Editor’s Recommendation
This article mainly introduces several works on Difference Convolution led by the University of Oulu and its applications in the fields of images and videos.
Author丨Fisher Yuzi @ Zhihu
Link丨https://zhuanlan.zhihu.com/p/392986663
Related works have been accepted by top journals and conferences such as TPAMI, TIP, CVPR’20, ICCV’21 (Oral), IJCAI’21, and have won two international competition championships (1st Place in the ChaLearn multi-modal face anti-spoofing attack detection challenge with CVPR 2020 [16] and 2nd Place on Action Recognition Track of ECCV 2020 VIPriors Challenges [17]).
1. A Brief Review of the Pioneer LBP
In traditional handcrafted features, a classic example is the LBP (Local Binary Patterns) proposed by Oulu, which has been cited over 16,000 times. The original LBP is defined in a 3×3 neighborhood, using the center pixel value as a threshold to perform differential comparisons with the gray values of the 8 neighboring pixels. If the surrounding pixel values are greater than the center pixel value, that pixel position is marked as 1; otherwise, it is marked as 0. Thus, the 8 points in the neighborhood can produce an 8-bit binary number (usually converted to decimal, resulting in LBP codes, with a total of 256 variations), obtaining the LBP value of the center pixel, which reflects the texture information of that area.

Expressed in the formula:
LBP operator computation is fast, while aggregating differential information within the neighborhood, making it robust to lighting changes; it also describes fine-grained texture information well, thus it has been widely used in early texture recognition and face recognition. The following image shows the LBP code image after performing LBP transformation on a facial image, where the local texture features of the face are well represented:

2. Application of Central Difference Convolution (CDC) in Face Liveness Detection [2,3]
CDC code link: github.com/ZitongYu/CDC
Vanilla convolution typically aggregates local intensity-level information directly, which makes it 1) susceptible to external lighting factors; 2) difficult to represent fine-grained features. In the task of face liveness detection, the former can lead to weak model generalization, such as poor performance under unknown lighting conditions; the latter can result in difficulties in learning the essential details of anti-spoofing, such as the material of the spoof. Considering that spatial differential features have strong lighting invariance and contain finer spoof clues (such as moiré effects, screen reflections, etc.), borrowing from the differential idea of traditional LBP, we propose the Central Difference Convolution (CDC).
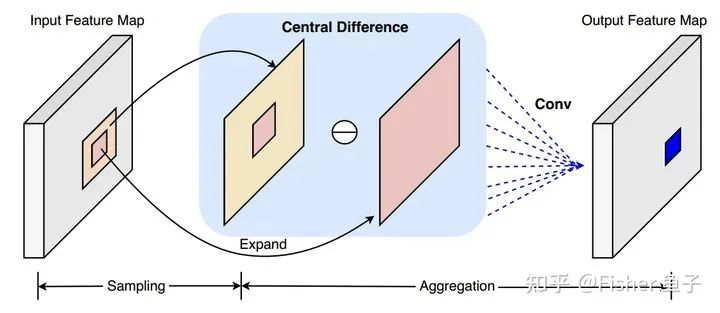
Assuming the neighborhood  is a 3×3 area, the formula is expressed as follows: To better utilize both intensity-level and gradient-level information, we unify VanillaConv and CDC through hyperparameters and shared convolution-learnable weights, without the need for additional learnable parameters (and negligible computational cost). Therefore, the more generalized CDC formula is:
is a 3×3 area, the formula is expressed as follows: To better utilize both intensity-level and gradient-level information, we unify VanillaConv and CDC through hyperparameters and shared convolution-learnable weights, without the need for additional learnable parameters (and negligible computational cost). Therefore, the more generalized CDC formula is:
θ controls the contribution of differential convolution and Vanilla convolution, with a larger value indicating a greater weight on gradient clues; when θ=0, it becomes Vanilla convolution. The article [3] also specifically compares CDC with previous works such as Local Binary Convolution [4], Gabor Convolution [5], and Self-Attention layer [6]; interested readers may refer to the original text.
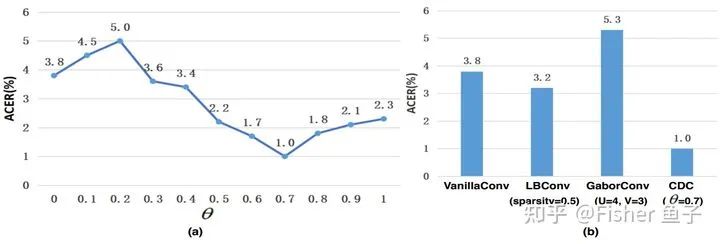
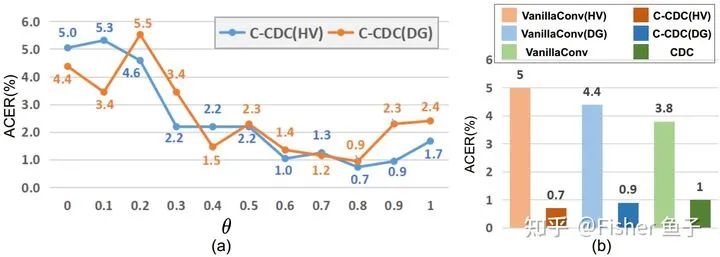
As shown in the figure above, when θ is used, the effect of CDC is always better than that of Vanilla convolution alone (i.e., θ being used). We also observe that when θ is used, the performance of liveness detection under this protocol is optimal and superior to LBConv [4] and GaborConv [5].
3. Application of Cross Central Difference Convolution (C-CDC) in Face Liveness Detection [7]
C-CDC code link:
github.com/ZitongYu/CDC
Considering that CDC requires differential operations on all neighborhood features, which leads to significant redundancy, and the aggregation of gradients in various directions makes network optimization more difficult, we propose Cross Central Difference Convolution (C-CDC), which decouples CDC into two symmetric crossing sub-operators in horizontal, vertical, and diagonal directions:
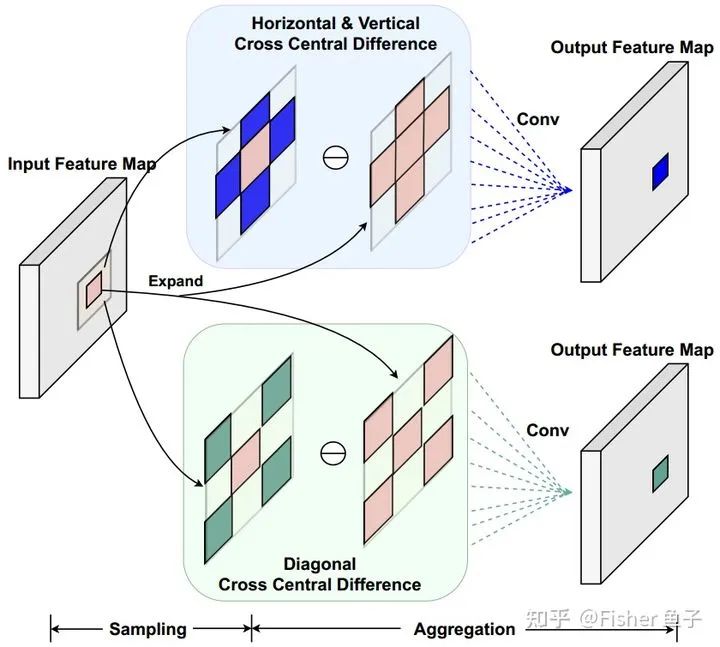
The specific implementation only requires changing the receptive field from the original 3×3 neighborhood  to the corresponding horizontal, vertical, or diagonal sub-neighborhood
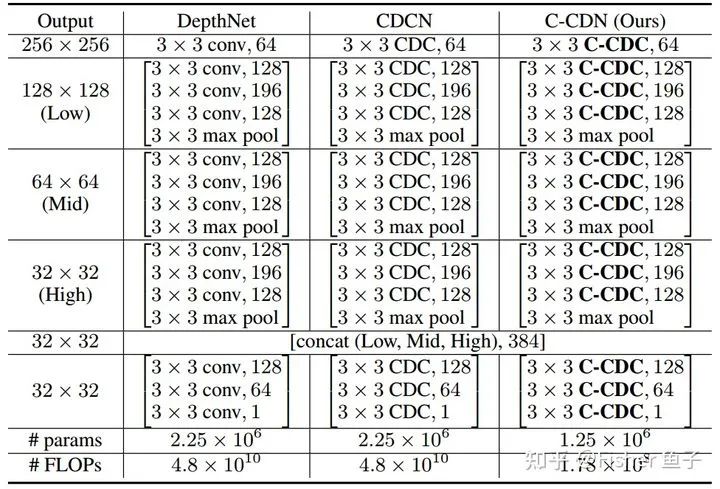
to the corresponding horizontal, vertical, or diagonal sub-neighborhood  . After using C-CDC(HV) or C-CDC(DG), as shown in the table below, the number of network parameters and FLOPs are significantly reduced while achieving performance comparable to the original CDC.
. After using C-CDC(HV) or C-CDC(DG), as shown in the table below, the number of network parameters and FLOPs are significantly reduced while achieving performance comparable to the original CDC.
In the ablation experiment shown in the figure below (b), it can be seen that compared to CDC (ACER=1%), C-CDC(HV) and C-CDC(DG) can also achieve comparable performance. Interestingly, if the VanillaConv is decomposed in HV or DG directions, the performance will drop significantly, as intensity-level information requires a large receptive field.
4. Application of Pixel Difference Convolution (PDC) in Edge Detection [8]
PDC code link:
GitHub – zhuoinoulu/pidinet: Code for ICCV 2021 paper “Pixel Difference Networks for Efficient Edge Detection”
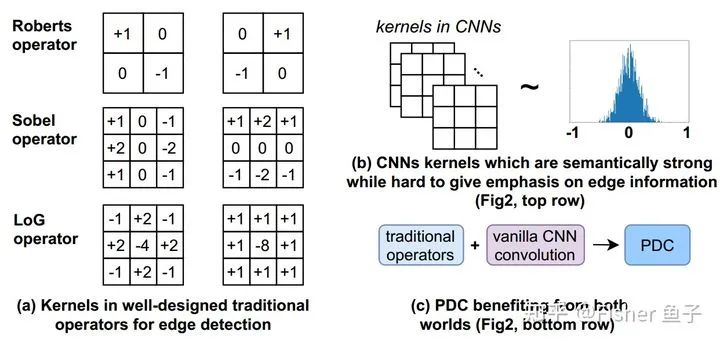
In edge detection, as shown in the figure below (a), classic traditional operators (such as Roberts, Sobel, and LoG) use differential information to represent the abrupt changes and detailed features of edge contexts. However, these models based on traditional handcrafted operators are often limited by their shallow representation capabilities. On the other hand, CNNs can effectively capture semantic features of images through deep stacking of convolutions. In this process, convolutional kernels play a role in capturing local image patterns. As shown in the figure below (b), VanillaCNN does not have explicit gradient encoding constraints during the initialization of convolutional kernels, making it difficult to focus on extracting image gradient information during training, thus affecting the accuracy of edge predictions.
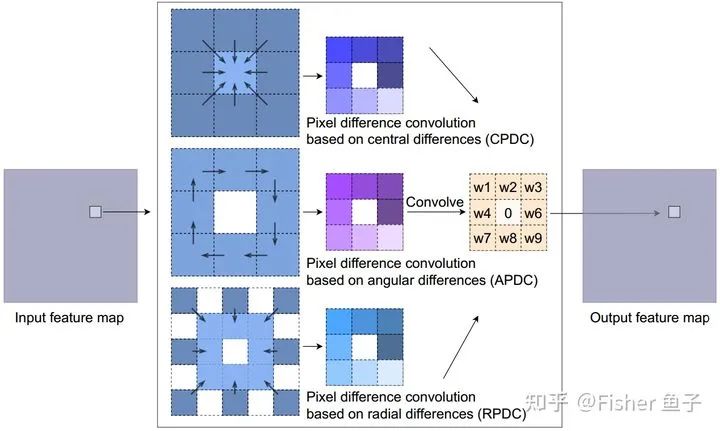
To efficiently introduce differential operations into CNNs, inspired by Extended LBP (ELBP) [9], we propose Pixel Difference Convolution (PDC). According to the sampling strategy of candidate pixel pairs, PDC is specifically divided into three sub-forms as shown in the figure below, where CPDC performs central differences on neighborhood features similar to CDC; APDC performs pairwise differences in a clockwise direction; and lastly, RPDC performs differences between the outer and inner rings of a larger receptive field of 5×5.
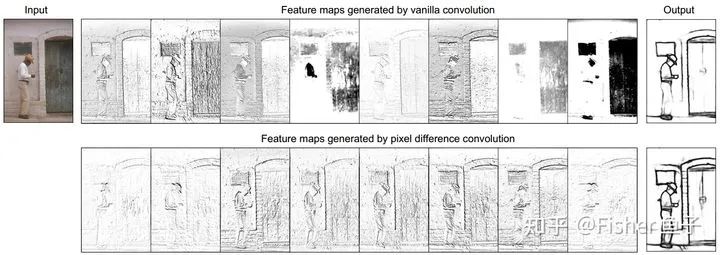
Another contribution of this paper is the proposal to efficiently convert PDC into VanillaConv implementation and derivation proof, that is, first calculate the differences between the weights of the convolution kernels, and then directly convolve the input feature maps. This tweak not only accelerates the training phase but also reduces the additional differential computation during the inference phase. Taking CPDC as an example, the conversion formula is as follows: The specific combination of the three PDC forms for the best effect can be found in the article’s ablation experiments and analysis. Finally, the following figure visualizes the feature maps and edge predictions after using VanillaConv or PDC with the PiDiNet-Tiny network. It is clear that using PDC enhances gradient information, which is beneficial for more precise edge detection.
5. Application of 3D Central Difference Convolution (3D-CDC) in Video Gesture/Action Recognition [10]
3D-CDC code link:
github.com/ZitongYu/3DC
Unlike static spatial image analysis, motion information between frames often plays an important role in spatio-temporal video analysis. Many classic motion operators, such as optical flow and dynamic images, contain frame-internal spatial, frame-inter temporal, and frame-inter spatio-temporal differential information. Current mainstream 3D CNNs generally use vanilla 2D, 3D, or pseudo-3D convolution operations, making it difficult to perceive fine-grained spatio-temporal differential information. Unlike some existing works that design additional modules (such as OFF [11], MFNet [12]), we designed 3D Central Difference Convolution (3D-CDC) to efficiently extract spatio-temporal differential features, which can replace Vanilla3DConv and be directly inserted into any 3D CNN without additional parameter overhead.
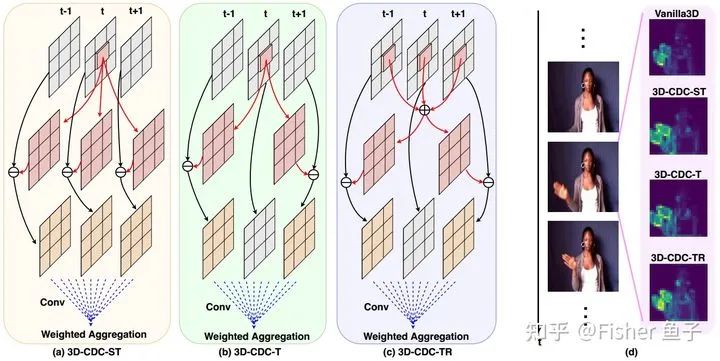
As shown in the figure above, the 3D-CDC family includes three sub-convolutions to enhance temporal features while serving different scenarios. For example, 3DCDC-ST excels at dynamic texture representation; 3D-CDC-T captures more fine temporal contextual information; while 3DCDC-TR is more robust against temporal noise disturbances. Their generalized version formulas are as follows: ( neighboring frames)
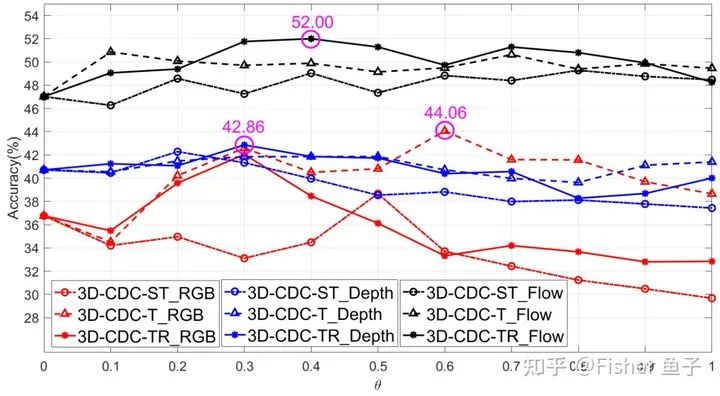
The following figure provides the performance of the C3D model based on the 3D-CDC family, showing that for different modalities (especially RGB and optical flow), under most θ values, 3D-CDC-T and 3D-CDC-TR bring additional video representation benefits ( θ=0 only uses Vanilla3DConv).
6. Other Differential Convolutions and Applications
Literature [13] applied the CDC idea to graph convolutions, forming Central Difference Graph Convolution (CDGC).
Literature [14] applied CDC to real-time saliency detection tasks.
Literature [15] applied 3D-CDC to remote physiological signal rPPG measurement in faces.
Literature [18] applied CDC to face DeepFake detection.
Literature [19] expanded PDC into a random version, applying it to face recognition, expression recognition, and ethnicity recognition.
7. Conclusion and Outlook
On one hand, how to integrate interpretable classical traditional operators (such as LBP, HOG, SIFT, etc.) into the latest DL frameworks (CNN, Vision Transformer, MLP-like, etc.) to enhance performance (such as accuracy, transferability, robustness, efficiency, etc.) will continue to be a hot topic; on the other hand, exploring and applying them to more vision tasks to serve the practical implementation of computer vision will also be crucial.
Reference:
[1] Timo Ojala, et al. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. TPAMI 2002.
[2] Zitong Yu, et al. Searching central difference convolutional networks for face anti-spoofing. CVPR 2020.
[3] Zitong Yu, et al. Nas-fas: Static-dynamic central difference network search for face anti-spoofing. TPAMI 2020.
[4] Juefei Xu, et al. Local binary convolutional neural networks. CVPR 2017.
[5] Shangzhen Luan, et al. Gabor convolutional networks. TIP 2018.
[6] Ramachandran Prajit, et al. Stand-alone self-attention in vision models. NeurIPS 2019.
[7] Zitong Yu, et al. Dual-Cross Central Difference Network for Face Anti-Spoofing. IJCAI 2021.
[8] Zhuo Su, et al. Pixel Difference Networks for Efficient Edge Detection. ICCV 2021 (Oral)
[9] Li Liu, et al. Extended local binary patterns for texture classification. Image and Vision Computing 2012.
[10] Zitong Yu, et al. Searching multi-rate and multi-modal temporal enhanced networks for gesture recognition. TIP 2021.
[11] Shuyang Sun, et al. Optical flow guided feature: A fast and robust motion representation for video action recognition. CVPR 2018.
[12] Myunggi Lee, et al. Motion feature network: Fixed motion filter for action recognition. ECCV 2018.
[13] Klimack, Jason. A Study on Different Architectures on a 3D Garment Reconstruction Network. MS thesis. Universitat Politècnica de Catalunya, 2021.
[14] Zabihi Samad, et al. A Compact Deep Architecture for Real-time Saliency Prediction. arXiv 2020.
[15] Zhao Yu, et al. Video-Based Physiological Measurement Using 3D Central Difference Convolution Attention Network. IJCB 2021.
[16] Zitong Yu, et al. Multi-modal face anti-spoofing based on central difference networks. CVPRW 2020.
[17] Haoyu Chen, et al. 2nd place scheme on action recognition track of ECCV 2020 VIPriors challenges: An efficient optical flow stream guided framework. arXiv 2020.
[18] Yang et al. MTD-Net: Learning to Detect Deepfakes Images by Multi-Scale Texture Difference, TIFS 2021
[19] Liu et al. Beyond Vanilla Convolution: Random Pixel Difference Convolution on Face Perception. IEEE Access 2021
