

Source: Fundamentals and Advanced Topics in Deep Learning
This article is approximately 3100 words and is recommended for a 10-minute read.
Feature extraction is an important topic in computer vision. Whether it is SLAM, SFM, 3D reconstruction, or other important applications, the foundation lies in the reliable extraction and matching of feature points across images.
Feature extraction has remained a hot research topic in the field of computer vision. In general, fast, accurate, and robust feature point extraction is a basic requirement for achieving higher-level tasks.
Feature points are pixels in an image where the gradient changes sharply, such as corners and edges. FAST (Features from Accelerated Segment Test) is a high-speed corner detection algorithm, while the Scale-Invariant Feature Transform (SIFT) is perhaps the most famous traditional local feature point, and it remains widely used to this day. Feature extraction generally includes two processes: feature point detection and descriptor computation. Descriptors are a means of measuring feature similarity, used to determine corresponding spatial objects in different images, such as the BRIEF (Binary Robust Independent Elementary Features) descriptor. Reliable feature extraction should include the following characteristics:
(1) Invariance to rotation and scale changes;(2) Strong adaptability to changes in 3D perspective and lighting;(3) Local features remain invariant even in occlusion and cluttered scenes;(4) Strong ability to differentiate between features, facilitating matching;
(5) A large quantity, generally around 2000 feature points can be extracted from a 500×500 image.
In recent years, the rise of deep learning has led many scholars to attempt to use deep networks to extract feature points from images, achieving some stage results. Figure 1 shows the characteristics of different feature extraction methods. In this article, traditional algorithms are exemplified by ORB features, while deep learning is exemplified by SuperPoint to illustrate their principles and compare performance.
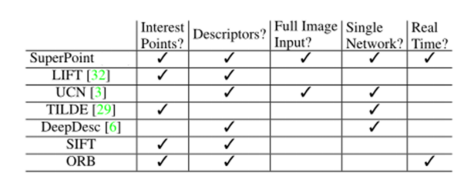 Figure 1 Comparison of Different Feature Extraction Methods
Figure 1 Comparison of Different Feature Extraction Methods
Traditional Algorithm – ORB Features
Although SIFT is the most famous method for feature extraction, its large computational load prevents it from being used in some real-time applications. To study a feature extraction algorithm that is both fast and accurate, Ethan Rublee et al. proposed ORB features in 2011: “ORB: An Efficient Alternative to SIFT or SURF”. The ORB algorithm is divided into two parts: feature point extraction and feature point description. ORB features combine the detection method of FAST feature points with the BRIEF feature descriptor, and improvements and optimizations are made based on their original foundations. Its speed is 100 times that of SIFT and 10 times that of SURF.
FAST Feature Extraction
Select a point P from the image, as shown in Figure 2. The following steps determine whether this point is a feature point: draw a circle with a radius of 3 pixels centered at P; compare the gray values of the pixels on the circumference to find pixels with gray values exceeding l(P) + h and below l(P) – h, where l(P) is the gray value at point P, and h is a given threshold; if there are n consecutive pixels that meet the condition, then P is considered a feature point. Generally, n is set to 9. To speed up feature point extraction, the gray values at positions 1, 9, 5, and 13 are first detected; if P is a feature point, then at least 3 of the 4 positions must meet the condition. If not, this point is discarded.

Figure 2 Illustration of FAST Feature Point Determination
The number of FAST corner points detected through the above steps is large and uncertain; therefore, ORB improves upon this. For K key points, the original FAST corner points are calculated for their Harris response values, and then the feature points are sorted based on these response values, selecting the top K corner points with the largest responses as the final corner point set. Additionally, FAST lacks scale invariance and rotation invariance. The ORB algorithm builds an image pyramid, performs downsampling at different levels to obtain images of varying resolutions, and detects corner points at each level of the pyramid to obtain multi-scale features. Finally, the main direction of the feature points is calculated using the gray centroid method. The authors use moments to compute the centroid within the radius range of the feature point, and the vector formed from the feature point coordinates to the centroid serves as the direction of that feature point. The moment is defined as follows:
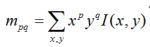
Calculate the 0th and 1st moments of the image:
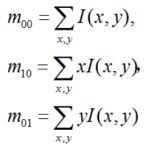
The centroid of the feature point’s neighborhood is:
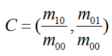
Further obtain the main direction of the feature point:
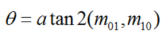
Descriptor Calculation
The BRIEF algorithm computes a binary string feature descriptor, characterized by high speed and low storage requirements. The specific steps involve selecting n pairs of pixel points pi, qi (i=1,2,…,n) within the neighborhood of a feature point. Then, the gray values of each pair are compared. If I(pi) > I(qi), a 1 is generated in the binary string; otherwise, a 0 is generated. By comparing all point pairs, a binary string of length n is generated. Typically, n is set to 128, 256, or 512. Additionally, to enhance the noise resistance of the feature descriptor, the algorithm first applies Gaussian smoothing to the image. When selecting point pairs, the authors tested 5 patterns to find the optimal feature point matching pattern.

Figure 3 Testing Distribution Methods
The final conclusion is that the second mode (b) can achieve better matching results.
Deep Learning Approach – SuperPoint
The deep learning approach to feature point extraction utilizes deep neural networks to extract feature points instead of manually designing features. Its feature detection performance is closely related to the training samples and network structure. It is generally divided into a feature detection module and a descriptor computation module. Here, we introduce the main idea of this method using the widely applied SuperPoint as an example.
This method employs a self-supervised fully convolutional network framework, training to obtain feature points (keypoints) and descriptors. Self-supervised means that the dataset used for training the network is also constructed using deep learning methods. The network can be divided into three parts (see Figure 1), (a) is the BaseDetector (feature point detection network), (b) is the ground truth self-calibration module, and (c) is the SuperPoint network, which outputs feature points and descriptors. Although it is based on a deep learning framework, this method can output detection results at 70HZ on a Titan X GPU, fully meeting real-time requirements.
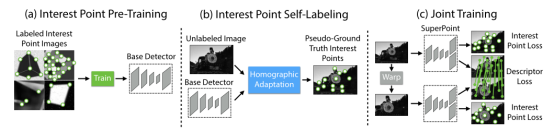
Figure 4 Illustration of SuperPoint Network Structure
Next, we will introduce each of the three parts:
BaseDetector Feature Point Detection:
First, a large-scale synthetic dataset is created: synthetic data consisting of rendered triangles, quadrilaterals, lines, cubes, chessboards, and stars, each with true corner positions. After rendering synthetic images, homographic transformations are applied to each image to increase the training dataset. The homographic transformation corresponds to the true positions of corners after transformation. To enhance its generalization capability, the authors also artificially added some noise and shapes without feature points, such as ellipses, to the images. This dataset is used to train the MagicPoint convolutional neural network, i.e., the BaseDetector. Note that the detected feature points here are not SuperPoint; they still require the Homographic Adaptation operation.
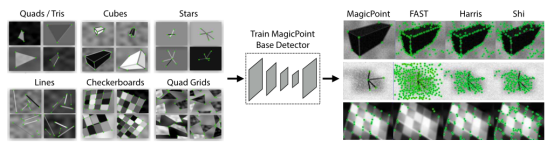
Figure 5 Pre-training Illustration
The performance of feature detection is shown in the following table:
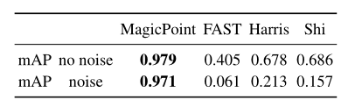
Figure 6 The MagicPoint model outperforms classic detectors in detecting corner points of simple geometric shapes
Ground Truth Self-Calibration:
Homographic Adaptation aims to achieve self-supervised training of interest point detectors. It applies homographic transformations to the input images multiple times to help the interest point detector see the scene from many different viewpoints and scales. This improves the detector’s performance and generates pseudo-ground truth feature points.
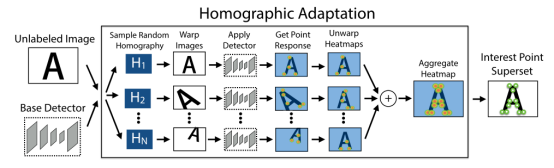
Figure 7 Homographic Adaptation Operation
Homographic Adaptation can improve the geometric consistency of feature point detectors trained by convolutional neural networks. This process can be repeated to continuously self-supervise and improve the feature point detector. In all our experiments, the model we refer to as SuperPoint combines the Homographic Adaptation with the MagicPoint detector.

Figure 8 Iterative Homographic Adaptation
SuperPoint Network:
SuperPoint is a fully convolutional neural network architecture that runs on full-size images and produces feature point detection with fixed-length descriptors in a single forward pass (see Figure 9). The model has a shared encoder that processes and reduces the dimensionality of the input image. After the encoder, the architecture is divided into two decoder “heads” that learn weights for specific tasks—one for feature detection and the other for descriptor computation. Most of the network parameters are shared between the two tasks, which is different from traditional systems that first detect interest points and then compute descriptors, lacking the ability to share computation and representation between the two tasks.
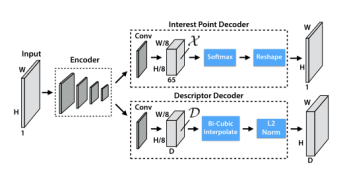
Figure 9 SuperPoint Decoders
The SuperPoint architecture uses a VGG-like encoder to reduce the dimensionality of the images. The encoder consists of convolutional layers, spatial downsampling through pooling, and nonlinear activation functions. The descriptor output network is also a decoder. It first learns semi-dense descriptors (not using dense methods to reduce computational load and memory), and then uses bicubic interpolation to obtain complete descriptors, finally applying L2 normalization to achieve unit length descriptors.
The final loss is the sum of two intermediate losses: one for the interest point detector Lp and the other for the descriptor Ld. We use paired synthetic images that have true feature point positions and ground truth correspondences derived from a randomly generated homography H related to the two images. Both losses are optimized simultaneously, as shown in Figure 4c. The final loss is balanced using λ:
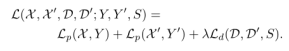
Comparison of Experimental Results:
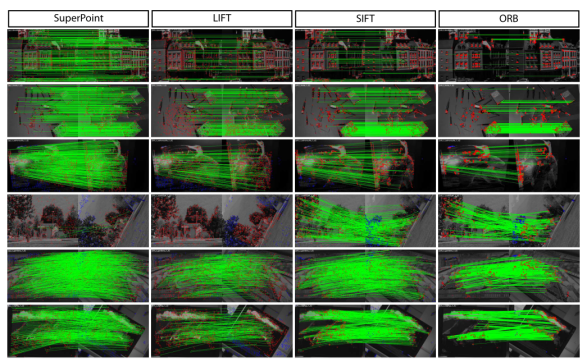
Figure 10 Qualitative Comparison of Different Feature Detection Methods
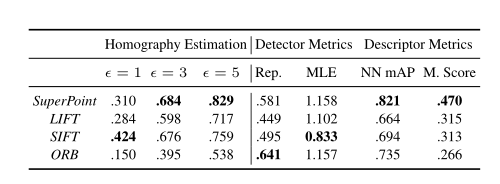
Figure 11 Performance Metrics of Detectors and Descriptors
Conclusion
In feature detection, traditional methods have developed feature detection methods and descriptors through extensive empirical design. Although these features still face robustness issues under significant lighting changes and large rotation angles, they remain the most widely used and mature methods today. For example, ORB features used in ORB-SLAM and FAST features used in VINS-Mono are traditional feature points. Deep learning methods have shown excellent performance in feature detection, but:
(1) There are issues of model interpretability;(2) In terms of detection and matching accuracy, they still do not exceed the classic SIFT algorithm;(3) Most deep learning solutions perform poorly in real-time on CPUs and require GPU acceleration;(4) Training requires a large amount of image data from different scenes, making training difficult.
In the final Homography Estimation metrics, SuperPoint outperformed traditional algorithms, but this evaluates the accuracy of homographic transformations. Homographies do not encompass all image transformations. For example, transformations with general properties such as fundamental matrices or essential matrices may perform worse than traditional methods.
Editor: Huang Jiyan
About Us
Data Science THU is a public account focused on data science, backed by the Tsinghua University Big Data Research Center, sharing cutting-edge data science and big data technology innovation research dynamics, continuously disseminating data science knowledge, and striving to build a platform for data talent aggregation, creating the strongest group in China for big data.
Sina Weibo: @数据派THU
WeChat Video Account: 数据派THU
Today's Headlines: 数据派THU