Author: Dhruvil Karani
Compiled by: ronghuaiyang
This article introduces some basic concepts of word embeddings and Word2Vec. It is very straightforward and easy to understand.
Word embeddings are one of the most common representations of a document’s vocabulary. They can capture the context, semantics, and syntactic similarities of a word in a document, as well as its relationships with other words.
What exactly are word embeddings? In simple terms, they are vector representations of specific words. Having discussed this, how do we generate them? More importantly, how do they capture context?
Word2Vec is one of the most commonly used techniques for learning word embeddings using shallow neural networks. It was developed by Tomas Mikolov at Google in 2013.
Let’s tackle this step by step.
Why Do We Need Word Embeddings?
Consider the similar sentences: Have a good day and Have a great day. They have nearly identical meanings. If we construct a comprehensive vocabulary (let’s call it V), then V = {have, a, good, great, day}.
Now, let’s create a one-hot encoded vector for each word in V. The length of our one-hot encoding vector is equal to the size of V (=5). We will get a vector where the element at the index corresponding to the respective word in the vocabulary is 1, and all others are 0. The following encodings illustrate this:
Have = [1,0,0,0,0]; a=[0,1,0,0,0]; good=[0,0,1,0,0]; great=[0,0,0,1,0]; day=[0,0,0,0,1] (‘ indicates transpose)
If we try to visualize these encodings, we can imagine a 5-dimensional space where each word occupies one dimension, independent of the others (no projection along other dimensions). This means that the difference between “good” and “great” is treated the same as the difference between “day” and “have”, which is not accurate.
Our goal is to place words with similar contexts near each other in space. Mathematically, the cosine of the angle between these two vectors should be close to 1, meaning the angle is close to 0.

This leads to the idea of generating distributed representations. Intuitively, we introduce a dependency of one word on another. In the context of this word, these words will have more of this dependency. In a one-hot encoded representation, all words are independent of each other.
How to Obtain Word2Vec?
Word2Vec is a method for constructing such embeddings. It can be obtained through two approaches (both involving neural networks): Skip Gram and Continuous Bag Of Words (CBOW).
CBOW Model: This method takes the context of each word as input and tries to predict the word corresponding to that context. Consider our example: Have a great day.
Let the input to the neural network be the word great. Here, we try to predict a target word (day) using the single context input word great. More specifically, we use a one-hot encoding of the input word and measure the error with the one-hot encoding of the target word (day). During the process of predicting the target word, we learn the vector representation of the target word.
Let’s delve deeper into the actual architecture.
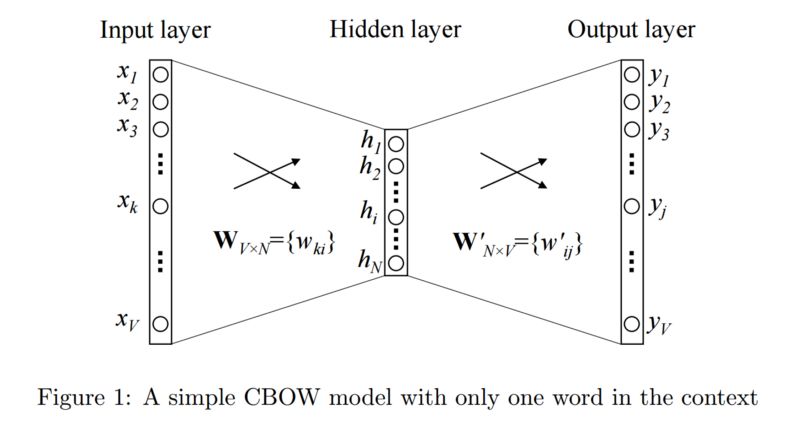
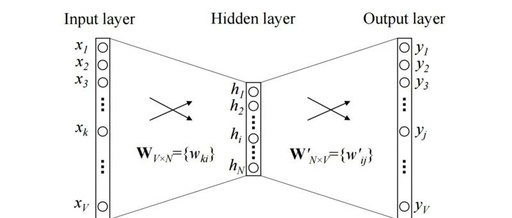
The input or context word is a one-hot encoded vector of length V. The hidden layer contains N neurons, and the output is also a vector of length V, where the elements are softmax values.
Let’s understand some terms in the diagram:
-
Wvn is the weight matrix (V*N dimensional matrix) that maps the input x to the hidden layer
-
Wnv is the weight matrix (N*V dimensional matrix) that maps the hidden layer output to the final output layer
I won’t go into the mathematics. We just need to know what happens.
The hidden layer neurons simply weight the input and pass it to the next layer. There are no activations like sigmoid, tanh, or ReLU. The only nonlinear computation occurs in the softmax of the output layer.
However, the above model uses a single context word to predict the target. We can use multiple context words to do the same.
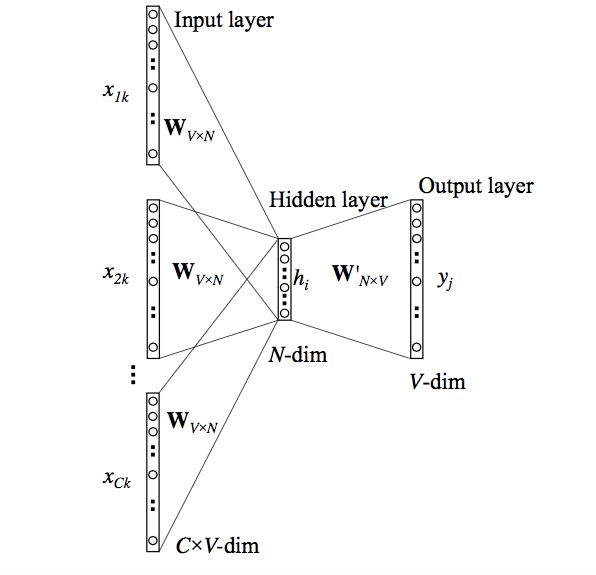
The above model uses C context words. When Wvn is used to compute the hidden layer input, we average all these C context inputs.
We have seen how to generate word representations using context words. But there is another way to achieve the same. We can use the target word (for which we want to generate its representation) to predict the context and generate the representation in the process. Another variant known as the Skip Gram model can do this.
Skip-Gram Model:
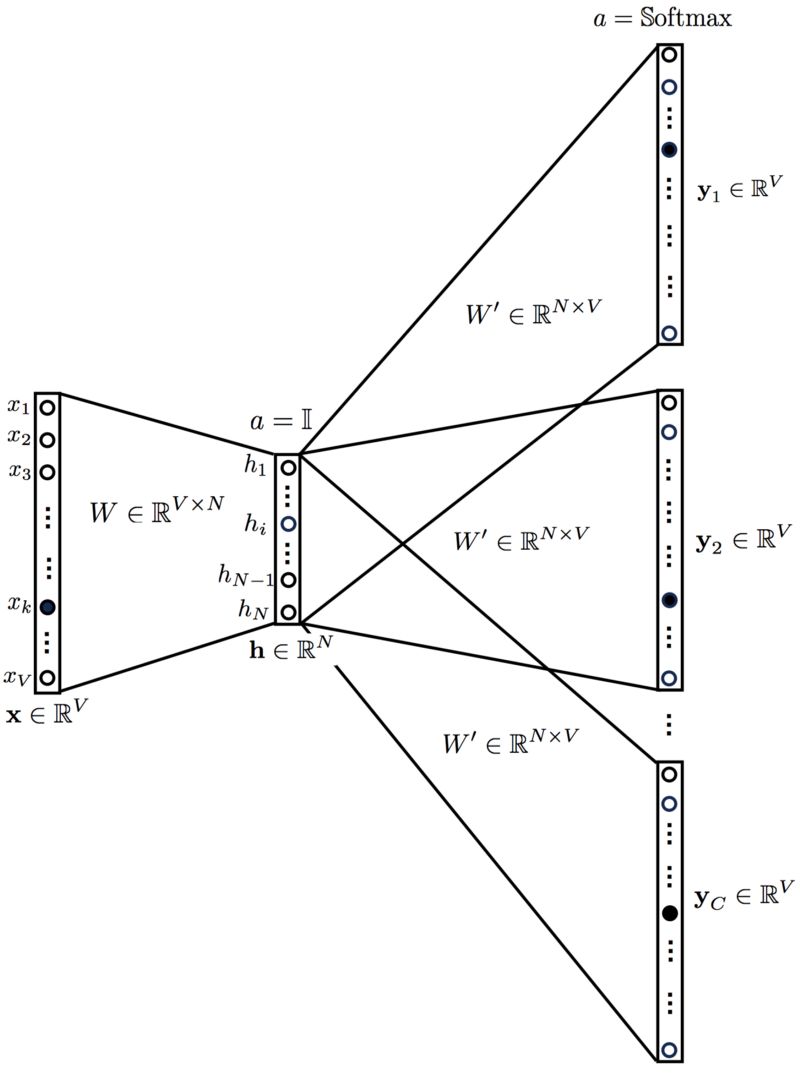
This looks like flipping the multi-context CBOW model. This is somewhat correct.
We input the target word into the network. The model outputs C probability distributions. What does this mean?
For each context position, we get C probability distributions of V probabilities, one for each word.
In both cases, the network uses backpropagation to learn. Detailed mathematical computations can be found here.
Which One is Better?
Both have their own advantages and disadvantages. Mikolov stated that Skip Gram handles small datasets well and represents rare words effectively.
On the other hand, CBOW is faster and provides a better representation for more frequent words.
What’s Next?
The explanation above is a very basic one. It gives you a high-level understanding of what word embeddings are and how Word2Vec works.
There is still much to explore. For example, techniques like hierarchical softmax and Skip-Gram negative sampling are used to improve the computational efficiency of the algorithm. All of this can be found here (https://arxiv.org/pdf/1411.2738.pdf).

Original English text:https://towardsdatascience.com/introduction-to-word-embedding-and-word2vec-652d0c2060fa

Please long-press or scan the QR code to follow this public account