
Introduction
In the past week, anyone who loves technology and is not living on Mars has certainly been inundated with news about OpenAI’s ChatGPT. Compared to previous publicly available conversational bots, ChatGPT shows a significant improvement in performance. It can reliably provide functions for everyday conversations and knowledge acquisition, assist in writing documents and code based on human requests, and even correct various errors in texts or bugs in code. I believe many people outside of the AI field might feel a sense of “Why has AI suddenly become so powerful?” This article aims to answer that question. Before we begin, I feel it’s necessary to express my own opinion: the leap in NLP technology is not marked by ChatGPT itself, but rather by the introduction of the Transformer and GPT technologies proposed between 2017 and 2018.
ChatGPT is the culmination of the development of technologies such as Transformer and GPT. Overall, the main reasons for ChatGPT’s outstanding performance can be summarized in three points:
The machine learning model used has strong expressive capabilities.
The volume of data used for training is enormous.
The advanced nature of the training methods. We will explore these three points next.
Machine Learning Models
Before diving into the main topic, let’s review the history of NLP development.
Grammar-Based Models
During this phase, the main approach to processing natural language was to utilize the wisdom of linguists to try to summarize a set of natural language grammar and write rule-based algorithms for natural language processing. This method sounds reasonable at first, right? In fact, compilers that we are familiar with also use this method to compile high-level languages into machine languages. Unfortunately, natural language is extremely complex, making it almost impossible to write a complete grammar to handle all cases. Therefore, this approach generally can only handle a subset of natural languages, falling far short of universal natural language processing.
Statistical Models
In this phase, people began to attempt to derive a statistical language model by performing statistics on a large number of existing natural language texts (which we call corpora). For example, through statistics, it is clear that the probability of the word “rice” following “eat” is higher than that of other words like “beef,” i.e., P(rice|eat) > P(beef|eat).
Although many models were used during this phase, they essentially all performed statistics on the corpus to derive a probability model. Generally speaking, different purposes lead to different probability models. However, for the sake of convenience, we will use the most common language model as an example, which models “the probability of a word following a given context.” The probability of one word following another is actually a unigram language model.
Model Expressive Capability
Here, it’s appropriate to introduce the concept of model expressive capability.

Model expressive capability refers to the model’s ability to represent data. For example, the unigram language model cannot distinguish between “the cow eats grass” and “I eat rice” because it models the probability of one word following another based solely on the previous word. When calculating whether to select “grass” or “rice,” it relies on the word “eat,” losing the context of “cow” and “I.” No matter how much data you feed it, a unigram language model cannot learn the relationship between cows and grass.
Model Parameter Count
Some may ask, if that’s the case, why don’t we calculate the probability of the next word based on more context rather than just the previous word? This is essentially what is known as an n-gram language model. Generally speaking, the larger n is, the more parameters the model has, and the stronger its expressive capability. Naturally, the amount of data required to train the model also increases (because the number of probabilities to be computed increases).
Model Structure
However, another limiting factor for model expressive capability is the structure of the model itself. For n-gram language models based on statistics, they simply count the probabilities of a word appearing after certain words without understanding the various grammatical and lexical relationships, so they still cannot model some complex sentences. For example, “I have been playing games all day” and “I have been playing games before dark” are semantically very similar, but statistical models cannot understand their similarity. Therefore, even if you feed massive amounts of data to a statistical model, it cannot learn to the level of ChatGPT.
Neural Network-Based Models
As mentioned earlier, the main drawback of statistical language models is their inability to understand the deeper structure of language. There was a time when scientists attempted to combine grammar-based models with statistical models. However, the spotlight was soon taken over by neural networks.
RNN & LSTM
Initially, the popular neural network language models were mainly Recurrent Neural Networks (RNN) and their improved version, LSTM.

The main structure of RNN is as follows, where x is the input, o is the output, and s is the state.
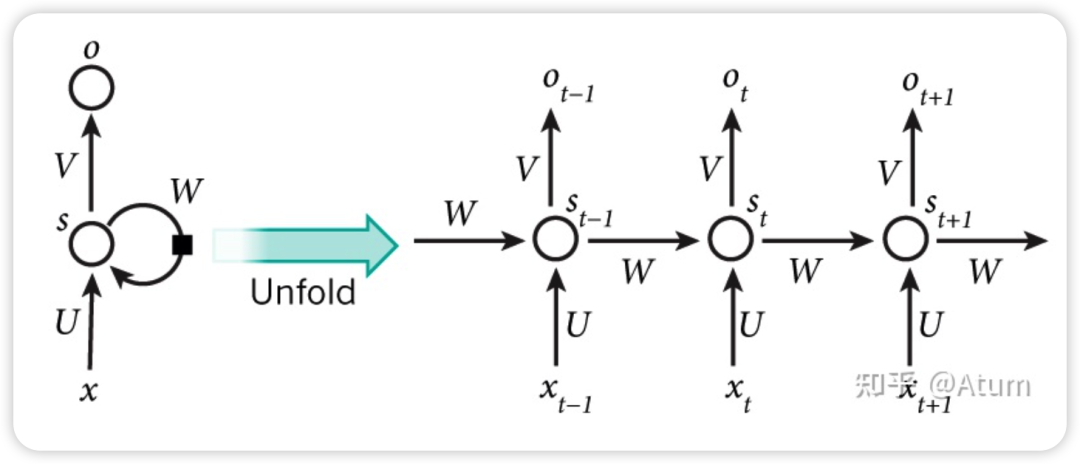
If RNN is used as a language model, then x can be the words fed in sequentially, and o can be the output words, while s is the state variable generated during the computation of o from x. This state variable can be understood as the context, which condenses all the words that have appeared in the previous text and is iteratively updated during the calculations. This is the fundamental principle behind why RNN can model the relationships between words.
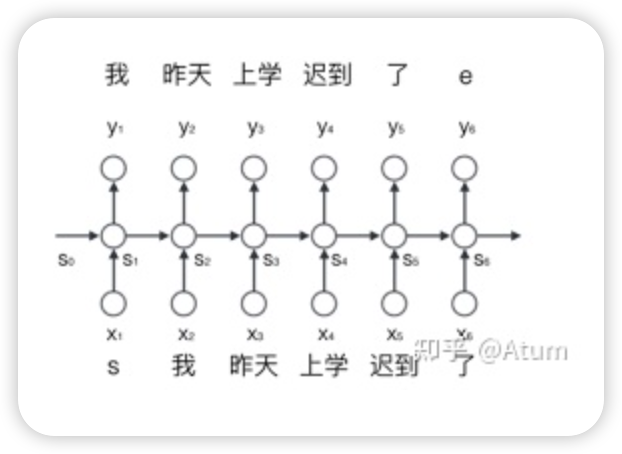
Compared to simple statistical models, the main highlight of recurrent neural networks is their ability to model the relationships between different words in a piece of text, which somewhat resolves the deep understanding issue faced by statistical models.

Attention Mechanisms
Before going further, we must mention the Attention mechanism.

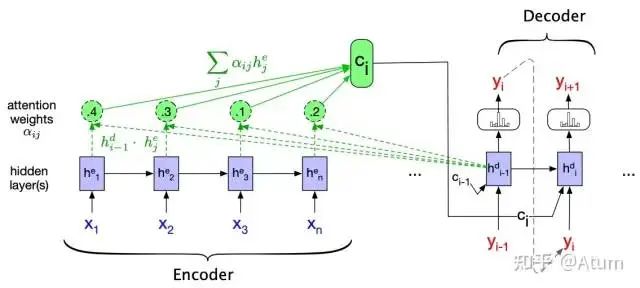
This mechanism mainly improves the state S as context in RNN language models. In RNN, the current state’s computation after the i-th word is primarily iterated from the previous word’s state Si-1. Its main drawback is that it assumes that the relationships between closer words are stronger. However, we all know that this assumption does not always hold in natural language. With the introduction of Attention, the computation of the state after the i-th word changes from a simple Si to a combination of S0, S1…Si, where the specific way of “how to combine,” i.e., which states are more important, is also fitted through data. In this scenario, the model’s expressive capability is further enhanced, allowing it to understand relationships between words that are far apart yet closely related, such as the relationship between pronouns and the nouns they refer to.
Transformer
Next, we can finally introduce one of the milestones in the leap of NLP, the proposal of the Transformer!
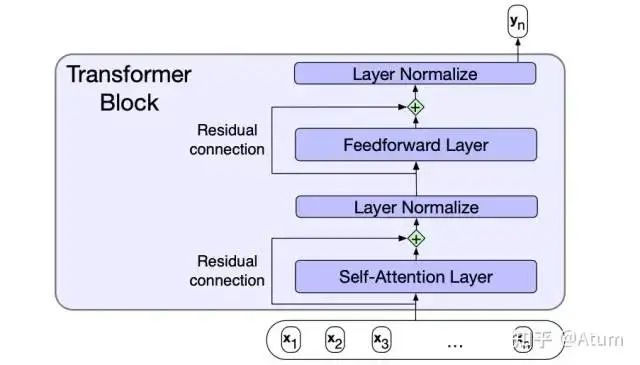
In fact, with the advent of Attention, the introduction of the Transformer was a natural progression. The main contributions of the Transformer are:
Integrating Multi-Head Self-Attention directly into the network. Multi-Head Self-Attention refers to multiple parallel Self-Attention mechanisms that can model various relationships between words.
Using dedicated position encoding to replace the sequential input used in RNN, making parallel computation possible.
For an illustrative but inaccurate example, consider the sentence “I often play skating board which is my favorite sport.” If we use Multi-Head Self-Attention, one set of Attention can be dedicated to modeling the verb-object relationship between “play” and “skating board,” while another set can model the modifying relationship between “skating board” and “favorite.” This further enhances the model’s expressive capability.

The underlying model that ChatGPT relies on, GPT-3.5, is based on the Transformer.
Training Data
Now that we have a model called Transformer, which through Multi-head Self-Attention makes it possible to establish complex relationships between words, we can say it is a language model with strong expressive capability. However, a language model without data is like a skilled cook without ingredients.
The related data for GPT-3.5 has not been disclosed. Let’s discuss its predecessor, GPT-3. The entire neural network of GPT-3 already has 175 billion parameters. It’s not hard to understand: how does Attention determine which words are important in the current context? And how does the network generate output through Attention and input? These are all determined by parameters within the model. This is why, under the same model structure, the more parameters there are, the stronger the expressive capability. So how are these model parameters obtained? They are learned from data! In fact, most of what is referred to as neural network learning is learning parameters.
To train a neural network with 175 billion parameters, how much data do you need? A lot! (from Wikipedia)
Dataset # Tokens Weight in Training Mix
Common Crawl 410 billion 60%
WebText2 19 billion 22%
Books1 12 billion 8%
Books2 55 billion 8%
Wikipedia 3 billion 3%
It’s easy to imagine that a model with such strong expressive capability, after being fed trillions of data, has begun to understand language itself at a level approaching human understanding. For instance, when processing sentences, it learns through training Attention parameters which words have relationships and which words are synonymous, among other deep language issues.
This was just GPT-3 in 2020. Now it’s 2022, and it is believed that the expressive capability of the GPT-3.5 model has significantly improved compared to GPT-3.
Training Methods
Supervised Learning vs. Unsupervised Learning
In simple terms, supervised learning is learning from datasets that have “answers.” If we want to train a Chinese-to-English machine translation model using supervised learning, we need to have Chinese text along with its corresponding English translation. The entire training process involves constantly feeding Chinese into the model, which outputs English. We then compare the model’s output with the standard answer (measured by loss function) and adjust the model parameters if the difference is significant. This has been the main training method for early machine translation models.

Transfer Learning
However, “answers” are ultimately limited. This has also restricted the design complexity of many previous natural language learning models. It’s not that we don’t want to improve the model’s expressive capability, but rather that once we do, the parameters increase too much, and we lack sufficient “answer” data to train the model.
In 2018, another milestone in NLP came with the proposal of GPT.

The main contribution of GPT is that it proposed a new training paradigm for natural language. It trains a language model through massive amounts of unsupervised learning data. As we mentioned earlier, a language model predicts the next word in a context, which clearly does not require labeled data; any existing corpus can serve as training data. Since GPT leverages the highly expressive Transformer, and given the vast amounts of unlabeled natural language data available on the internet, the resulting model has a relatively deep understanding of language.
At this point, if you want this language model to chat with you, you only need to feed it some conversational data to fine-tune the already language-understanding model using supervised learning. This operation is also called transfer learning.
During the transfer learning process, fine-tuning is generally performed through simple supervised learning. In simple terms, ChatGPT constructs some conversational prompts, has humans label desired responses, and uses this data for supervised learning to fine-tune the model.
Reinforcement Learning
In addition to fine-tuning, ChatGPT also employs a technique called reinforcement learning from human feedback (RLHF). This technique plays a major role in aligning the pre-trained model’s objectives to the specific downstream application of chatting. It has greatly enhanced ChatGPT’s conversational abilities.
The overall principle is illustrated in the following diagram. After completing model fine-tuning, a reward network is first trained with human assistance, capable of ranking multiple chat responses. Then, this reward network is used to further optimize the chat model through reinforcement learning. The details of this training method can be found in the paper.
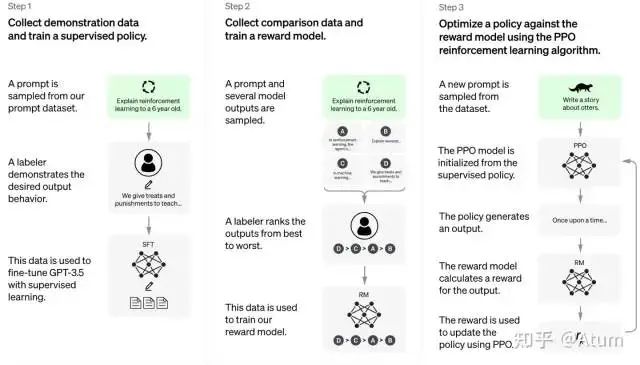
After this series of operations, ChatGPT has become what we see now.
Conclusion
In summary, ChatGPT is not as mysterious as it seems; it is essentially a combination of vast amounts of data and a highly expressive Transformer model, allowing for very deep modeling of natural language. For any given input sentence, ChatGPT generates a response under the influence of this model’s parameters.
Some may find that ChatGPT often produces nonsensical answers. This is an unavoidable downside of this method, as it essentially generates responses by maximizing probabilities rather than through logical reasoning.
Asking ChatGPT serious technical questions may also yield unreliable answers.
References
Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).
Ouyang, Long, et al. “Training language models to follow instructions with human feedback.” arXiv preprint arXiv:2203.02155 (2022).
Chen, Mark, et al. “Evaluating large language models trained on code.” arXiv preprint arXiv:2107.03374 (2021).
Neelakantan, Arvind, et al. “Text and code embeddings by contrastive pre-training.” arXiv preprint arXiv:2201.10005 (2022).