Since Tomas Mikolov from Google proposed Word2Vec in “Efficient Estimation of Word Representation in Vector Space”, it has become a fundamental component of deep learning in natural language processing. The basic idea of Word2Vec is to represent each word in natural language as a short vector with a unified meaning and dimension. As for what each dimension in the vector specifically represents, no one knows, nor is it necessary to know; it may correspond to some of the most basic concepts in the world. However, reading the paper to understand the model generation of Word2Vec can still be somewhat confusing, so I had to turn to the code for clarity, and now I would like to share it with everyone.
Any language is composed of a collection of words, and all words constitute a vocabulary. The vocabulary can be represented by a long vector. The number of words is the dimension of the vocabulary vector. Therefore, any word can be represented as a vector, where the position of the word in the vocabulary is set to 1, and other positions are set to 0. However, this representation of word vectors does not allow for overlaps between words, which is not very useful.
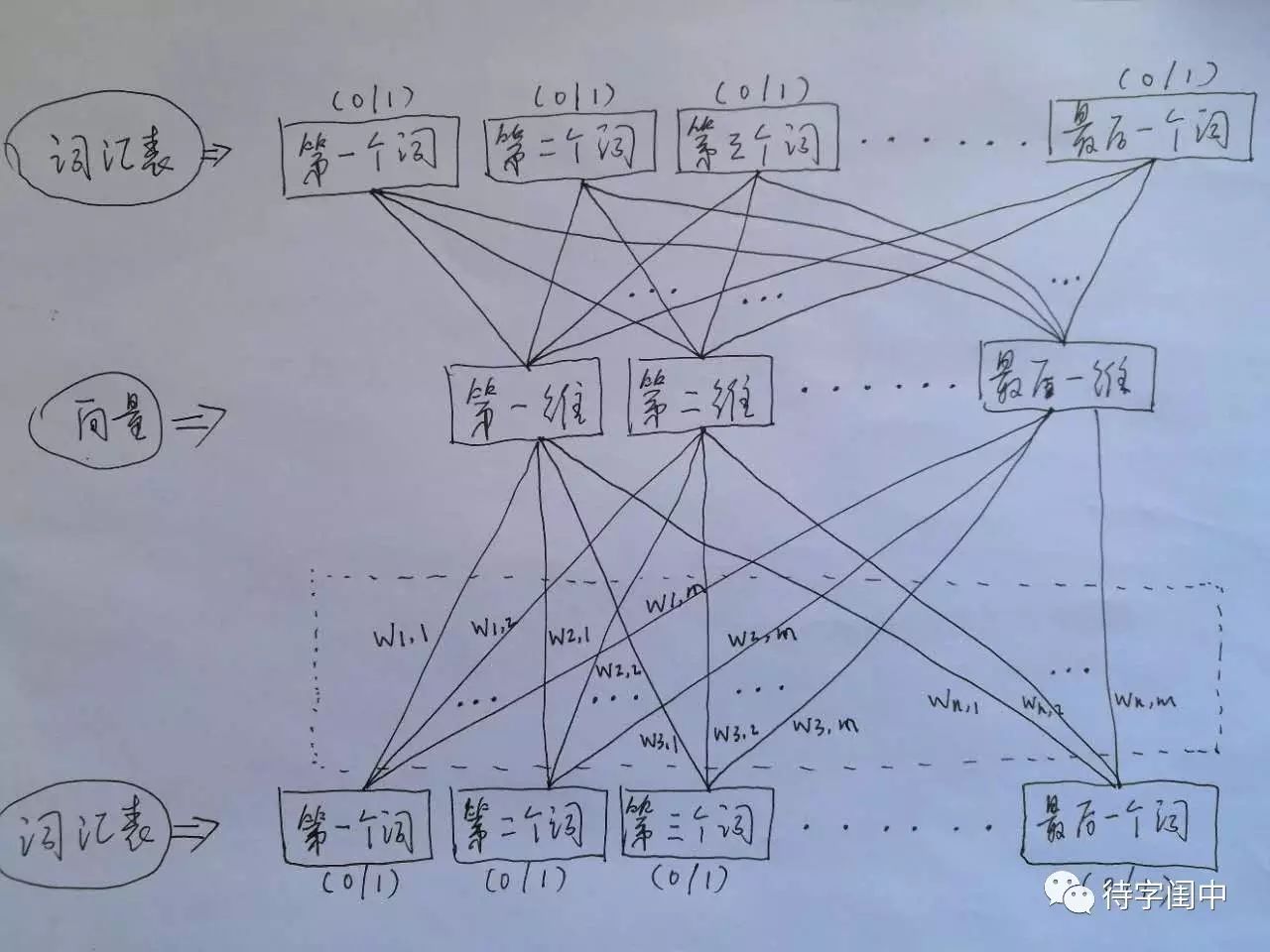
The training model of Word2Vec is essentially a neural network with a hidden layer (as shown in the figure below). Its input is the vocabulary vector, and when a training sample is seen, for each word in the sample, the corresponding position in the vocabulary is set to 1, otherwise set to 0. Its output is also a vocabulary vector, where for each word in the label of the training sample, the corresponding position in the vocabulary is set to 1, otherwise set to 0. Thus, for all samples, the neural network is trained. After convergence, the weights from the input layer to the hidden layer are taken as the vectors for each word in the vocabulary. For example, the vector for the first word is (w1,1 w1,2 w1,3 … w1,m), where m represents the dimension of the vector. All weights in the virtual boxes represent the values of all word vectors. With the finite-dimensional vectors for each word, they can be used in other applications, as they are like images, having a finite-dimensional unified input of meaning.
The idea behind training Word2Vec is to use a word and its contextual words in the text, thus eliminating the need for manual labeling. The paper presents two training models for Word2Vec, CBOW (Continuous Bag-of-Words Model) and Skip-gram (Continuous Skip-gram Model).
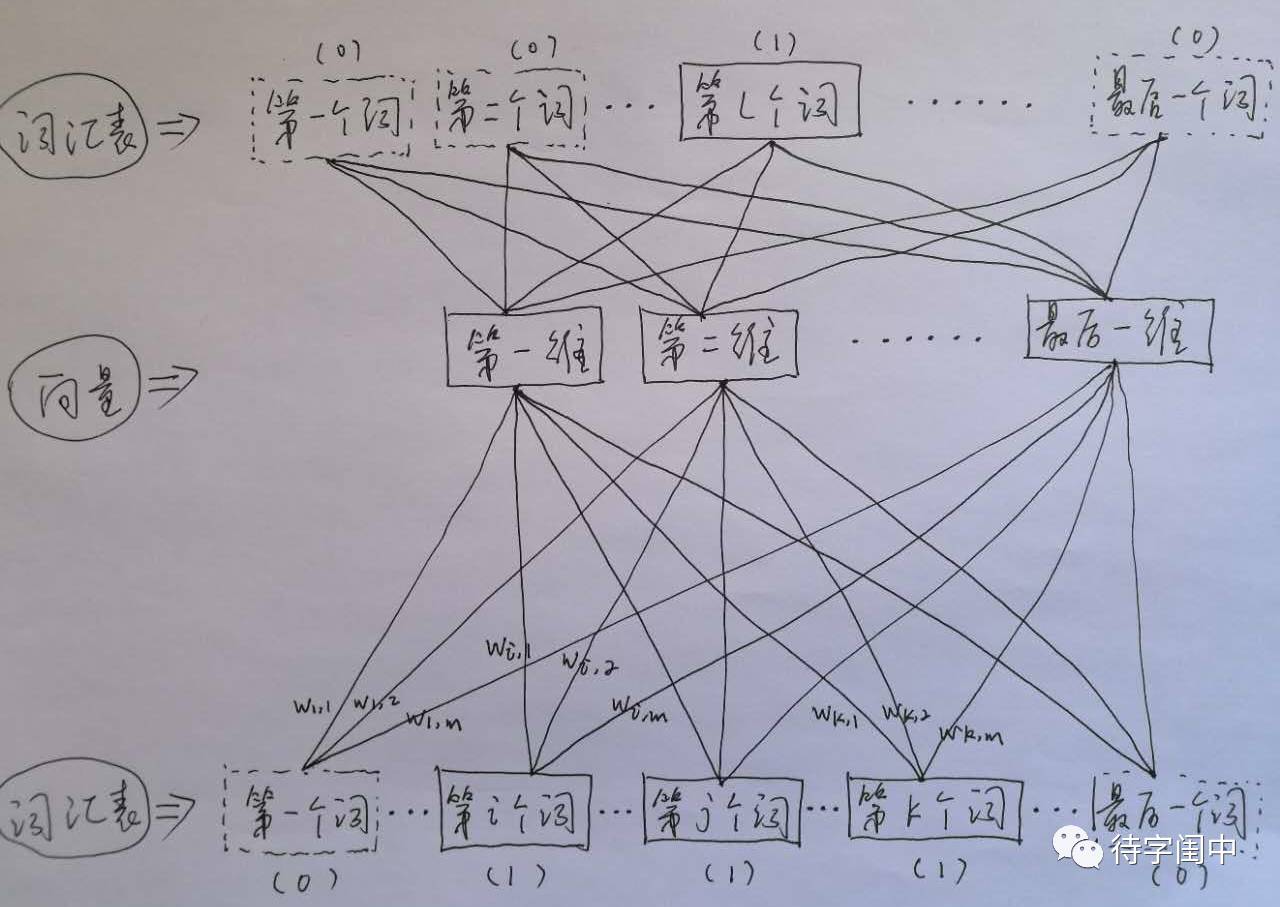
First, let’s look at CBOW. Its approach is to use the words in the context of a word as input, and that word itself as output. In other words, when seeing a context, the goal is to guess the word and its meaning. By training on a large corpus, a weight model from the input layer to the hidden layer is obtained. As shown in the figure below, if the context words for the l-th word are i, j, k, then i, j, k are used as input, and their positions in the vocabulary are set to 1. The output is l, with its position in the vocabulary also set to 1. After training is completed, the weights from each word to each dimension of the hidden layer are obtained, which are the vectors for each word.
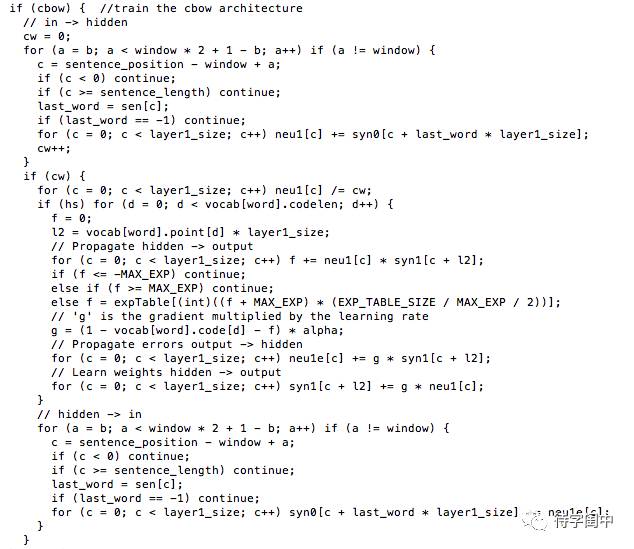
The code for CBOW training in the Word2Vec codebase is essentially the standard backpropagation algorithm for neural networks.
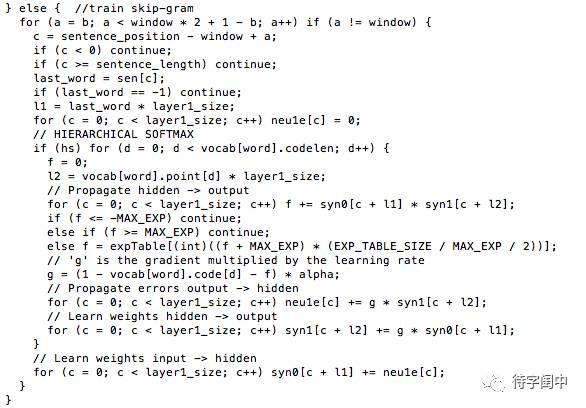
Next, let’s look at Skip-gram. Its approach is to use the words in the context of a word as output, and that word itself as input. In other words, given a word, the goal is to predict the possible contextual words. By training on a large corpus, a weight model from the input layer to the hidden layer is obtained. As shown in the figure below, if the context words for the l-th word are i, j, k, then i, j, k are used as output, and their positions in the vocabulary are set to 1. The input is l, with its position in the vocabulary also set to 1. After training is completed, the weights from each word to each dimension of the hidden layer are obtained, which are the vectors for each word.

The code for Skip-gram training in the Word2Vec codebase is also the standard backpropagation algorithm for neural networks.
When a person reads a book and encounters an unfamiliar word, they can generally guess the meaning of the unfamiliar word based on the context. Word2Vec captures this human behavior very well, using a neural network model to discover an atomic bomb in natural language processing.