

Reprinted from | PaperWeekly©PaperWeekly Original · Author | SherlockSchool | Suzhou University of Science and Technology undergraduateResearch Direction | Natural Language Processing

Word Embedding
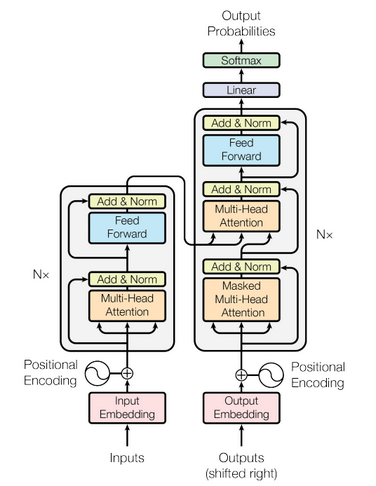
The Transformer is essentially an Encoder. Taking the translation task as an example, the original dataset consists of a line composed of two languages. During application, the Encoder inputs the source language sequence, and the Decoder inputs the language sequence that needs to be converted (during training).
A text typically consists of many sequences, and common operations involve preprocessing the sequences (e.g., word segmentation) into lists. The elements of a sequence list are usually the smallest indivisible words in the vocabulary, and the entire text is a large list composed of lists of sequences.
For example, a sequence after segmentation becomes [“am”, “##ro”, “##zi”, “accused”, “his”, “father”]. Next, they are converted according to their corresponding indices in the vocabulary, assuming the result is [23, 94, 13, 41, 27, 96]. If the entire text has 100 sentences, there will be 100 lists as its elements. Since the lengths of each sequence vary, a maximum length must be set; let’s say it is 128. Therefore, after converting the entire text into an array, the shape will be 100 x 128, which corresponds to batch_size and seq_length.
After inputting, the next step is to perform word embedding processing. Word embedding maps each word using pre-trained vectors, with parameters for the vocabulary size and the dimensionality of the mapped vectors. In simple terms, it refers to how many numbers are in the vector. Note that the first parameter is the vocabulary size. If you currently have 4 words, you set it to 4. If you later encounter words different from these 4, you need to remap them. To unify, the initial ones also need to be remapped, so here you fill in the total vocabulary size.
If we intend to map to a 512-dimensional space (num_features or embed_dim), then the shape of the entire text becomes 100 x 128 x 512. To illustrate with a small example: suppose our vocabulary has a total of 10 words, and the text has 2 sentences, each containing 4 words. We want to map each word to an 8-dimensional vector. Thus, 2, 4, 8 correspond to batch_size, seq_length, embed_dim (if batch is in the first dimension).
Moreover, in general deep learning tasks, only num_features changes, so the dimension typically refers to the last feature dimension.
Importing all required packages:
import torch
import torch.nn as nn
from torch.nn.parameter import Parameter
from torch.nn.init import xavier_uniform_
from torch.nn.init import constant_
from torch.nn.init import xavier_normal_
import torch.nn.functional as F
from typing import Optional, Tuple, Any
from typing import List, Optional, Tuple
import math
import warnings
X = torch.zeros((2,4),dtype=torch.long)
embed = nn.Embedding(10,8)
print(embed(X).shape)
# torch.Size([2, 4, 8])

Positional Encoding
Following word embedding is positional encoding, which is used to differentiate the relationships between different words and the same words with different features. In the code, note that X_ is just the initialized matrix, not the input; after completing positional encoding, a dropout will be added. Furthermore, positional encoding is added last, so the input-output shape remains unchanged.
Tensor = torch.Tensor
def positional_encoding(X, num_features, dropout_p=0.1, max_len=512) -> Tensor:
r'''
Add positional encoding to the input
Parameters:
- num_features: The dimension of the input
- dropout_p: The probability of dropout, applied when non-zero
- max_len: The maximum length of sentences, default is 512
Shape:
- Input: [batch_size, seq_length, num_features]
- Output: [batch_size, seq_length, num_features]
Example:
>>> X = torch.randn((2,4,10))
>>> X = positional_encoding(X, 10)
>>> print(X.shape)
>>> torch.Size([2, 4, 10])
'''
dropout = nn.Dropout(dropout_p)
P = torch.zeros((1,max_len,num_features))
X_ = torch.arange(max_len,dtype=torch.float32).reshape(-1,1) / torch.pow(
10000,
torch.arange(0,num_features,2,dtype=torch.float32) /num_features)
P[:,:,0::2] = torch.sin(X_)
P[:,:,1::2] = torch.cos(X_)
X = X + P[:,:X.shape[1],:].to(X.device)
return dropout(X)

Multi-Head Attention
Multi-head attention can be roughly divided into three parts: parameter initialization, where q, k, v come from, masking mechanism, and dot-product attention.
3.1 Parameter InitializationQuery, key, and value are obtained by multiplying the source language sequence (referred to as src in this article) by the corresponding matrices. So where do those matrices come from (note that most of the code is extracted from the source code and often contains self, etc., so it will present a composed form without showing the entire structure in the text):
if self._qkv_same_embed_dim is False:
# Keep the shape unchanged before and after initialization
# (seq_length x embed_dim) x (embed_dim x embed_dim) -> (seq_length x embed_dim)
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim)))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim)))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim)))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
else:
self.register_parameter('in_proj_bias', None)
# Later, all heads' attention will be concatenated and multiplied by the weight matrix for output
# out_proj is prepared for later
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self._reset_parameters()
torch.empty creates a tensor with the given shape, filled with uninitialized values, similar to torch.randn (standard normal distribution). In PyTorch, if a variable is of type tensor, its value cannot be modified, while the Parameter() function can be seen as a type conversion function that converts an immutable tensor into a trainable and modifiable model parameter, binding it to model.parameters. register_parameter means whether to include this parameter in model.parameters, with None indicating the absence of this parameter.There is an if statement here to determine whether the last dimension of q, k, v is consistent. If they are consistent, a large weight matrix is multiplied, and then split out; if not, each is initialized separately. Initialization does not change the original shape (as seen in the comments).
It can be observed that there is a _reset_parameters() function at the end, which is used to initialize parameter values. xavier_uniform means randomly sampling values from a continuous uniform distribution as the initialization value, while xavier_normal_ samples from a normal distribution. Since the initialization values are crucial when training neural networks, these two functions are necessary.
constant_ means filling the input vector with the given value.
Additionally, in PyTorch’s source code, projection typically refers to a linear transformation, and in_proj_bias means the initial linear transformation bias.
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
The above is the parameter initialization process, and the next step is to assign values to query, key, and value.
3.2 Where Do q, k, v Come From?
For the nn.functional.linear function, it is essentially a linear transformation. Unlike nn.Linear, the former can provide weight matrices and biases, while the latter allows for free determination of output dimensions. Since the linear function is called multiple times with little significance, it is omitted here.
def _in_projection_packed(
q: Tensor,
k: Tensor,
v: Tensor,
w: Tensor,
b: Optional[Tensor] = None,
) -> List[Tensor]:
r"""
Perform a linear transformation using a large weight parameter matrix
Parameters:
q, k, v: For self-attention, all three are src; for seq2seq models, k and v are the same tensor.
However, their last dimension (num_features or embed_dim) must remain consistent.
w: The large matrix used for linear transformation, stacked in order of q, k, v in one tensor.
b: The bias for linear transformation, stacked in order of q, k, v in one tensor.
Shape:
Input:
- q: shape:`(..., E)`, E is the dimension of the word embedding (this is the meaning of E below).
- k: shape:`(..., E)`
- v: shape:`(..., E)`
- w: shape:`(E * 3, E)`
- b: shape:`E * 3`
Output:
- Output list :`[q', k', v']`, the shapes of q, k, v after linear transformation are consistent.
"""
E = q.size(-1)
# If self-attention, q = k = v = src, so their reference variables are all src
# i.e., k is v and q is k results are both True
# For seq2seq, k = v, hence k is v results as True
if k is v:
if q is k:
return F.linear(q, w, b).chunk(3, dim=-1)
else:
# seq2seq model
w_q, w_kv = w.split([E, E * 2])
if b is None:
b_q = b_kv = None
else:
b_q, b_kv = b.split([E, E * 2])
return (F.linear(q, w_q, b_q),) + F.linear(k, w_kv, b_kv).chunk(2, dim=-1)
else:
w_q, w_k, w_v = w.chunk(3)
if b is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = b.chunk(3)
return F.linear(q, w_q, b_q), F.linear(k, w_k, b_k), F.linear(v, w_v, b_v)
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
3.3 Masking Mechanism
For attn_mask, if it is 2D, the shape is like (L, S), where L and S represent the lengths of the target language and source language sequences, respectively. If it is 3D, the shape is like (N * num_heads, L, S), where N represents batch_size, and num_heads represents the number of attention heads. If it is a ByteTensor, non-zero positions will be ignored for attention; if it is a BoolTensor, True positions will be ignored; if it is numeric, it will be directly added to attn_weights.
Because during decoding in the decoder, it can only look at that position and the ones before it; if it looks at the ones after, it would be against the rules, so the attn_mask needs to mask it.
The following function is directly copied from PyTorch, meaning it ensures the shapes of masks of different dimensions are correct and the conversions of different types.
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {attn_mask.dtype}"
# Shape determination for different dimensions
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
Unlike attn_mask, key_padding_mask is used to mask values in the key, specifically <PAD>, and the conditions for being ignored are the same as for attn_mask.
# Change key_padding_mask values to boolean
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
Next, two small functions are introduced: logical_or, which takes two tensors as input and performs a logical or operation on the values in these two tensors, such that only when both values are 0 is it False; otherwise, it is True. The other is masked_fill, which takes a mask and a value to fill. The mask consists of 1s and 0s, where the values at 0 positions remain unchanged, and at 1 positions are filled with the new value.
a = torch.tensor([0,1,10,0],dtype=torch.int8)
b = torch.tensor([4,0,1,0],dtype=torch.int8)
print(torch.logical_or(a,b))
# tensor([ True, True, True, False])
r = torch.tensor([[0,0,0,0],[0,0,0,0]])
mask = torch.tensor([[1,1,1,1],[0,0,0,0]])
print(r.masked_fill(mask,1))
# tensor([[1, 1, 1, 1],
# [0, 0, 0, 0]])
In fact, attn_mask and key_padding_mask are sometimes equivalent, so they can be viewed together. -inf will yield 0 after softmax, meaning it will be ignored.
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
# If attn_mask is empty, directly use key_padding_mask
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# If attn_mask is boolean, convert mask to float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
3.4 Dot-Product Attention
from typing import Optional, Tuple, Any
def scaled_dot_product_attention(
q: Tensor,
k: Tensor,
v: Tensor,
attn_mask: Optional[Tensor] = None,
dropout_p: float = 0.0,
) -> Tuple[Tensor, Tensor]:
r'''
Calculate dot-product attention on query, key, value, using attention mask if available, and apply dropout with probability dropout_p
Parameters:
- q: shape:`(B, Nt, E)` B represents batch size, Nt is target language sequence length, E is the dimension of the embedded features
- key: shape:`(B, Ns, E)` Ns is the source language sequence length
- value: shape:`(B, Ns, E)` has the same shape as key
- attn_mask: either a 3D tensor with shape:`(B, Nt, Ns)` or a 2D tensor with shape like:`(Nt, Ns)`
- Output: attention values: shape:`(B, Nt, E)`, consistent with q's shape; attention weights: shape:`(B, Nt, Ns)`
Example:
>>> q = torch.randn((2,3,6))
>>> k = torch.randn((2,4,6))
>>> v = torch.randn((2,4,6))
>>> out = scaled_dot_product_attention(q, k, v)
>>> out[0].shape, out[1].shape
>>> torch.Size([2, 3, 6]) torch.Size([2, 3, 4])
'''
B, Nt, E = q.shape
q = q / math.sqrt(E)
# (B, Nt, E) x (B, E, Ns) -> (B, Nt, Ns)
attn = torch.bmm(q, k.transpose(-2,-1))
if attn_mask is not None:
attn += attn_mask
# attn means each word in the target sequence pays attention to the source language sequence
attn = F.softmax(attn, dim=-1)
if dropout_p:
attn = F.dropout(attn, p=dropout_p)
# (B, Nt, Ns) x (B, Ns, E) -> (B, Nt, E)
output = torch.bmm(attn, v)
return output, attn
Next, let’s connect the three parts:
def multi_head_attention_forward(
query: Tensor,
key: Tensor,
value: Tensor,
num_heads: int,
in_proj_weight: Tensor,
in_proj_bias: Optional[Tensor],
dropout_p: float,
out_proj_weight: Tensor,
out_proj_bias: Optional[Tensor],
training: bool = True,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
use_seperate_proj_weight = None,
q_proj_weight: Optional[Tensor] = None,
k_proj_weight: Optional[Tensor] = None,
v_proj_weight: Optional[Tensor] = None,
) -> Tuple[Tensor, Optional[Tensor]]:
r'''
Shape:
Input:
- query:`(L, N, E)`
- key: `(S, N, E)`
- value: `(S, N, E)`
- key_padding_mask: `(N, S)`
- attn_mask: `(L, S)` or `(N * num_heads, L, S)`
Output:
- attn_output:`(L, N, E)`
- attn_output_weights:`(N, L, S)`
'''
tgt_len, bsz, embed_dim = query.shape
src_len, _, _ = key.shape
head_dim = embed_dim // num_heads
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {attn_mask.dtype}"
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
# Reshape q,k,v to fit dot-product attention by placing Batch in the first dimension
# Simultaneously for multi-head mechanism, different heads are concatenated together to form a layer
q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
k = k.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
v = v.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# If attn_mask is boolean, convert mask to float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
# Only apply dropout if training is True
if not training:
dropout_p = 0.0
attn_output, attn_output_weights = _scaled_dot_product_attention(q, k, v, attn_mask, dropout_p)
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
if need_weights:
# Average attention weights over heads
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
return attn_output, attn_output_weights.sum(dim=1) / num_heads
else:
return attn_output, None
Next, let’s construct the MultiheadAttention class:
class MultiheadAttention(nn.Module):
r'''
Parameters:
embed_dim: The dimension of the word embedding
num_heads: The number of parallel heads in multi-head attention
batch_first: If `True`, it is (batch, seq, feature); if `False`, it is (seq, batch, feature)
Example:
>>> multihead_attn = MultiheadAttention(embed_dim, num_heads)
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
'''
def __init__(self, embed_dim, num_heads, dropout=0., bias=True,
kdim=None, vdim=None, batch_first=False) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(MultiheadAttention, self).__init__()
self.embed_dim = embed_dim
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.batch_first = batch_first
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
if self._qkv_same_embed_dim is False:
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim)))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim)))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim)))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
else:
self.register_parameter('in_proj_bias', None)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self._reset_parameters()
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
if self.bias_k is not None:
xavier_normal_(self.bias_k)
if self.bias_v is not None:
xavier_normal_(self.bias_v)
def forward(self, query: Tensor, key: Tensor, value: Tensor, key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True, attn_mask: Optional[Tensor] = None) -> Tuple[Tensor, Optional[Tensor]]:
if self.batch_first:
query, key, value = [x.transpose(1, 0) for x in (query, key, value)]
if not self._qkv_same_embed_dim:
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight)
else:
attn_output, attn_output_weights = F.multi_head_attention_forward(
query, key, value, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask)
if self.batch_first:
return attn_output.transpose(1, 0), attn_output_weights
else:
return attn_output, attn_output_weights
Next, we can practice a bit and add positional encoding, and we can see that adding positional encoding and performing multi-head attention does not change the shapes.
# Since batch_first is False, the shape of src is:`(seq, batch, embed_dim)`
src = torch.randn((2,4,100))
src = positional_encoding(src,100,0.1)
print(src.shape)
multihead_attn = MultiheadAttention(100, 4, 0.1)
attn_output, attn_output_weights = multihead_attn(src,src,src)
print(attn_output.shape, attn_output_weights.shape)
# torch.Size([2, 4, 100])
# torch.Size([2, 4, 100]) torch.Size([4, 2, 2])

Building the Transformer
4.1 Encoder Layer
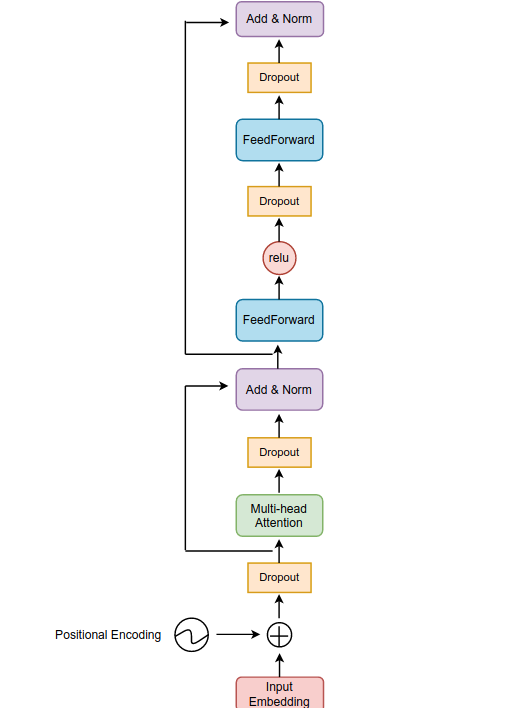
class TransformerEncoderLayer(nn.Module):
r'''
Parameters:
d_model: The dimension of the word embedding (required)
nhead: The number of parallel heads in multi-head attention (required)
dim_feedforward: The number of neurons in the fully connected layer, also known as the dimension of input through this layer (Default = 2048)
dropout: The probability of dropout (Default = 0.1)
activation: The activation function between two linear layers, default is relu or gelu
lay_norm_eps: A small value in layer normalization to prevent division by zero (Default = 1e-5)
batch_first: If `True`, it is (batch, seq, feature); if `False`, it is (seq, batch, feature) (Default: False)
Example:
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
>>> src = torch.randn((32, 10, 512))
>>> out = encoder_layer(src)
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False) -> None:
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = activation
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
src = positional_encoding(src, src.shape[-1])
src2 = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout(src2)
src = self.norm2(src)
return src
Let’s see a small example:
encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
src = torch.randn((32, 10, 512))
out = encoder_layer(src)
print(out.shape)
# torch.Size([32, 10, 512])
4.2 Encoder
class TransformerEncoder(nn.Module):
r'''
Parameters:
encoder_layer (required)
num_layers: The number of encoder layers (required)
norm: The choice of normalization (optional)
Example:
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
>>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
>>> src = torch.randn((10, 32, 512))
>>> out = transformer_encoder(src)
'''
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layer = encoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, src: Tensor, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = positional_encoding(src, src.shape[-1])
for _ in range(self.num_layers):
output = self.layer(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
Let’s see a small example:
encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
src = torch.randn((10, 32, 512))
out = transformer_encoder(src)
print(out.shape)
# torch.Size([10, 32, 512])
4.3 Decoder Layer:
class TransformerDecoderLayer(nn.Module):
r'''
Parameters:
d_model: The dimension of the word embedding (required)
nhead: The number of parallel heads in multi-head attention (required)
dim_feedforward: The number of neurons in the fully connected layer, also known as the dimension of input through this layer (Default = 2048)
dropout: The probability of dropout (Default = 0.1)
activation: The activation function between two linear layers, default is relu or gelu
lay_norm_eps: A small value in layer normalization to prevent division by zero (Default = 1e-5)
batch_first: If `True`, it is (batch, seq, feature); if `False`, it is (seq, batch, feature) (Default: False)
Example:
>>> decoder_layer = TransformerDecoderLayer(d_model=512, nhead=8)
>>> memory = torch.randn((10, 32, 512))
>>> tgt = torch.randn((20, 32, 512))
>>> out = decoder_layer(tgt, memory)
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False) -> None:
super(TransformerDecoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm3 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = activation
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
Parameters:
tgt: Target language sequence (required)
memory: The sentence output from the last encoder layer (required)
tgt_mask: Mask for the target language sequence (optional)
memory_mask (optional)
tgt_key_padding_mask (optional)
memory_key_padding_mask (optional)
'''
tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(tgt, memory, memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
Let’s see a small example:
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
memory = torch.randn((10, 32, 512))
tgt = torch.randn((20, 32, 512))
out = decoder_layer(tgt, memory)
print(out.shape)
# torch.Size([20, 32, 512])
4.4 Decoder
class TransformerDecoder(nn.Module):
r'''
Parameters:
decoder_layer (required)
num_layers: The number of decoder layers (required)
norm: The choice of normalization
Example:
>>> decoder_layer =TransformerDecoderLayer(d_model=512, nhead=8)
>>> transformer_decoder = TransformerDecoder(decoder_layer, num_layers=6)
>>> memory = torch.rand(10, 32, 512)
>>> tgt = torch.rand(20, 32, 512)
>>> out = transformer_decoder(tgt, memory)
'''
def __init__(self, decoder_layer, num_layers, norm=None):
super(TransformerDecoder, self).__init__()
self.layer = decoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = tgt
for _ in range(self.num_layers):
output = self.layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
Let’s see a small example:
decoder_layer =TransformerDecoderLayer(d_model=512, nhead=8)
transformer_decoder = TransformerDecoder(decoder_layer, num_layers=6)
memory = torch.rand(10, 32, 512)
tgt = torch.rand(20, 32, 512)
out = transformer_decoder(tgt, memory)
print(out.shape)
# torch.Size([20, 32, 512])
In summary, after positional encoding, multi-head attention, Encoder Layer, and Decoder Layer, the shapes remain unchanged, while the Encoder and Decoder match the shapes of src and tgt, respectively.
4.5 Transformer
class Transformer(nn.Module):
r'''
Parameters:
d_model: The dimension of the word embedding (required) (Default=512)
nhead: The number of parallel heads in multi-head attention (required) (Default=8)
num_encoder_layers: Number of encoder layers (Default=8)
num_decoder_layers: Number of decoder layers (Default=8)
dim_feedforward: The number of neurons in the fully connected layer, also known as the dimension of input through this layer (Default = 2048)
dropout: The probability of dropout (Default = 0.1)
activation: The activation function between two linear layers, default is relu or gelu
custom_encoder: Custom encoder (Default=None)
custom_decoder: Custom decoder (Default=None)
lay_norm_eps: A small value in layer normalization to prevent division by zero (Default = 1e-5)
batch_first: If `True`, it is (batch, seq, feature); if `False`, it is (seq, batch, feature) (Default: False)
Example:
>>> transformer_model = Transformer(nhead=16, num_encoder_layers=12)
>>> src = torch.rand((10, 32, 512))
>>> tgt = torch.rand((20, 32, 512))
>>> out = transformer_model(src, tgt)
'''
def __init__(self, d_model: int = 512, nhead: int = 8, num_encoder_layers: int = 6,
num_decoder_layers: int = 6, dim_feedforward: int = 2048, dropout: float = 0.1,
activation = F.relu, custom_encoder: Optional[Any] = None, custom_decoder: Optional[Any] = None,
layer_norm_eps: float = 1e-5, batch_first: bool = False) -> None:
super(Transformer, self).__init__()
if custom_encoder is not None:
self.encoder = custom_encoder
else:
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
encoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers)
if custom_decoder is not None:
self.decoder = custom_decoder
else:
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
decoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
self.batch_first = batch_first
def forward(self, src: Tensor, tgt: Tensor, src_mask: Optional[Tensor] = None, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
Parameters:
src: Source language sequence (sent to Encoder) (required)
tgt: Target language sequence (sent to Decoder) (required)
src_mask: (optional)
tgt_mask: (optional)
memory_mask: (optional)
src_key_padding_mask: (optional)
tgt_key_padding_mask: (optional)
memory_key_padding_mask: (optional)
Shape:
- src: shape:`(S, N, E)`, `(N, S, E)` if batch_first.
- tgt: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
- src_mask: shape:`(S, S)`.
- tgt_mask: shape:`(T, T)`.
- memory_mask: shape:`(T, S)`.
- src_key_padding_mask: shape:`(N, S)`.
- tgt_key_padding_mask: shape:`(N, T)`.
- memory_key_padding_mask: shape:`(N, S)`.
[src/tgt/memory]_mask ensures that some positions are not visible, e.g., during decoding, it can only see the current position and those before it, and not the ones after.
If it's a ByteTensor, non-zero positions will be ignored for attention; if it's a BoolTensor, True positions will be ignored;
if it's numeric, it will be directly added to attn_weights
[src/tgt/memory]_key_padding_mask makes certain elements in the key not participate in the attention calculation, with the same three conditions as above.
- output: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
Note:
The last dimension of src and tgt must equal d_model, and the batch dimension must be equal
Example:
>>> output = transformer_model(src, tgt, src_mask=src_mask, tgt_mask=tgt_mask)
'''
memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
return output
def generate_square_subsequent_mask(self, sz: int) -> Tensor:
r'''Generate a mask for the sequence, assigning `-inf` to masked areas and `0` to unmasked areas'''
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def _reset_parameters(self):
r'''Initialize parameters using a normal distribution'''
for p in self.parameters():
if p.dim() > 1:
xavier_uniform_(p)
Let’s test it with a small example:
transformer_model = Transformer(nhead=16, num_encoder_layers=12)
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)
print(out.shape)
# torch.Size([20, 32, 512])
So far, I have fully implemented the PyTorch Transformer library. Compared to the official version, my handwritten version has fewer conditional statements, so when using it, please ensure you have read my tutorial to understand the basic inputs and outputs. Some unnecessary calls and packaging have been omitted, and some unnecessary functions have been completely rewritten.
Additionally, all code has been tested. If there are issues, it is certainly your problem. Full code:
https://github.com/sherlcok314159/ML/blob/main/nlp/models/functions.py
Recommended Reading:
Visual Enhancement Word Vectors: I Am Word Vectors, I Opened My Eyes!
Transformers Have Grown Up, What About Their Siblings? (Including Ultra-Detailed Knowledge Points on Transformers)
ERICA: A Unified Framework for Enhancing Entity and Relationship Understanding in Pre-trained Language Models
Click on the card below to follow the public account “Machine Learning Algorithms and Natural Language Processing” for more information: