
U-Net
1. U-Net essence
Definition of U-Net
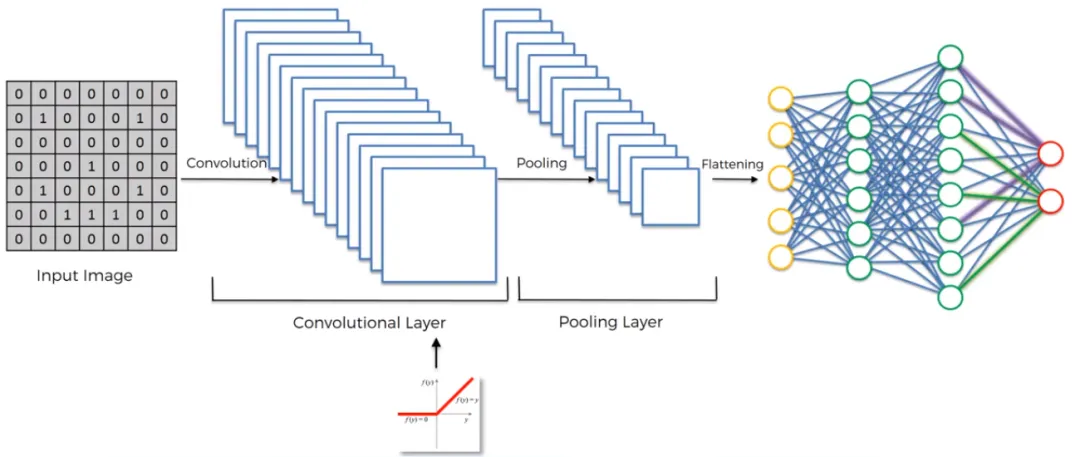
Convolutional Neural Network (CNN)
-
Application: CNNs are widely used for image classification tasks, such as recognizing object categories in images (e.g., cats, dogs, cars, etc.).
-
Output: The output of CNN is a class label for the entire image, meaning the entire image is classified into a specific category.
-
Features: Through structures like convolutional layers, pooling layers, and fully connected layers, CNNs can automatically learn features from images and use them for classification.
U-Net
-
Application: U-Net is typically used for pixel-level classification tasks in biomedical images, such as image segmentation (extracting specific structures or organs from an image).
-
Output: The output of U-Net is the class of each pixel, meaning each pixel is assigned a specific class label. These labels are usually displayed in different colors in the image to differentiate between different categories.
-
Features: U-Net uses an encoder-decoder architecture, combining feature maps from the encoder with feature maps from the decoder via skip connections to retain more spatial information and improve localization accuracy. This structure allows U-Net to perform excellently in biomedical image segmentation tasks.
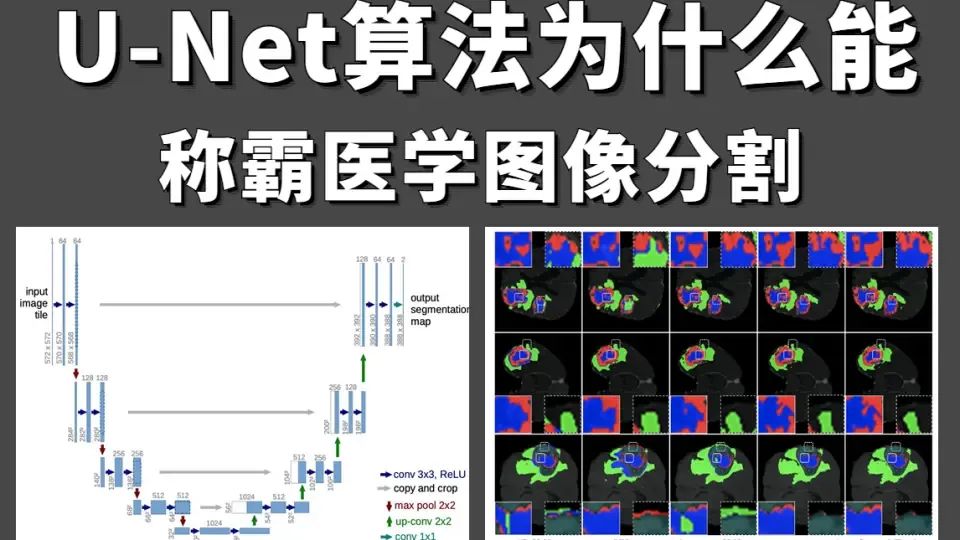
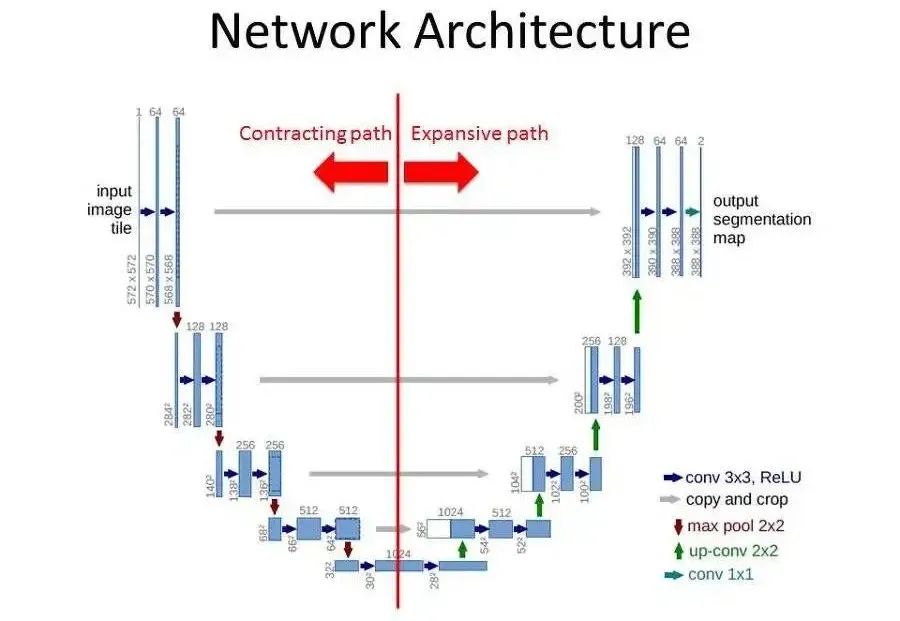
U-Net
-
Encoder: Also known as the compression path or downsampling path, it is mainly used to build deep network structures and extract deep semantic information. It includes multiple blocks, each typically consisting of a 3×3 convolution (using ReLU activation function) and a 2×2 pooling layer (downsampling) with a stride of 2. After processing by each block, the size of the feature map gradually decreases.
-
Decoder: Also known as the expansion path or upsampling path, it is symmetrical to the encoder part. It also includes multiple blocks, each performing upsampling operations to increase the size of the feature map, and then concatenating the feature map with the corresponding layer of the encoder. Finally, two 3×3 convolutions (ReLU) further process the data.
-
Skip Connection: Located between the encoder and decoder, it typically contains two 3×3 convolution layers. Its purpose is to further extract and fuse features, providing more useful information to the decoder.
-
Input and Preprocessing: Receive the image to be segmented and perform necessary preprocessing, such as normalization and resizing, to facilitate network processing.
-
Encoder (Downsampling): The image passes through a series of convolutional layers for feature extraction. Each layer contains convolution, activation functions (such as ReLU), and possible pooling operations. As the network deepens, the size of the feature map gradually decreases, while the number of feature channels gradually increases, thus extracting higher-level semantic information.
-
Decoder (Upsampling): The decoder starts from the feature map received from the encoder, gradually increasing the size of the feature map through upsampling operations (such as transposed convolution). After each upsampling step, the corresponding layer feature map of the encoder is concatenated with the current layer feature map of the decoder through skip connections.
-
Output and Image Segmentation: In the last layer of the decoder, convolution operations are used to map the feature map to the same number of channels as the number of categories. Each channel represents the probability distribution of a category in the image. Applying the softmax function or other classifiers to classify each pixel generates a segmentation result image of the same size as the input image.
-
Input and Preprocessing: Receive the image to be segmented and perform necessary preprocessing, such as normalization and resizing, to facilitate network processing.
-
Encoder (Downsampling): The image passes through a series of convolutional layers for feature extraction. Each layer contains convolution, activation functions (such as ReLU), and possible pooling operations. As the network deepens, the size of the feature map gradually decreases, while the number of feature channels gradually increases, thus extracting higher-level semantic information.
-
Decoder (Upsampling): The decoder starts from the feature map received from the encoder, gradually increasing the size of the feature map through upsampling operations (such as transposed convolution). After each upsampling step, the corresponding layer feature map of the encoder is concatenated with the current layer feature map of the decoder through skip connections.
-
Output and Image Segmentation: In the last layer of the decoder, convolution operations are used to map the feature map to the same number of channels as the number of categories. Each channel represents the probability distribution of a category in the image. Applying the softmax function or other classifiers to classify each pixel generates a segmentation result image of the same size as the input image.
-
Data Preparation: Manually mark the target area PAB and the auxiliary measurement area enamel in the training images.
-
Image Cropping: To reduce the impact of background noise on model training, crop the marked images.
-
Model Training: Train the LU-Net model using the cropped training images and marked features. LU-Net learns and extracts image features during training through skip connections.
-
Boundary Compensation: Design a compensation module to address the difficulty of determining the palatal boundary of the PAB, which is often caused by the complexity of the image or the blurriness of the boundary.
-
Segmentation Prediction: After training, the LU-Net model performs segmentation predictions on the validation and test sets, generating segmentation results for the target area.
-
Quantitative Analysis: Based on the segmentation results, construct a coordinate system using CEJ points and apical points for comprehensive quantitative analysis. This may include calculating parameters such as area, length, and angles for quantitative assessment of PAB and enamel.
-
“U-Net: Convolutional Networks for Biomedical Image Segmentation”“ -
“Intelligently Quantifying the Entire Irregular Dental Structure”
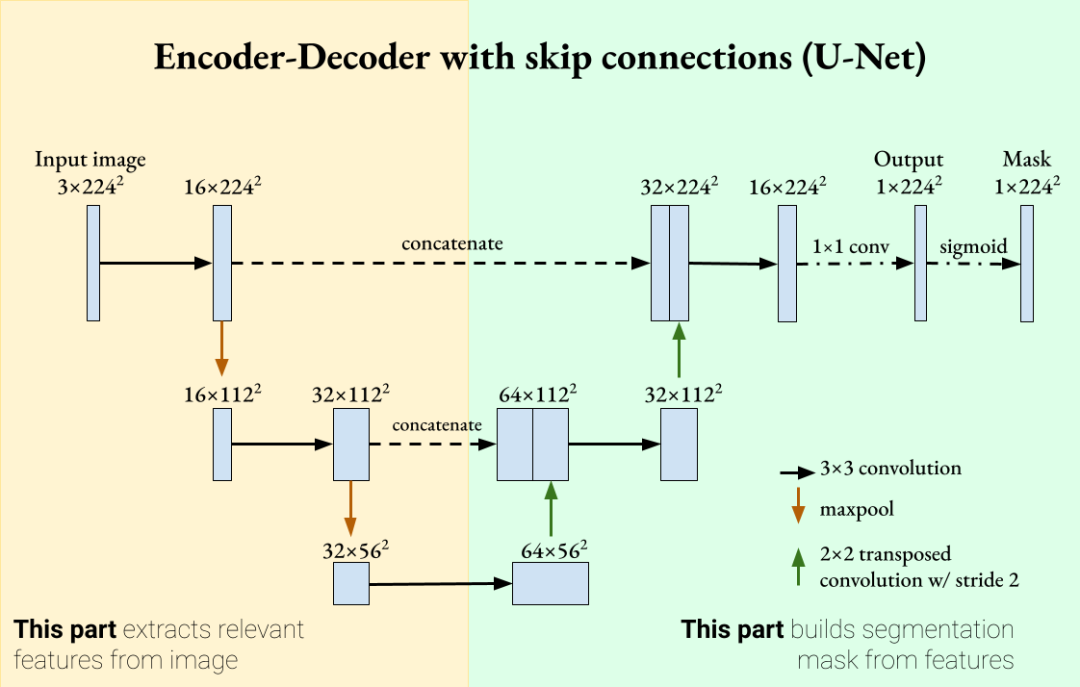
Core Components of U-Net
Workflow of U-Net: Achieves image segmentation tasks through the symmetric structure of the encoder and decoder and skip connections.
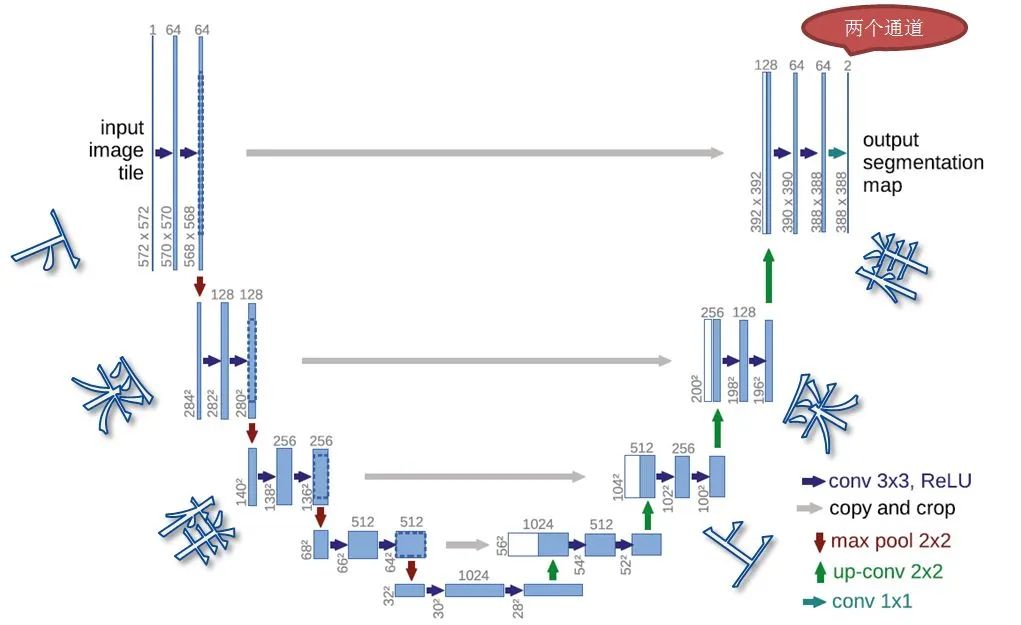
Workflow of U-Net
2. U-Net Principles

U-Net Architecture
Core Components of U-Net:: Mainly includes Encoder, Decoder two parts, fused through Skip Connection to combine low-level features from the encoder (containing more spatial information) and high-level features from the decoder (containing more semantic information).
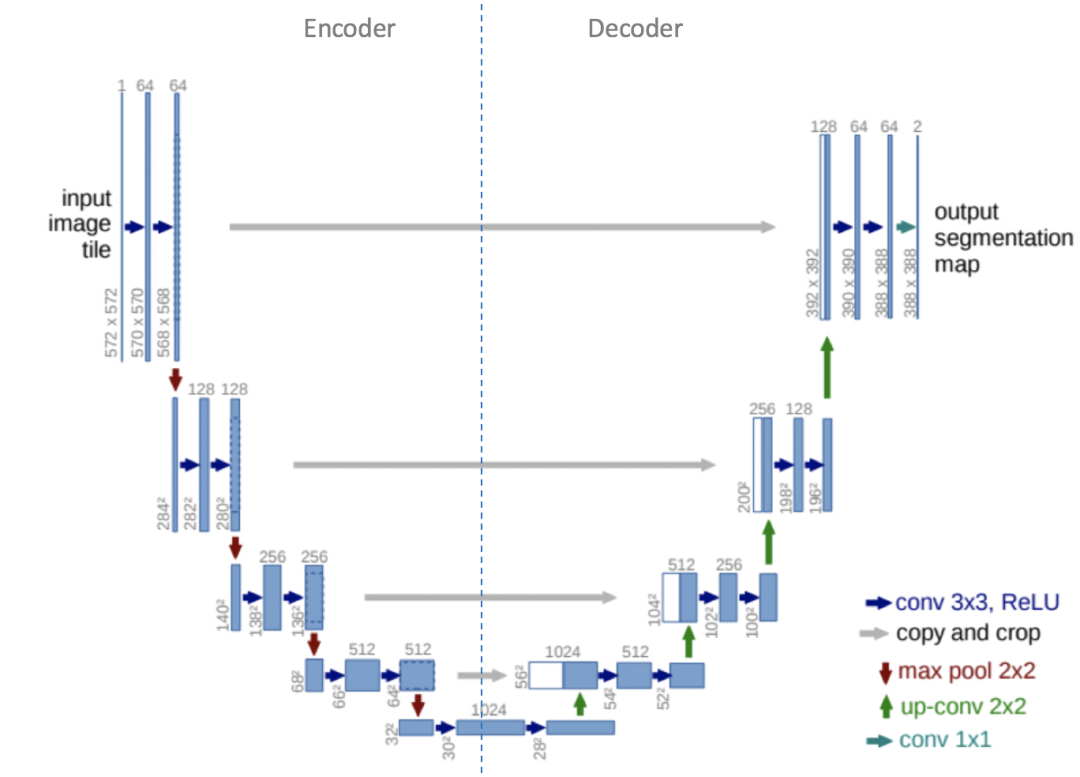
Core Components of U-Net
Workflow of U-Net: Achieves image segmentation tasks through the symmetric structure of the encoder and decoder and skip connections.
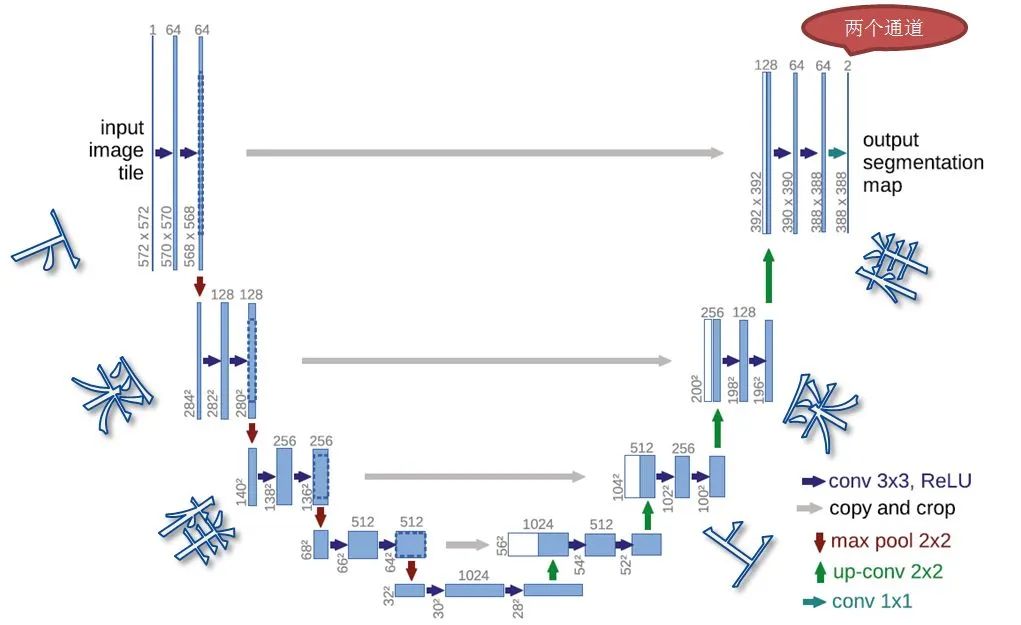
Workflow of U-Net
3. U-Net Applications
Medical Image Segmentation
The paper “Intelligently Quantifying the Entire Irregular Dental Structure” developed an AI measurement tool based on the LU-Net model, which can comprehensively quantify irregular dental structures, especially PAB, to help clinicians quickly grasp structural features and improve clinical efficiency and treatment success rates.

Intelligent Quantification of Entire Irregular Dental Structure
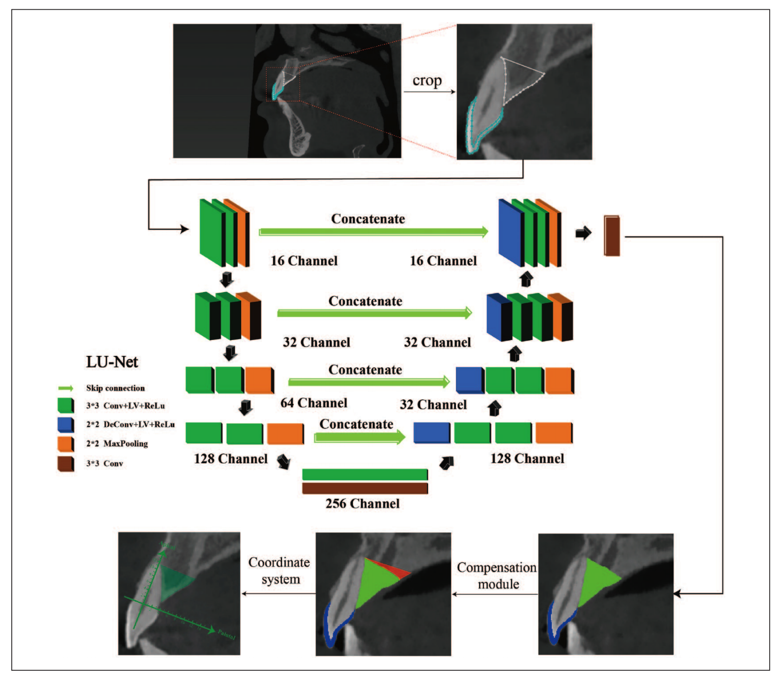
Complete Training and Application Workflow Based on LU-Net Quantitative Analysis Tool
Related Papers