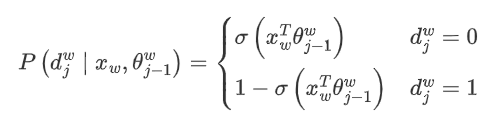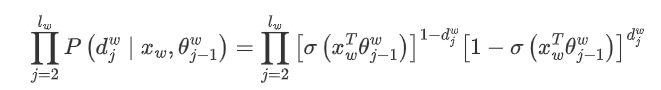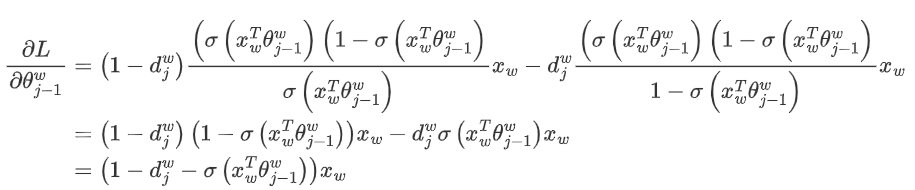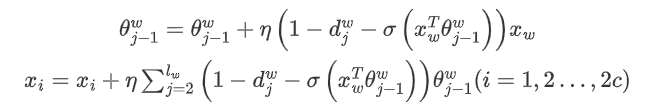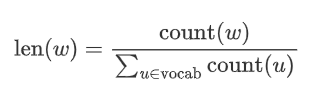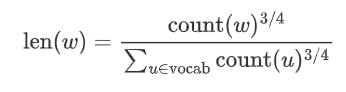Word2Vec is an NLP tool launched by Google in 2013. Its feature is to vectorize all words, allowing for a quantitative measurement of the relationships between words and the exploration of connections among them.
Word Vector: A representation of words in a vector space.
Why not use simple one-hot representation for word vectors?
One-hot representation (sparse vector) is very simple for representing word vectors, but it has many issues. The biggest problem is that our vocabulary is usually very large, for example, reaching millions, which means each word is represented by a million-dimensional vector, which is a disaster for memory. Such vectors actually have only one position with a value of 1, while all other positions are 0, making the expression inefficient.
Can we reduce the dimensionality of word vectors?
Distributed representation (distributed representation) can solve the problem of one-hot representation. The idea is to map each word to a shorter word vector through training. All these word vectors form a vector space, which can then be studied using ordinary statistical methods to explore the relationships between words. How large is this shorter word vector dimension? This is usually specified by us during training.
The basic idea of distributed representation is to map each word to a fixed-length short vector through training. All these vectors form a word vector space, where each vector can be viewed as a point in that space. The length of the vector can be chosen freely and is independent of the vocabulary size.
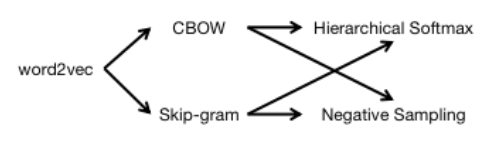
CBOW Model: The input is the word vectors of context words related to a specific feature word, and the output is the word vector of that specific word. (Continuous Bag-of-Words)
Skip-Gram Model: The input is the word vector of a specific word, and the output is the word vectors of context words corresponding to that specific word.
Traditional Neural Network Word Vector Language Model (DNN)
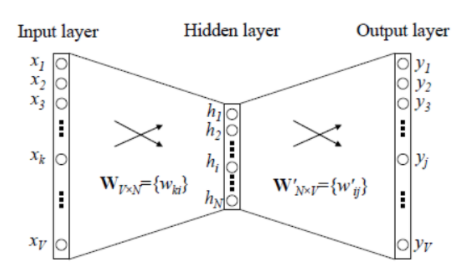
Before Word2Vec appeared, there were already methods using neural networks (DNN) to train word vectors to handle relationships between words. The methods generally involve a three-layer neural network structure (though it can also be multi-layered), consisting of an input layer, hidden layer, and output layer (softmax layer).
Typically, there are three layers: input layer (word vector), hidden layer, and output layer (softmax layer). The biggest problem lies in the computation from the hidden layer to the output softmax layer, which is very large because it requires calculating the softmax probabilities for all words and then finding the one with the highest probability. The model is illustrated below. Here, is the size of the vocabulary.
Dimensionality Understanding: The Input layer is processed through one-hot encoding, so the dimension of the Input Layer is , the first dimension of is , and the dimension of the Hidden layer is , and the dimension of the Output layer is .
The resulting word vector can be either or the concatenation of and .
Several concepts need to be clarified:
-
-
Dictionary: A set composed of words;
-
Corpus C: A sequence of texts composed of words;
The context of the word is the text sequence formed by the preceding words and the following words in the corpus, with being called the center word.
Reasons for using logarithm:
-
To prevent overflow, that is, to prevent the result from approaching 0.
-
Logarithm is a monotonous function, taking the log does not affect the result.
Cross-entropy represents the degree of similarity between the predicted true distribution and the model distribution.
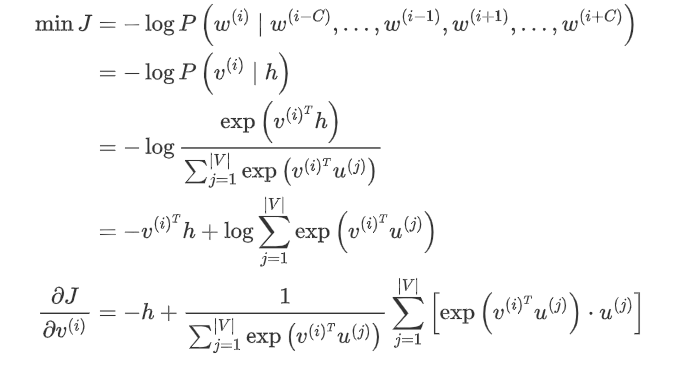
The main issue is that the processing of the DNN model is very time-consuming. Our vocabulary is generally over a million, meaning the output layer of our DNN requires a large computation for softmax to calculate the output probabilities for all words.
What method can replace DNN and be simpler?
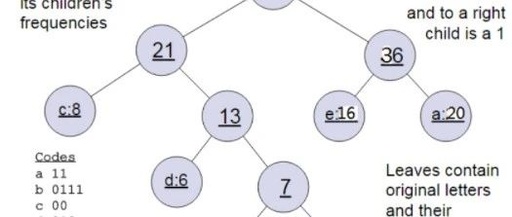
Huffman Tree
The Huffman tree replaces the neurons in the hidden layer and output layer. The leaf nodes of the Huffman tree act as the output layer neurons, and the number of leaf nodes corresponds to the size of the vocabulary. The internal nodes act as the hidden layer neurons.
Input: Nodes with weights of
Output: Corresponding Huffman tree
1) Treat as a forest with trees, each tree having only one node.
2) In the forest, select the two trees with the smallest root node weights to merge them into a new tree, with these two trees as the left and right subtrees. The weight of the new tree’s root node is the sum of the weights of the left and right subtree’s root nodes.
3) Delete the two trees with the smallest root node weights from the forest and add the new tree to the forest.
4) Repeat steps 2) and 3) until there is only one tree left in the forest.
What are the benefits of the Huffman Tree?
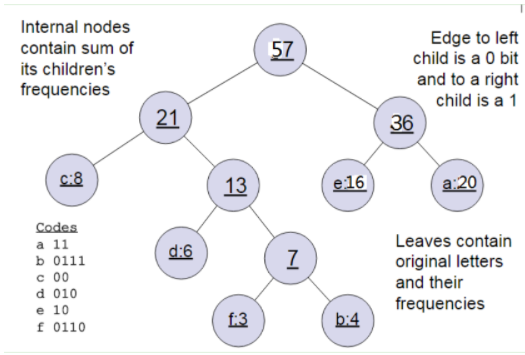
Generally, after obtaining the Huffman tree, we will perform Huffman coding on the leaf nodes. Since high-weight leaf nodes are closer to the root node, while low-weight leaf nodes are further away, our high-weight nodes will have shorter encoding values, while low-weight nodes will have longer encoding values. This ensures the shortest weighted path of the tree, which aligns with our information theory, meaning we hope that more frequently used words have shorter encodings.
How to encode?
For a node of a Huffman tree (excluding the root), we can agree that the left subtree is encoded as 0 and the right subtree as 1. As shown in the image above, the encoding for c would be 00.
In Word2Vec, the encoding method is agreed to be the opposite of the above example, that is, the left subtree is encoded as 1 and the right subtree as 0, while ensuring that the weight of the left subtree is not less than that of the right subtree. (The weight in Word2Vec corresponds to the frequency of the word in the corpus)
Two Improvements of Word2Vec
One is based on Hierarchical Softmax, and the other is based on Negative Sampling.
Hierarchical Softmax
The model based on Hierarchical Softmax (layered softmax)
In a traditional neural network word vector language model, there are generally three layers: input layer (word vector), hidden layer, and output layer (softmax layer). The biggest problem is the large computation from the hidden layer to the output softmax layer, as it requires calculating the probabilities for all words and then finding the one with the highest probability.
Improvement 1: Use a simple method to sum and average all input word vectors.
Improvement 2: Improve the computation from the hidden layer to the output layer. To avoid calculating the probabilities for all words, Word2Vec samples the Huffman tree to replace the mapping from the hidden layer to the output softmax layer.
The probability calculation from the output layer is transformed into a binary Huffman tree, so our probability calculation only needs to follow the tree structure.
All internal nodes of the Huffman tree are similar to the neurons in the hidden layer of the previous neural network, where the root node’s word vector corresponds to our projected word vector, and all leaf nodes are similar to the output layer neurons of the previous neural network. The number of leaf nodes corresponds to the size of the vocabulary. In the Huffman tree, the mapping from the hidden layer to the output layer is not completed at once, but is done step by step along the Huffman tree.
How to “complete step by step along the Huffman tree”?
In Word2Vec, we use binary logistic regression, which stipulates that moving left in the subtree corresponds to negative class (Huffman tree encoding 1), and moving right corresponds to positive class (Huffman tree encoding 0). The method of distinguishing between positive and negative classes uses the sigmoid function, which is: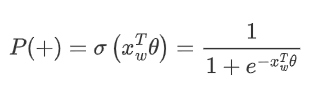 where is the word vector of the current internal node, and is the model parameter obtained from the training samples.
where is the word vector of the current internal node, and is the model parameter obtained from the training samples.
Advantages of Using the Huffman Tree
-
Since it is a binary tree, the previous computation amount of V is now reduced to log 2V.
-
Using the Huffman tree means that high-frequency words are closer to the root of the tree, so high-frequency words will be found more quickly, which aligns with our greedy optimization idea.
The goal is to find suitable word vectors for all nodes and all internal nodes θ, to maximize the likelihood of the training samples.
The weights of the Huffman tree are determined by the frequency of the words (importance).
Gradient Calculation for the Hierarchical Softmax Model
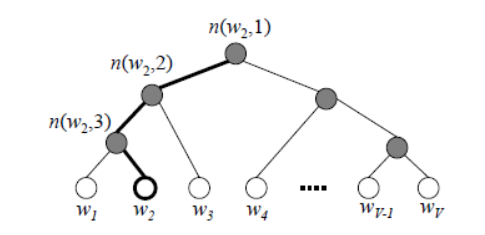
We use the maximum likelihood method to find the word vectors for all nodes and the model parameters for all internal nodes. Let’s take the example of w_ above. We aim to maximize the following likelihood function:
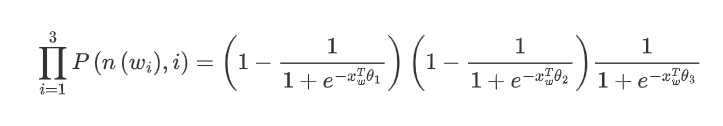 For all training samples, we aim to maximize the product of the likelihood functions for all samples. To facilitate our later generalized description, we define the input word as and the word vector of the root node of the Huffman tree after averaging the word vectors from the input layer as . The nodes traversed from the root node to the leaf node where is located total to , and the corresponding Huffman encoding for the node traversed in the Huffman tree is , where and the model parameters corresponding to that node are where is not included because the model parameters only pertain to the internal nodes of the Huffman tree.
Define the probability of a certain node traversed in the Huffman tree as and its expression is:
Then for a target output word , its maximum likelihood is:
To obtain the model parameters for the word vectors and internal nodes in the model, we can use gradient ascent. First, we find the gradient of the model parameter :
Using the same method, we can obtain the gradient expression for :
For all training samples, we aim to maximize the product of the likelihood functions for all samples. To facilitate our later generalized description, we define the input word as and the word vector of the root node of the Huffman tree after averaging the word vectors from the input layer as . The nodes traversed from the root node to the leaf node where is located total to , and the corresponding Huffman encoding for the node traversed in the Huffman tree is , where and the model parameters corresponding to that node are where is not included because the model parameters only pertain to the internal nodes of the Huffman tree.
Define the probability of a certain node traversed in the Huffman tree as and its expression is:
Then for a target output word , its maximum likelihood is:
To obtain the model parameters for the word vectors and internal nodes in the model, we can use gradient ascent. First, we find the gradient of the model parameter :
Using the same method, we can obtain the gradient expression for :
CBOW Model Based on Hierarchical Softmax
First, we need to define the dimensionality of the word vectors and the context size so that for each word in the training samples, the preceding words and the following words are used as the input for the model, and the word itself is used as the output of the sample, aiming for maximum probability.
-
First, build a Huffman tree based on the word frequency of the vocabulary.
-
From the input layer to the hidden layer (projection layer), sum and average the word vectors of the surrounding words.
-
Use gradient ascent to update and . Note that here, is formed from the sum of word vectors, so after the gradient update, the gradient term will be used to directly update the original each , i.e. :
4. If the gradient converges, the gradient iteration ends, and the algorithm ends; otherwise, return to step 3 and continue iterating.
Input: Training samples based on CBOW corpus, dimensionality of word vectors CBOW context size step size Output: Model parameters for the internal nodes of the Huffman tree all word vectors
Skip-Gram Model Based on Hierarchical Softmax
The input is only one word, and the output is word vectors, expecting these words to have a higher softmax probability than other words.
1. First, build a Huffman tree based on the word frequency of the vocabulary.
2. From the input layer to the hidden layer (projection layer), since there is only one word, is the word vector corresponding to word .
3. Use gradient ascent to update and . Note that here, has surrounding word vectors, and we expect to be maximized. At this point, we note that since the context is mutual, while maximizing , we also expect to maximize . So should we use or ? Using the latter is advantageous because within a selection window, we are not just updating one word but rather words. This makes the overall iteration more balanced. For this reason, the model does not iterate updates on the input as the model does, but iterates updates on the outputs. Thus, after the gradient update, the gradient term will be used to directly update the original each , i.e. :
4. If the gradient converges, the gradient iteration ends, and the algorithm ends; otherwise, return to step 3 and continue iterating.
Input: Training samples based on Skip-Gram corpus, dimensionality of word vectors Skip-Gram context size step size Output: Model parameters for the internal nodes of the Huffman tree all word vectors
Disadvantages of Hierarchical Softmax
Using the Huffman tree instead of a traditional neural network can improve the efficiency of model training. However, if the center word in our training samples is a very rare word, it can take a long time to traverse down the Huffman tree. Is there a simpler way to model without such complexity? Negative Sampling is one such improvement method.
Model based on Negative Sampling
For example, if we have a training sample where the center word is and it has context words, denoted as context. Since the center word is indeed related to , it is a true positive example. By sampling through Negative Sampling, we obtain neg different center words that are not related to , thus forming negative examples that do not actually exist. Using this one positive example and neg negative examples, we perform binary logistic regression to obtain the model parameters corresponding to each word and the word vectors for each word.
Negative Sampling Method
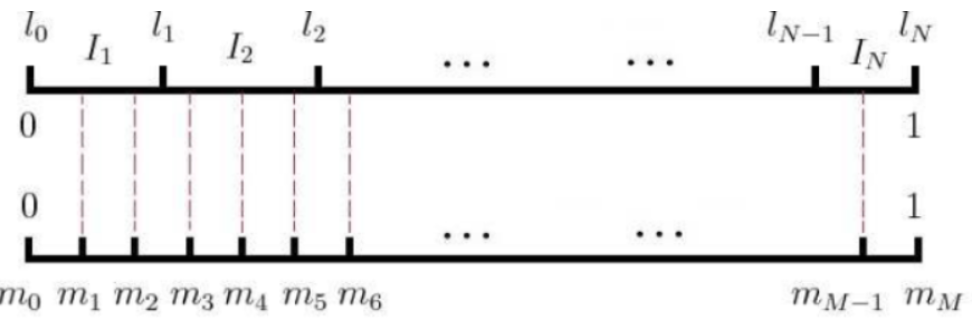
Now let’s see how to perform negative sampling to obtain neg negative examples. The sampling method is not complicated; if the vocabulary size is , we divide a line segment of length 1 into parts, with each part corresponding to a word in the vocabulary. Of course, the length of the line segment corresponding to each word varies; high-frequency words have longer segments, while low-frequency words have shorter segments. The length of each word’s segment is determined by the following formula:
In , both the numerator and denominator are raised to the power of 3/4 as follows:
Before sampling, we divide this line segment of length 1 into M parts, where M >> V, ensuring that each word’s corresponding segment is divided into corresponding small blocks. During sampling, we only need to sample neg positions from M positions, and each sampled position corresponds to a word in the segment that is our negative example.
The default value for neg is 5, and generally, we take between 3-10. If the sample size is very small, take 3; if it reaches hundreds of millions, you can choose 10. However, the default 5 can meet the vast majority of cases.
Generally, when the data volume is small, Hierarchical Softmax may perform better. If the data volume is very large, it is typically used.
Compared to CBOW, Skip-Gram has an additional layer of loops (2c times), so the computation is indeed about 2c times that of CBOW.
Given that skip-gram learns word vectors in more detail, it is more suitable to use skip-gram when there are many low-frequency words in the corpus.
The Skip-Gram model is akin to a “tutoring learning model,” where one student hires multiple tutors for one-on-one guidance. This is represented by each input center word (the student) gaining knowledge from multiple context word labels (the tutors).
The CBOW model is akin to a “large class teaching model,” where multiple students learn from a large class teacher, represented by each input of multiple context words (multiple students) gaining knowledge from the center word label (the large class teacher).
Using Gensim to train word vectors:
Dimensionality of the word vectors.
Maximum distance between the current and predicted word within a sentence.
min_count : int, optional (Ignore words with very low frequency)
Ignores all words with total frequency lower than this.
workers : int, optional (Number of threads, typically double the cores)
Use these many worker threads to train the model (=faster training with multicore machines).
sg : {0, 1}, optional (Generally, using skip-gram is better)
Training algorithm: 1 for skip-gram; otherwise CBOW.
hs : {0, 1}, optional (If using negative sampling, set this to 0)
If 1, hierarchical softmax will be used for model training.
If 0, and <span>negative</span> is non-zero, negative sampling will be used.
negative : int, optional (Negative sampling is often used)
If > 0, negative sampling will be used, and the int for negative specifies how many “noise words”
should be drawn (usually between 5-20).
If set to 0, no negative sampling is used.
NLP courses and related fields are currently offering limited-time benefits!
Grab the benefits here→ julyedu.com



Additionally, the 11th session of the NLP advanced small class has opened, offering 5 free trial spots. Interested parties can contact Teacher Su Su (VX: julyedukefu008) or other teachers at July Online to apply for a trial and learn about the course.
(Scan to contact Teacher Su Su)
Click “Read the Original” to grab the 1-second kill~