base model using LoRA to improve its performance in the medical field.
4. Current International Applications
RAG technology has been widely applied internationally, especially in enterprise knowledge management, online Q&A systems, and intelligence retrieval systems. Here are some specific international application statuses:
-
Enterprise Knowledge Management Systems:
-
Intelligent Knowledge Retrieval and Sharing: Through RAG technology, enterprises can quickly retrieve and share information from their internal knowledge bases, improving the efficiency of knowledge management.
-
Intelligent Q&A and Problem Solving: RAG technology can be used to build intelligent Q&A systems that help employees quickly resolve work-related issues.
-
Knowledge Graph Construction and Intelligent Recommendation: RAG technology can combine with knowledge graphs to provide smarter knowledge recommendation services. Online Q&A systems
Online Q&A Systems:
-
Automatic Q&A and Customer Service: RAG technology can be used to build automatic Q&A systems, improving the efficiency and quality of customer service. Internal knowledge sharing and collaboration: Enterprises can use RAG technology to promote knowledge sharing and team collaboration. Education and Learning Support: RAG technology can be used in the education field to provide personalized learning support services. Intelligence Retrieval Systems
Intelligence Retrieval Systems:
-
Rapid Information Retrieval and Analysis: RAG technology can be used in intelligence retrieval systems to quickly retrieve and analyze large amounts of information.
-
Integration and Utilization of Diverse Information Resources: RAG technology can integrate various information resources to provide more comprehensive intelligence analysis.
-
Intelligence Analysis and Decision Support: RAG technology can provide decision support for intelligence analysis, helping enterprises and institutions make more informed decisions.
5. Predictions for 2025 Practices
According to the latest research and market trends, RAG technology will have several important development directions and practices in 2025:
-
Technical Optimization and Performance Improvement:
-
Improving Retrieval Efficiency: Develop more advanced retrieval algorithms and technologies, such as optimizing index structures and adopting more efficient similarity calculation methods to accelerate retrieval speed and reduce latency.
-
Expanding Context Length: Explore how to break through the context window limitations of large language models, enabling RAG systems to handle longer text sequences or more relevant information.
-
Enhancing Robustness: Improve the system’s ability to handle noisy data, contradictory information, and outdated or inaccurate data.
The above content is enhanced through AI retrieval and is for learning and communication purposes only.