The Difficult Journey of “Speaking Human Language”
There are many definitions and standards for AI, but the ability to “converse with humans” seems to be an unavoidable threshold, an important criterion for assessing AI’s intelligence, and a necessary condition for the public to understand and accept AI.
To this end, AI scientists and engineers have made arduous efforts and have long achieved certain results. When you ask a smart watch to set an alarm or a smart speaker to report the weather, it is AI programs listening to your commands and responding accordingly. However, the level of these AI algorithms is indeed disappointing. Either they fail to understand your commands or they are easily confused by mischievous children. Ultimately, you wouldn’t consider them to have “intelligence”.
Although their capabilities are limited, these efforts have indeed established a technical framework for using AI to process human language.For example, sentences are segmented into tokens, which are words in English and characters in Chinese.The neural networks of AI learn the patterns of how these tokens form sentences through extensive training data, and to some extent establish connections between the tokens and their inherent meanings.

The rhythm of ChatGPT’s “speech” indicates that it generates answers token by token (image source [1])
Once the rules of tokens are learned, conversation can begin. The act of AI generating new content is referred to as “generation”, which is what the G in ChatGPT stands for.
When generating the current token, the neural network model calculates the probability of all tokens in the token library appearing at the current position based on the text that has already been generated, and then randomly selects a token to output at that position. This process is repeated continuously until all tokens in the sentence are generated one by one.
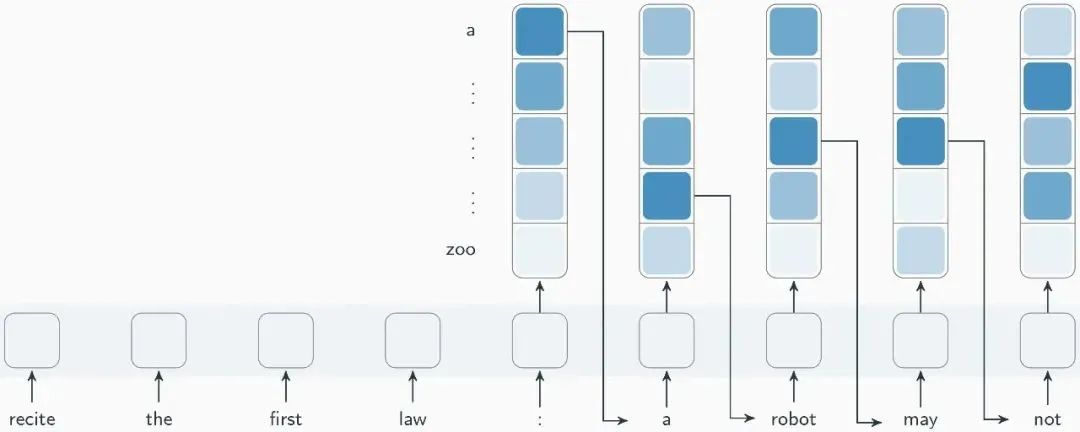
Illustration of the neural network model generating a sentence.
The question is, where do these probabilities come from?
A simple and direct idea is to use the frequency of tokens appearing in the language as probabilities.For example, in English: we can collect a large amount of language data to count the frequency of each English word and use it to guide the generation of tokens. Below is a possible generation result (source [2]), which is essentially nonsensical.
of program excessive been by was research rate not here of of other is men were against are show they the different the half the the in any were leaved
A single token is insufficient, so what about phrases? Intuitively, if the previous token is given, the range of options for the next token will be greatly reduced. For instance, if the token “merry” is given, the probability of “Christmas” following it is much higher than that of other tokens. Below is an example generated based on the frequency of two tokens (source [2]), which seems somewhat better, but still not “human language”.
cat through shipping variety is made the aid emergency can thecat for the book flip was generally decided to design ofcat at safety to contain the vicinity coupled between electric public
Since two tokens are not good enough, what about longer sequences? After all, there is a “belief” in AI that great effort yields miracles!
While the idea is good, there are two problems. First, it isdifficult to determine the number of tokens in each group, since the length of human language varies widely. Second, even if the number can be determined, it isdifficult to count the frequency of each group of tokens, because the number is simply too large. For example, there are about 40,000 commonly used words in English, and if we count them in pairs, there will be about 1.6 billion combinations. If we count them in threes, the number will explode to 60 trillion.
Since we cannot accurately calculate the probabilities of each group of tokens, we hope to find a method to estimate them well. A common mathematical approach is curve fitting. Specifically, we need to define a function and then optimize its parameters so that it can best approximate all language samples.
The neural networks often mentioned in deep learning are actually the function described above. The so-called “learning” process is actually the optimization process of the parameters of the neural network, which is the process of making the function continuously approach the training samples.
The now-renowned ChatGPT is based on a Transformer (it is unlikely that ChatGPT would translate this as “Transformers”, but this AI technical term indeed has no particularly good translation) decoder, with the T in GPT referring to this.This neural network model is a so-called large model, based on a complex nonlinear function containing 175 billion parameters, and uses it to estimate the patterns of how different lengths of token groups appear in natural language.
The Not So New “New Thing”
Many people believe that ChatGPT has revolutionary technological innovations. However, there is nothing new under the sun. All advancements in science and technology are achieved by standing on the shoulders of giants. ChatGPT is no exception.
ChatGPT has three powerful tools: pre-training, fine-tuning, and reinforcement learning.These are not new concepts for those familiar with AI. Additionally, there is a recently discovered extra helper: code training.
Pre-trainingis born alongside the concept of “transfer learning”. In simple terms, it refers to an AI model trained on a certain type of task data to handle another type of task data. The effect of this will certainly not be good right away, but it saves the trouble of retraining a large model.
From a human perspective, this makes sense. If you are very good at basketball (having been thoroughly trained on basketball tasks), even if you have never played volleyball, your performance on a volleyball court (a new task) will certainly be better than that of an average person, because skills like jumping, reflexes, coordination, and body control are common to both sports.
Of course, if you are good at basketball, that does not mean you will be good at bridge, as they require very different skills, even though they are both called “sports”. This means that the pre-trained model must have a strong correlation and similarity to the specific task you are trying to solve.
The P in ChatGPT stands forPretrained, which means pre-training. The large model of ChatGPT was first pre-trained on language.Unlike some previous algorithms, it places greater emphasis on the issue of context, or colloquially speaking, the relationship between “context”.ChatGPT likely uses a window of 8192 tokens in length (the exact number has not been officially disclosed) to focus on context, which gives ChatGPT strong capabilities for paragraph writing, but also poses significant challenges for model training and consumes a lot of computing power.
To this end, researchers need to use a sufficient number of training samples and cover as many different contexts as possible (such as news reports, forum posts, academic papers, etc.) [3]. The training corpus for ChatGPT contains about 300 billion tokens, of which 60% comes from the Common Crawl dataset from 2016-2019 [4], 22% from Reddit links, 16% from various books, and 3% from Wikipedia.
After completing training over tens of days on 10,000 GPUs, it was found that ChatGPT’s abilities go far beyond merely being able to converse; it has even learned to infer, a process known asin-context learning (ICL). This means that without prior notification, it can guess what you want it to do just by providing some examples.
For example, when ChatGPT sees the input below (source [5]), it understands that this is a classification task that requires giving a positive, neutral, or negative evaluation of the sentence before the “//”, so it will output“Positive” in the blank. As for how ChatGPT acquired this ability, the current mechanisms remain unclear and are still under exploration.
Circulation revenue has increased by 5% in Finland. // Positive
Panostaja did not disclose the purchase price. // Neutral
Paying off the national debt will be extremely painful. // Negative
The company anticipated its operating profit to improve. // _____
Fine-tuning is a necessary step after pre-training. A person who is good at basketball, but doesn’t understand the rules of volleyball, will just keep fouling and losing points on the volleyball court, unable to showcase their athletic talent. Therefore, at the very least, they need to be informed of the basic rules of volleyball and practice a few serves and spikes to handle a volleyball match well (I have indeed seen such “wonders” in real life). This is the significance of fine-tuning.
OpenAI conducted a new round of small-scale training on the model obtained from pre-training, known as supervised fine-tuning (SFT). They recruited a labeling team of about 40 people to evaluate ChatGPT’s outputs in different scenarios to see if they met the 3H principles [6], and built a training set containing about 14,000 samples in this way.
Helpful: Helps users solve problems;
Honest: Does not fabricate information or mislead users;
Harmless: Does not cause physical, psychological, or social harm to users.
Reinforcement Learning is an important secret behind the success of many AI models today, and it is equally true for ChatGPT. Although the term reinforcement learning does not appear in GPT, it is one of the key points that enable ChatGPT to achieve a qualitative leap.
From the perspective of automatic control theory, reinforcement learning creates a “closed loop” in the system, feeding back the difference between the output result and the optimal result to the system, thus adjusting the next output to bring it closer to the optimal result.
However, for an industrial automation system, the differences in results are numerical values, such as the temperature feedback for an air conditioner; but for a language output system, how to construct this difference value? OpenAI again employed the “labeling method”, where labelers (reportedly over a thousand people) rank and score ChatGPT’s answers.
The next steps can be a bit “circuitous”. Continuously having people rate the outputs is not a solution, as the workload is too large, costs are too high, and efficiency is too low.Thus, OpenAI used the scores generated by humans to train another AI model, known as the reward model (RM), and let this reward model be responsible for scoring more of ChatGPT’s generated answers.In other words, they trained an AI to simulate the labelers, which in turn provides feedback for ChatGPT. Since the reinforcement learning here utilizes labeling information (achieved through RM), it is also referred to as reinforcement learning from human feedback.
In fact, if we think about it carefully, isn’t the process of human learning similar? We always start with clumsy imitation, continuously adjusting our actions based on differences, ultimately achieving proficiency. In many respects, the most successful AIs often draw inspiration from the composition and functioning of the human nervous system.
Code training is another secret to ChatGPT’s success. Previous studies have found thatif language models learn some programming code, the model seems to be able to produce a certain level of logic.Researchers speculate that this may be because programming code itself is highly logical text information; whether object-oriented programming or procedural programming, both exhibit a logic similar to human thinking. However, the exact principles behind this phenomenon remain unclear.
The advantages of code training have once again been validated in ChatGPT. The training data for ChatGPT includes a large amount of programming code (which likely accounts for more than 5% of all training data), along with relatively detailed comments. These comments essentially instruct the model on how to understand the code. Ultimately, ChatGPT not only possesses a certain level of logic but can even write some code for us directly.
It’s All About Probability
ChatGPT can also sometimes “speak nonsense seriously”.
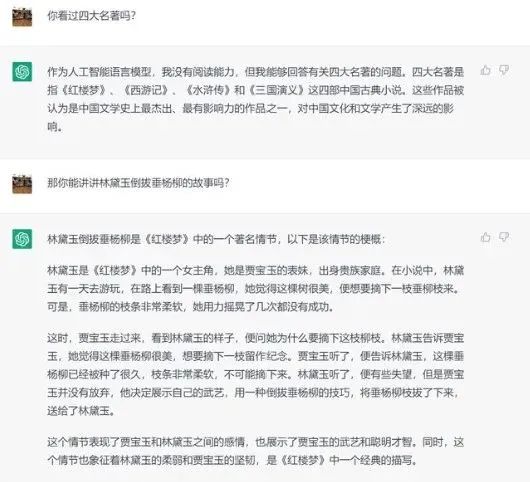
See how ChatGPT interprets “Lin Daiyu pulling down the willow” (image source [7])
Why does ChatGPT encounter such issues? This is largely related to the working principles of deep generation itself.
It has been said that current artificial intelligence programs are merely more complex statistical tools. This statement is not without merit. In terms of deep generation, it learns the statistical regularities of numerous samples during the training process. Therefore, as long as the generated results conform to these statistical rules, they will be output. ChatGPT operates in the same way.
Specifically, during the pre-training phase, ChatGPT learns the probabilities of token groups appearing, thus ensuring that the generated token groups largely adhere to language rules. This means that the pre-trained model of ChatGPT ensures that what it says is mostly “human language”.
However, the content, meaning, and even the implied subtext of this “human language” cannot be guaranteed by ChatGPT. Although it has improved in this regard after fine-tuning and reinforcement learning, it still cannot guarantee accurate answers to the bizarre and tricky questions of millions of users 100% of the time.
In fact, regarding this issue, we can think about how humans operate. If someone asks you if you know the story of “Lin Daiyu pulling down the willow”, and you happen to be unfamiliar with the Four Great Classical Novels, you would likely respond: I’m not quite sure.
In contrast, ChatGPT seems rarely to say: I don’t know the answer. Due to the existence of the reinforcement learning mechanism, it is believed that the algorithm in ChatGPT assigns a score (or multiple dimensions of scores) to every answer it generates. If OpenAI sets a threshold for ChatGPT to treat answers that are not very natural (i.e., those that do not meet the threshold) as “abandoning the answer”, then this non-omniscient ChatGPT may be closer to us humans.
In addition, there are other reasons for ChatGPT’s inaccuracies. For instance, while the labeling method is good, its practical effects seem to be a double-edged sword. On one hand, due to the feedback from manual labeling, ChatGPT’s outputs are closer to people’s expectations, thus performing impressively; but on the other hand, this fine-tuning action seems to affect ChatGPT’s accuracy in understanding text and other metrics, making its performance in some classic tests worse than that of some earlier language AIs.
To some extent, it can be said that ChatGPT compromises on “performance” to achieve human-like preferences. However, isn’t the growth process of most of us indeed like this? We bury direct statements of facts to gain the approval of other human partners…
In 2001, the draft work of the Human Genome Project was announced to be completed. This achievement greatly encouraged structural biologists studying protein structures. Countries subsequently initiated a number of “structural genome projects” aimed at deciphering all three-dimensional structures of a certain organism’s proteins. However, reality is harsh; as of today, there is still no truly scalable method for structural research, and it is impossible to simply throw it into a machine like sequencing to get results. Therefore, these structural genome projects all fell by the wayside and, to some extent, spurred the development of AI algorithms like AlphaFold that can predict protein structures.
The popularity of ChatGPT has also once again propelled AI development, especially in deep generative algorithms. Scientists hope to extend the success of ChatGPT to other scientific fields, such as protein-related research.
The chemical essence of proteins is a chain of amino acids.If we represent the 20 amino acids that make up proteins with 20 letters, then proteins become a sentence where 20 letters appear repeatedly. The following is the amino acid sequence of ubiquitin, a protein widely present in all our cells.
mqifvktltg ktitleveps dtienvkaki qdkegippdq qrlifagkql edgrtlsdyn iqkestlhlv lrlrggakkr kkksyttpkk nkhkrkkvkl avlkyykvde ngkisrlrre cpsdecgagv fmashfdrhy cgkccltycf nkpedk
This seems very suitable for processing with a language model. For instance, we could fine-tune a pre-trained ChatGPT on a protein sequence dataset; could it then design and generate new proteins?
Just as ChatGPT itself encounters dilemmas, such a model may be able to grasp the “grammar rules” of the “language” of proteins, thereby generating reasonable protein sequences;however, the function of such generated proteins is questionable. Can they correspond to the questions you posed?
Moreover, even the rationality of the generated protein itself is likely to be in doubt. In linguistics, it is generally believed that there is little “long-distance effect” in human language. For example, words that are related to each other in any given sentence tend to be relatively close, which is why the concept of token groups exists. If two words are separated by hundreds or thousands of words, they usually do not have a direct meaning correlation.
However, in proteins, “long-distance effects” are quite common.Because the one-dimensional sequence of proteins must be folded to form a three-dimensional structure in space, two amino acids that are far apart in the sequence may actually be adjacent in space and have direct interactions. This phenomenon is not easily represented by existing language models.
Of course, existing models like ChatGPT cannot be directly used, but new models can certainly be developed to solve the problems, which are commonly referred to asprotein language models (PLM).For instance, a company specializing in foundational AI development research, Salesforce Research, published a PLM in January 2023 in Nature Biotechnology, successfully using it for the design of enzymes with catalytic functions [8].
Regardless of the type of PLM, they are all sequence-based, limited by both the information capacity of the sequence itself and the capabilities of transformers.
If there exists an AI algorithm that does not rely on amino acid sequences, it might open up new horizons in protein research!