Deep learning has achieved great success in natural language processing (NLP) tasks, among which distributed representation of words is a crucial technology. To deeply understand distributed representation, one must delve into word2vec. Today, let’s explore how the Huffman Tree is generated in the word2vec code.
This is a very important data structure in word2vec, used to represent a word in the vocabulary and its Huffman encoding. cn is the frequency of the word in the training set, point is the path of the encoding node, word is the string of the word, codelen is the length of the encoding, and code represents the encoding as a string of 0s and 1s.

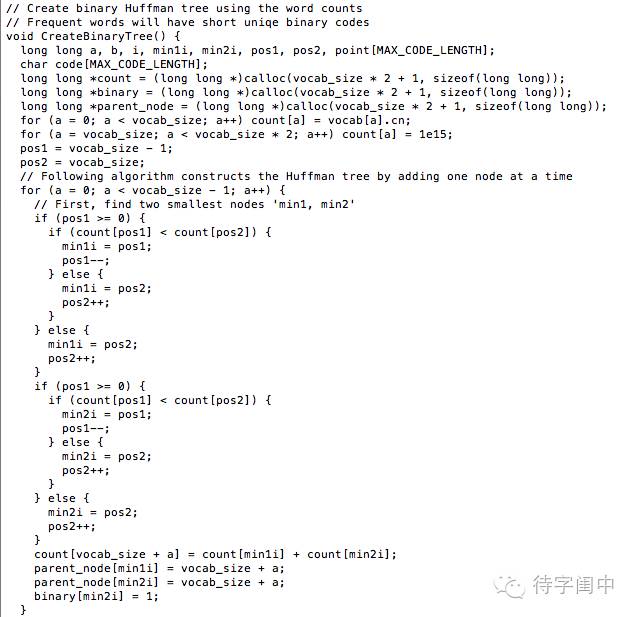
Below is the function for generating the Huffman Tree. Just looking at it can be a bit challenging, so let’s try to understand it through an example. This is a common way to read and understand code.
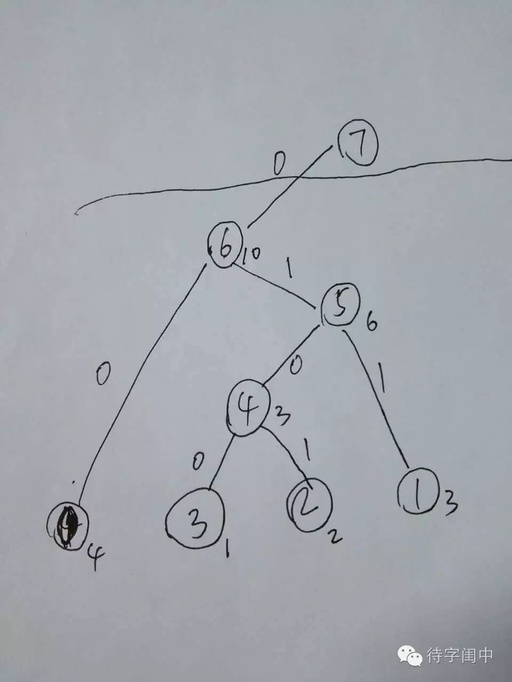
With paper and pen ready, our example has a vocabulary count of [4, 3, 2, 1], with four words sorted. We will follow the execution of the program, recording each variable step by step to facilitate understanding.

Thus, the generated Huffman Tree is as follows.
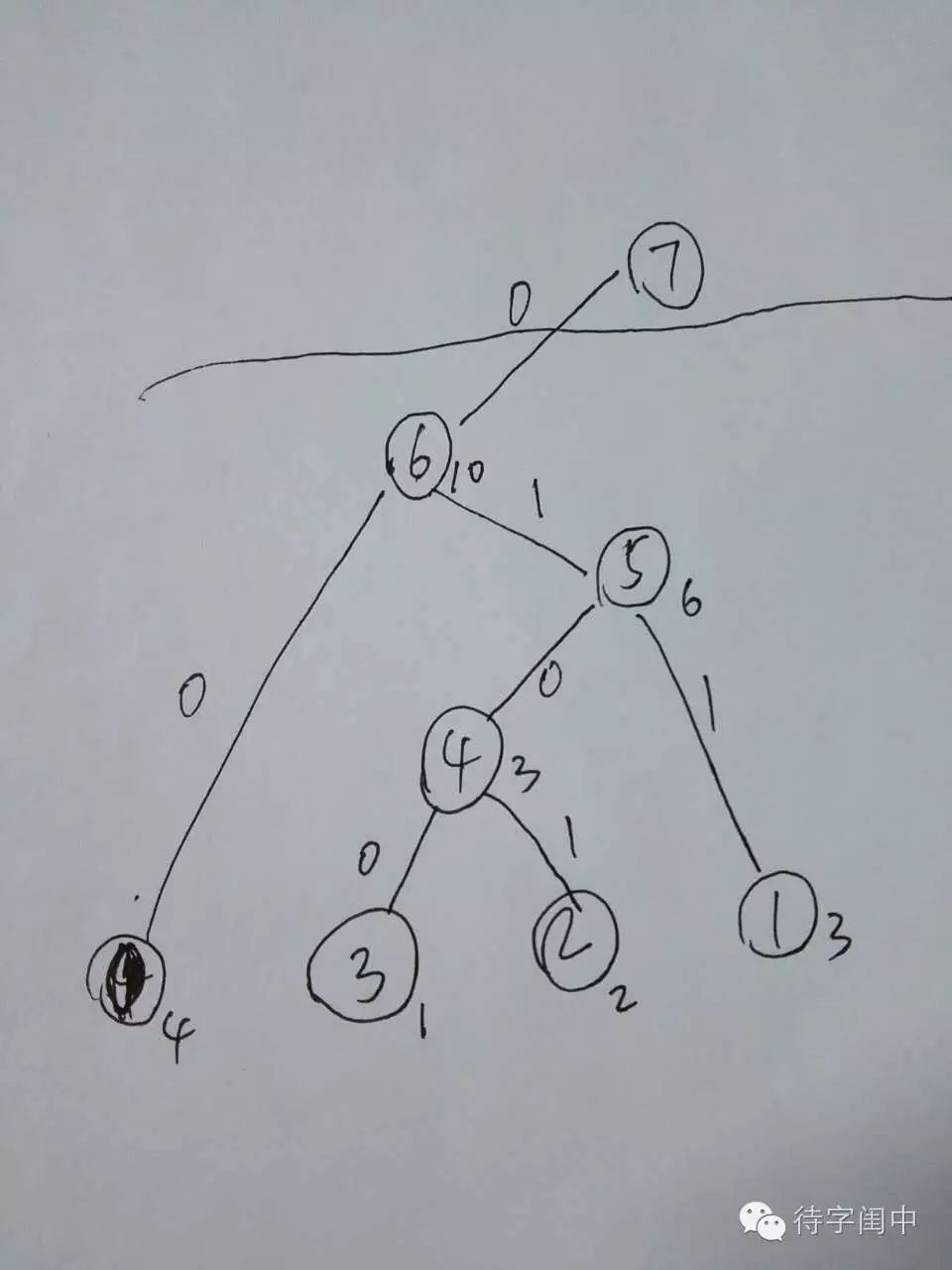
Next, let’s see how to convert the above temporary data structure into encoding. Each word will be assigned a code, with shorter lengths for codes of higher frequency.

Then, with paper and pen, let’s look at how the entire process unfolds.


At this point, we have completed the execution of the Huffman Tree generation function with our paper and pen, gaining a deeper understanding of the code. Learning from others’ code is also a process of self-improvement. Next time, whether in an interview or at work, when encountering similar problems, it should no longer feel unfamiliar.