
This article will coverthe essence of fine-tuningthe principles of fine-tuning, and the applications of fine-tuning in three aspects to help you understand model fine-tuning Fine-tuning .
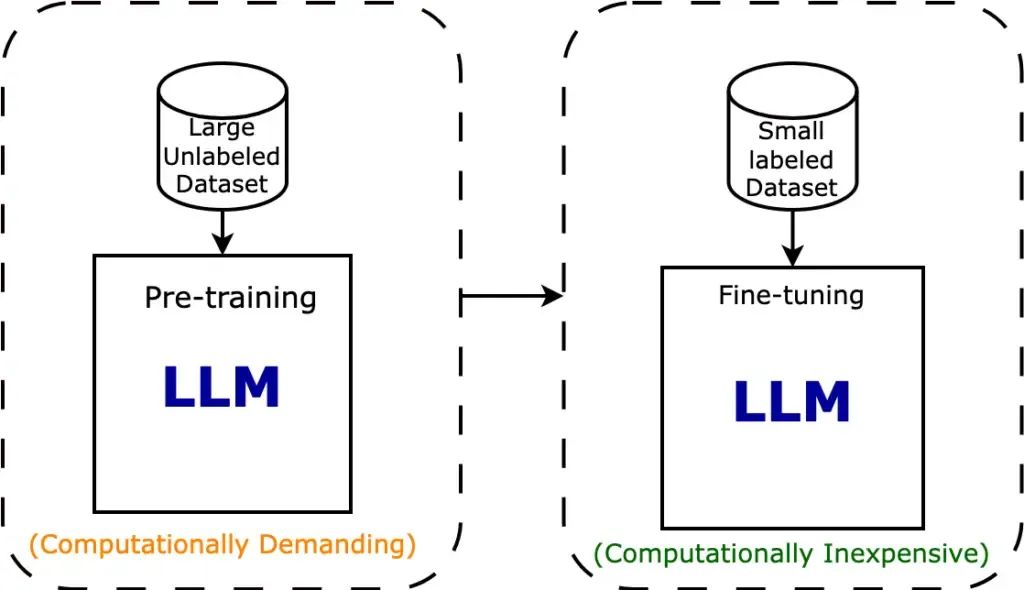
Fine-tuning Model Fine-tuning
The Essence of Fine-tuning
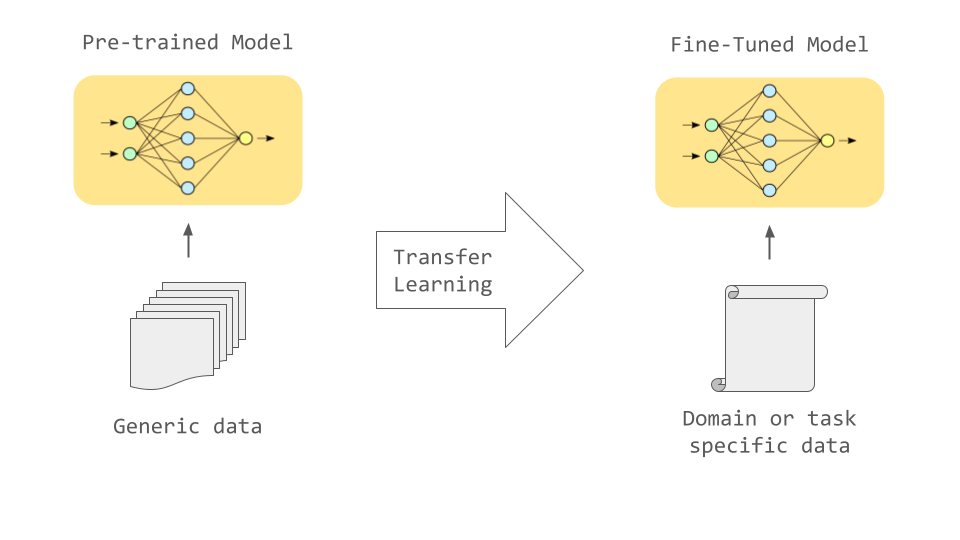
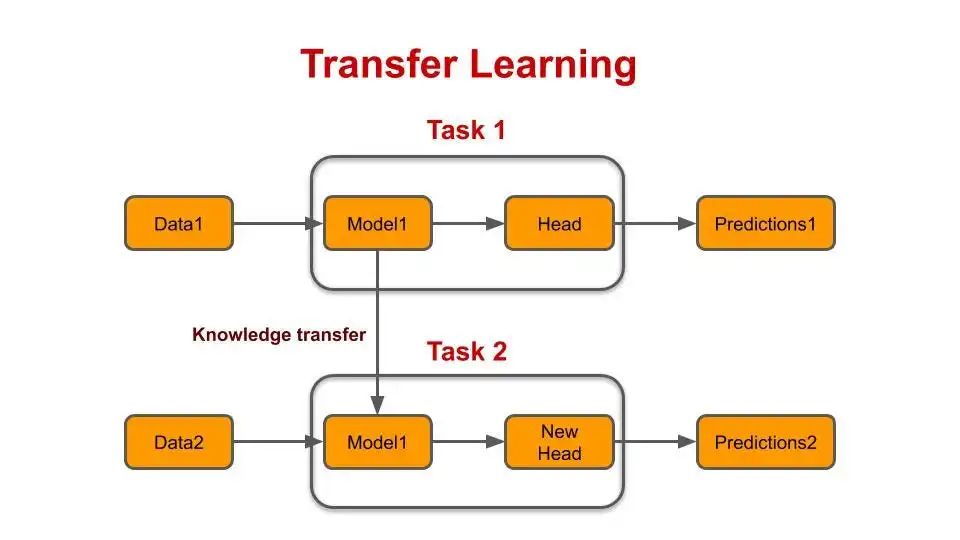
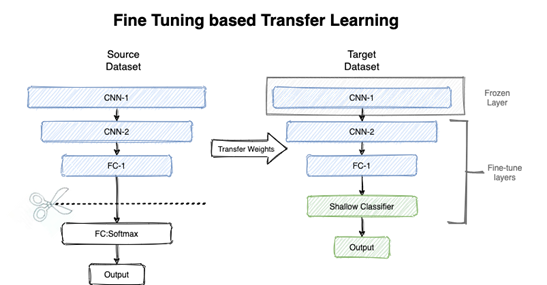
Transfer Learning
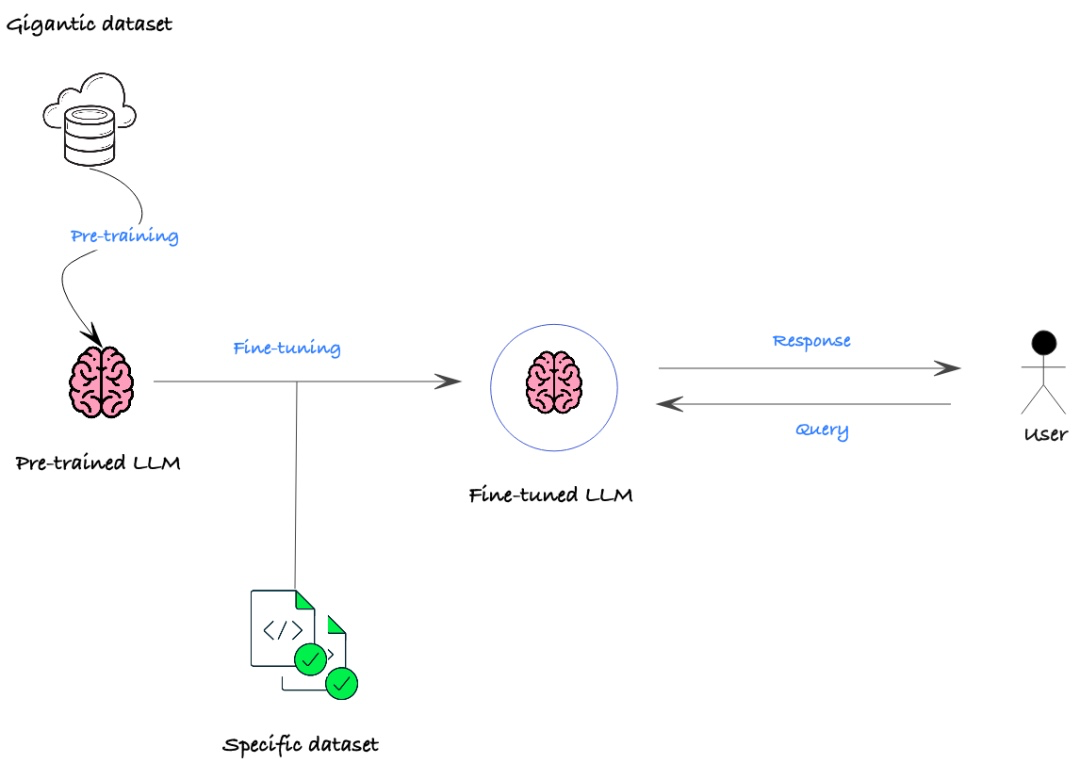
-
Reduce the need for new data:Training a large neural network from scratch typically requires a significant amount of data and computational resources, whereas in practical applications, we may only have a limited dataset. By fine-tuning a pre-trained model, we can leverage the knowledge already learned by the pre-trained model to reduce the need for new data, thus achieving better performance on small datasets.
-
Lower training costs:Since we only need to adjust a portion of the parameters of the pre-trained model rather than training the entire model from scratch, this can significantly reduce training time and the computational resources required. This makes fine-tuning a efficient and cost-effective solution, especially suitable for resource-constrained environments.
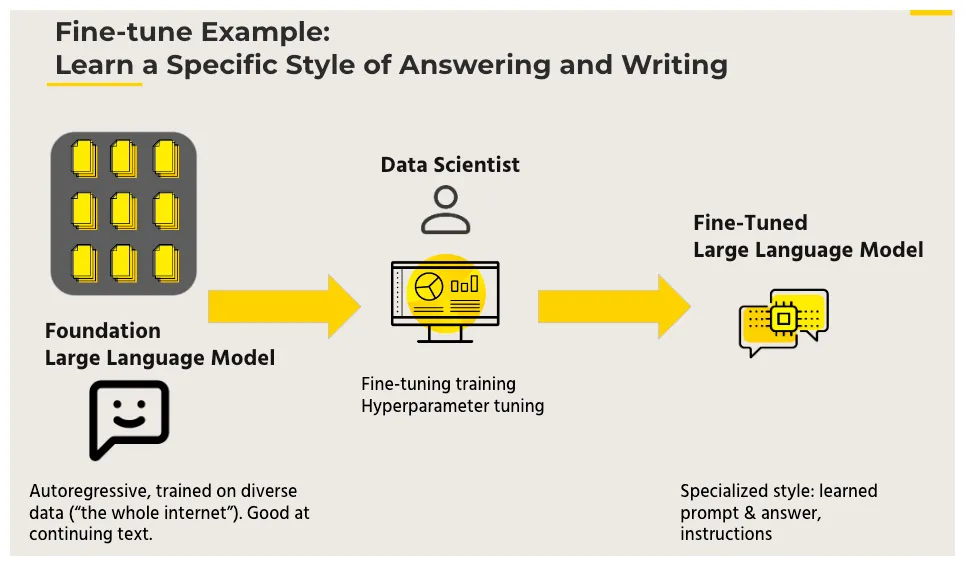
Two,The Principles of Fine-tuning
The Principles of Fine-tuning:Utilizing known network structures and known network parameters, modifying the output layer to our own layer, fine-tuning the parameters of several layers before the last layer.
This effectively leverages the powerful generalization ability of deep neural networks while avoiding the need to design complex models and time-consuming training. Therefore, Fine-tuning is a suitable choice when data volume is insufficient.

PEFT includes various techniques such as Prefix Tuning, Prompt Tuning, Adapter Tuning, and LoRA, each with its unique methods and characteristics that can be flexibly chosen based on specific task and model requirements.
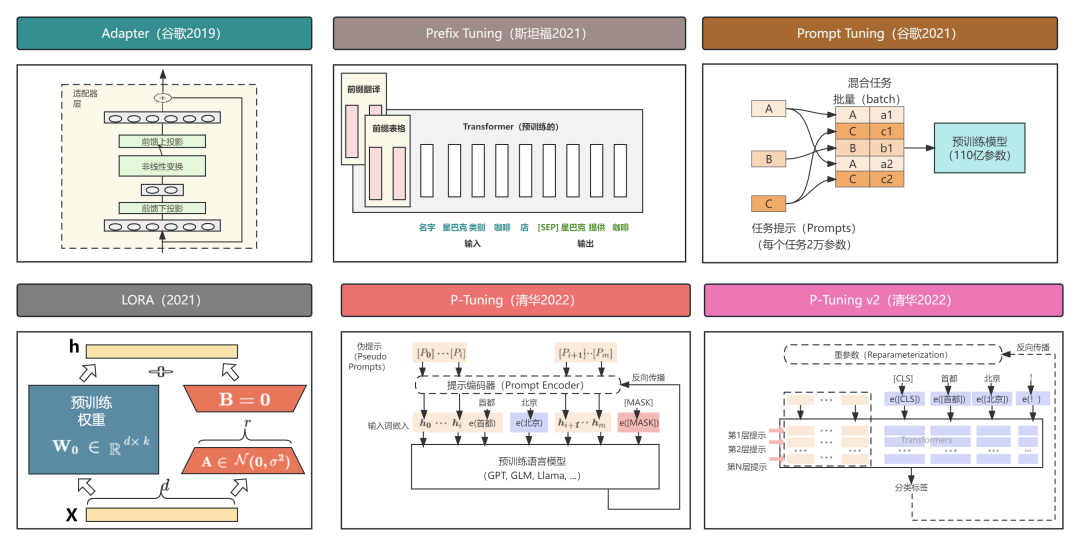
Classification of PEFT
-
Prefix Tuning: Achieved by adding learnable virtual tokens as prefixes before the model’s input. During training, only these prefix parameters are updated while the rest of the model remains unchanged.This method reduces the number of parameters to be updated, thereby improving training efficiency.

-
Prompt Tuning: Adding prompt tokens to the input layer can be seen as a simplified version of Prefix Tuning, which does not require additional multi-layer perceptron (MLP) adjustments. As the model size increases, the effectiveness of Prompt Tuning gradually approaches that of full fine-tuning.
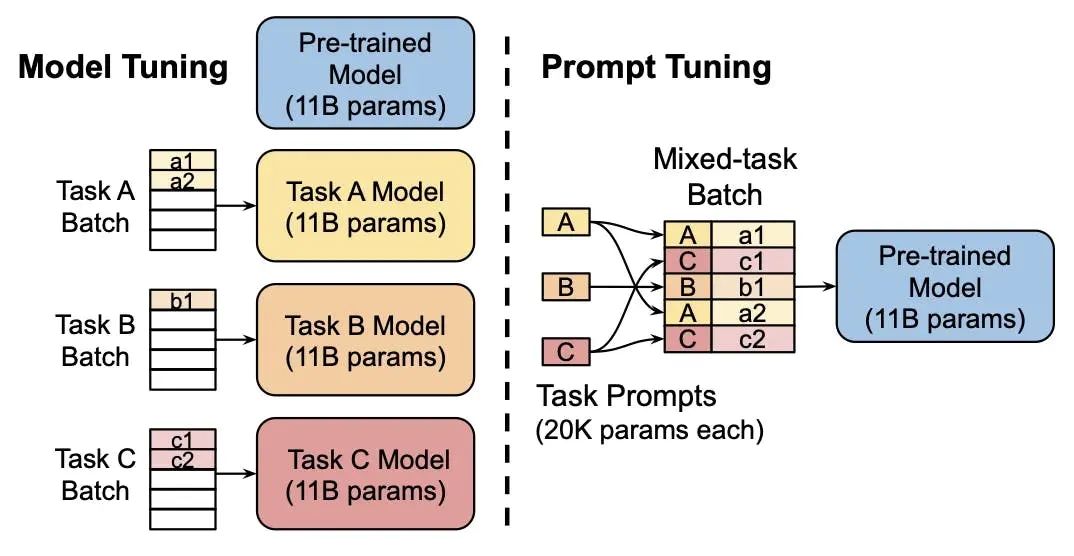
Prompt Tuning
-
Adapter Tuning: Fine-tuning is achieved by designing and embedding Adapter structures into the model. These Adapter structures are typically small network modules that can be added to specific layers of the model. During training, only these newly added Adapter structures are fine-tuned while the parameters of the original model remain unchanged. This method maintains the model’s efficiency while introducing relatively few additional parameters.
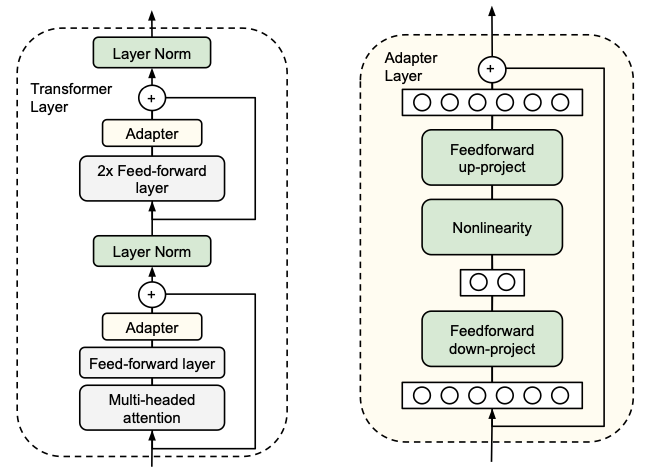
Adapter Tuning
-
LoRA (Low-Rank Adaptation): Achieved by introducing low-rank matrices into the matrix multiplication modules of the model to simulate the effects of full fine-tuning. It primarily updates the critical low-rank dimensions in the language model, achieving efficient parameter adjustments and reducing computational complexity.
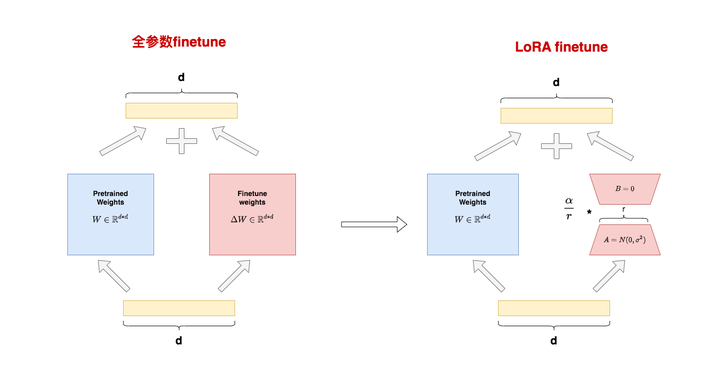
LoRA
Three, Applications of Fine-tuning
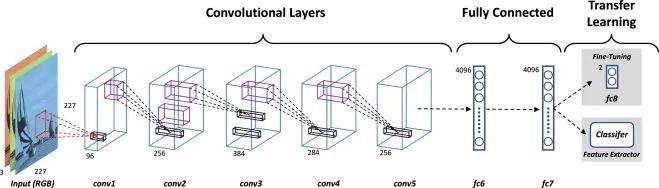
Several methods for fine-tuning CNN models:
Method 1: Modify only the last layer (fully connected layer)
-
Strategy: Keep all layers of the pre-trained CNN model unchanged except for the last layer, replacing or modifying the last fully connected layer to fit the number of categories for the new task. Depending on the needs, one can choose whether to freeze layers close to the input.
-
Effect: Quickly adapts to the classification needs of the new task while retaining the useful features learned by the pre-trained model.
Method 2: Modify the last few layers
-
Strategy: In addition to the last layer, also modify the second-to-last layer or several earlier layers to fit the feature requirements of the new task. During the modification process, one can choose whether to freeze certain layers as needed.
-
Effect: Enables the model to learn more features relevant to the new task, improving performance on the new task. However, care must be taken to avoid the risk of overfitting.
Method 3: Fine-tune the entire model
-
Strategy: Update the parameters of all layers of the pre-trained model to meet the requirements of the new task. During the fine-tuning process, one can choose whether to freeze certain layers as needed to balance the need for learning new features and retaining useful features.
-
Effect: Enables the model to achieve better performance on the new task, but requires more computational resources and time, and is prone to overfitting.
Fine-tuning Transformer block with adapters: A parameter-efficient fine-tuning technique that adds additional adapters or residual blocks to the backbone network of the pre-trained Transformer model to achieve fine-tuning for specific tasks.These adapters are typically trainable parameters, while the other parts of the model remain fixed.

Fine-tuning methods for Transformer block with adapters typically include the following steps:
-
Load the pre-trained model: First, load a Transformer model that has been pre-trained on a large corpus.
-
Add adapters: Add adapters for each Transformer layer in the backbone network of the model.These adapters can be simple linear layers or more complex structures, depending on the task requirements.
-
Initialize adapter parameters: Set initial parameters for the added adapters. These parameters are typically randomly initialized or can use other initialization strategies.
-
Fine-tune: Fine-tune the model using a specific task dataset. During fine-tuning, only the parameters of the adapters are updated while keeping the other parts of the model unchanged.
-
Evaluate performance: After fine-tuning, evaluate the model’s performance using a validation set. Based on the evaluation results, further adjustments can be made to the structure or parameters of the adapters to optimize the model’s performance.