
As 2021 is about to end, looking back at the recent autumn recruitment for algorithm positions, it can be described as going from ashes to hell on earth. The trend has shifted: those considering a career change are starting to change careers, and those switching majors are starting to switch majors.

In response to this friend’s question, I would like to answer from two aspects.
Most students who wish to work in NLP-related fields often learn through self-study. However, the obvious issue is:
-
I know how to do it. -
I have done it.
To truly cultivate NLP talents comprehensively and systematically, the Greedy Academy has launched the “Natural Language Processing Lifelong Upgraded Version” course, covering all necessary technologies from classic machine learning, text processing techniques, sequence models, deep learning, pre-trained models, knowledge graphs, to graph neural networks. It includes practical industrial-level projects, with experienced NLP leaders providing live explanations to help you master the concepts and easily secure offers.
Helping You Become theTOP 10% of Engineers
Students interested in the course
Scan the QR code for consultation

Chapter 1: Overview of Natural Language Processing
-
Current Status and Prospects of Natural Language Processing
-
Applications of Natural Language Processing
-
Classic Tasks of Natural Language Processing
-
Time Complexity, Space Complexity
-
Dynamic Programming
-
Greedy Algorithm
-
Various Sorting Algorithms
-
Logistic Regression
-
Maximum Likelihood Estimation
-
Optimization and Gradient Descent
-
Stochastic Gradient Descent
-
Understanding Overfitting and Preventing Overfitting
-
L1 and L2 Regularization
-
Cross-Validation
-
Regularization and MAP Estimation
-
Various Tokenization Algorithms
-
Word Normalization
-
Spelling Correction, Stop Words
-
One-Hot Encoding Representation
-
TF-IDF and Similarity
-
Distributed Representation and Word Vectors
-
Word Vector Visualization and Evaluation
-
Advantages and Disadvantages of One-Hot Encoding
-
Advantages of Distributed Representation
-
Static and Dynamic Word Vectors
-
SkipGram and CBOW
-
Detailed Explanation of SkipGram
-
Negative Sampling
-
Role of Language Models
-
Markov Assumption
-
UniGram, BiGram, NGram Models
-
Evaluation of Language Models
-
Smoothing Techniques for Language Models
-
Applications of HMM
-
HMM Inference
-
Viterbi Algorithm
-
Forward and Backward Algorithms
-
Detailed Explanation of HMM Parameter Estimation
-
Directed and Undirected Graphs
-
Generative and Discriminative Models
-
From HMM and MEMM
-
Label Bias in MEMM
-
Introduction to Log-Linear Models
-
From Log-Linear to LinearCRF
-
Parameter Estimation of LinearCRF
-
Understanding Neural Networks
-
Various Common Activation Functions
-
Backpropagation Algorithm
-
Comparison of Shallow and Deep Models
-
Hierarchical Representation in Deep Learning
-
Overfitting in Deep Learning
-
From HMM to RNN Models
-
Gradient Issues in RNN
-
Gradient Vanishing and LSTM
-
LSTM to GRU
-
Bidirectional LSTM
-
Bidirectional Deep LSTM
-
Seq2Seq Models
-
Greedy Decoding
-
Beam Search
-
Problems with Long Dependencies
-
Implementation of Attention Mechanism
-
Contextual Word Vector Technology
-
Hierarchical Representation in Image Recognition
-
Hierarchical Representation in Text Domains
-
ELMo Model
-
Pre-training and Testing of ELMo
-
Advantages and Disadvantages of ELMo
-
Disadvantages of LSTM Models
-
Overview of Transformer
-
Understanding Self-Attention Mechanism
-
Encoding Positional Information
-
Understanding the Difference between Encoder and Decoder
-
Understanding Training and Prediction of Transformer
-
Disadvantages of Transformer
-
Introduction to Autoencoders
-
Transformer Encoder
-
Masked Language Model
-
BERT Model
-
Different Training Methods for BERT
-
ALBERT
-
RoBERTa Model
-
SpanBERT Model
-
FinBERT Model
-
Incorporating Prior Knowledge
-
K-BERT
-
KG-BERT
-
Review of Transformer Encoder
-
GPT-1, GPT-2, GPT-3
-
Disadvantages of ELMo
-
Considering Context under Language Models
-
Permutation LM
-
Dual-Stream Self-Attention Mechanism
-
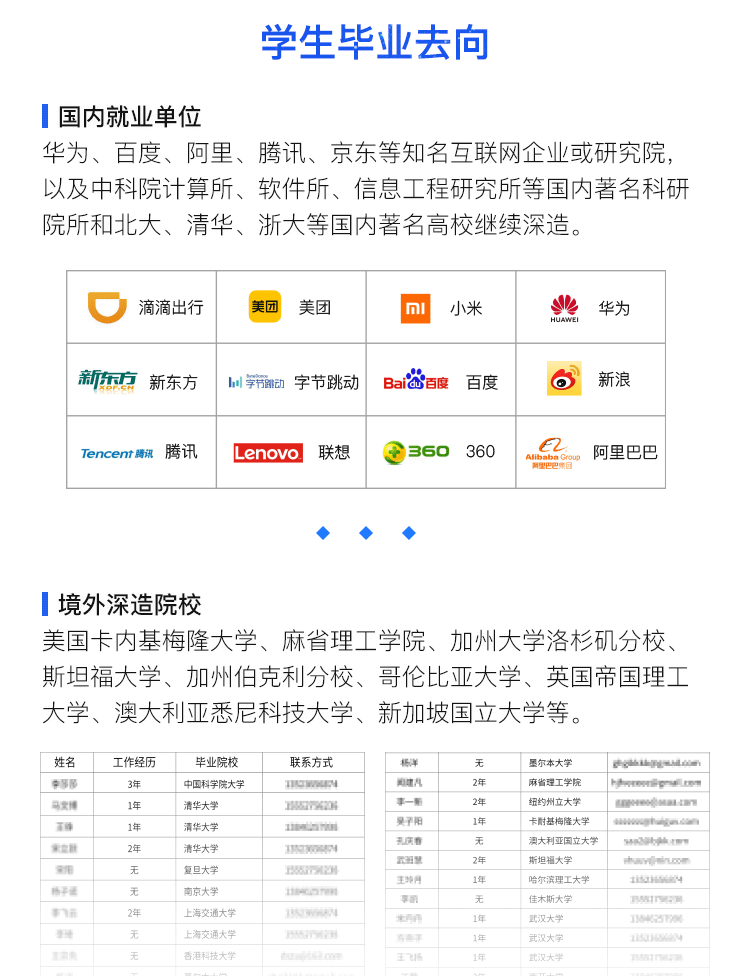
Applications and Key Technologies of Information Extraction
-
Named Entity Recognition
-
Common Techniques for NER Recognition
-
Entity Unification Techniques
-
Entity Disambiguation Techniques
-
Coreference Resolution
-
Applications of Relation Extraction
-
Rule-Based Methods
-
Supervised Learning Methods
-
Bootstrap Methods
-
Distant Supervision Methods
-
Applications of Syntactic Analysis
-
Introduction to CFG
-
From CFG to PCFG
-
Evaluating Parse Trees
-
Finding the Best Parse Tree
-
CKY Algorithm
-
From Syntactic Analysis to Dependency Grammar Parsing
-
Applications of Dependency Grammar Parsing
-
Dependency Grammar Parsing Based on Graph Algorithms
-
Transition-Based Dependency Grammar Parsing
-
Case Studies of Dependency Grammar
-
Importance of Knowledge Graphs
-
Entities and Relationships in Knowledge Graphs
-
Unstructured Data and Constructing Knowledge Graphs
-
Designing Knowledge Graphs
-
Applications of Graph Algorithms
-
Importance of Model Compression
-
Overview of Common Model Compression Techniques
-
Matrix Factorization-Based Compression Techniques
-
Distillation-Based Compression Techniques
-
Bayesian Model-Based Compression Techniques
-
Model Quantization
-
Graph Representation
-
Graphs and Knowledge Graphs
-
Common Algorithms on Graphs
-
Deepwalk and Node2vec
-
TransE Graph Embedding Algorithm
-
DSNE Graph Embedding Algorithm
-
Review of Convolutional Neural Networks
-
Designing Convolution Operations in Graphs
-
Information Propagation in Graphs
-
Graph Convolutional Networks
-
Classic Applications of Graph Convolutional Networks
-
From GCN to GraphSAGE
-
Regression of Attention Mechanism
-
Detailed Explanation of GAT Model
-
Comparison of GAT and GCN
-
Handling Heterogeneous Data
-
Node Classification
-
Graph Classification
-
Link Prediction
-
Community Mining
-
Recommendation Systems
-
The Future Development of Graph Neural Networks
Helping You Become theTOP 10% of Engineers
Students interested in the course
Scan the QR code for consultation

-
Undergraduate/Master’s/Doctoral students in related science and engineering majors who wish to pursue NLP work after graduation
-
Those who want to delve into the AI field, preparing for research or studying abroad
-
Those who wish to systematically learn knowledge in the NLP field
-
Currently working in IT-related jobs, wishing to work on NLP-related projects in the future
-
Currently working in AI-related jobs, hoping to keep up with the times and deepen their understanding of technology
-
Those who wish to keep up with cutting-edge technologies
Helping You Become theTOP 10% of Engineers
Students interested in the course
Scan the QR code for consultation
