↑ ClickBlue Text Follow the Jishi PlatformAuthor丨pprpSource丨GiantPandaCVEditor丨Jishi Platform
Jishi Guide
The CBAM module has gained a lot of applications due to its widespread use and ease of integration. Currently, the Attention mechanism in the CV field is also very popular in papers published in 2019. Although this CBAM was proposed in 2018, its influence is profound, and it has been used in many fields. >> Join the Jishi CV technology exchange group to stay at the forefront of computer vision.
1. What is the Attention Mechanism?
The Attention Mechanism is a data processing method in machine learning, widely used in various types of machine learning tasks such as natural language processing, image recognition, and speech recognition.In simple terms: the attention mechanism aims for the network to automatically learn where to focus within an image or a sequence of text. For example, when a person looks at a painting, they do not distribute their attention equally among all pixels in the painting but rather allocate more attention to the areas that people care about.From an implementation perspective: the attention mechanism generates a mask through operations in a neural network, where the values on the mask score the points that need to be focused on.The attention mechanism can be divided into:
Channel Attention Mechanism: generates a mask for the channel, scores it, represented by senet, Channel Attention Module
Spatial Attention Mechanism: generates a mask for the spatial dimension, scores it, represented by Spatial Attention Module
Mixed Domain Attention Mechanism: evaluates and scores both channel and spatial attention simultaneously, represented by BAM, CBAM
2. Implementation of the CBAM Module
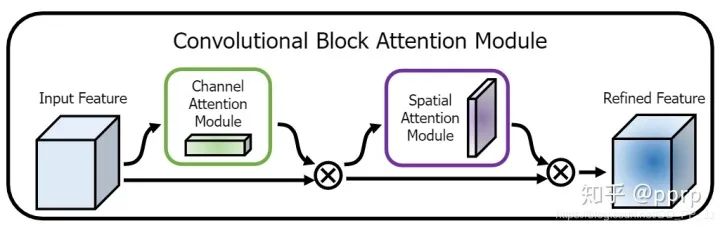
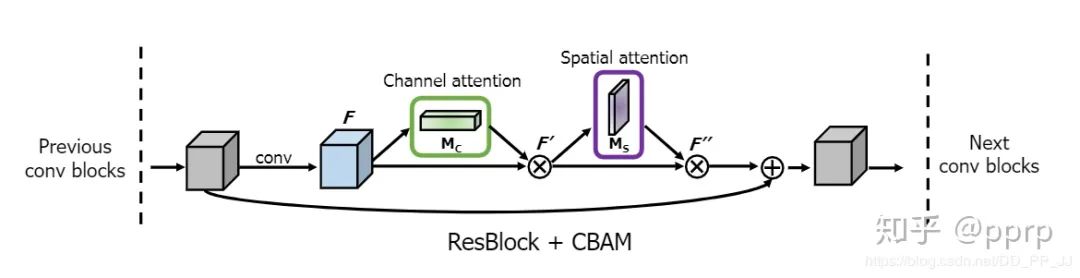
CBAM stands for Convolutional Block Attention Module and is one of the representative works of attention mechanisms published at **ECCV2018**. I have seen people use this module to achieve first place in competitions, proving its effectiveness.In this paper, the authors studied attention in network architectures, which not only tells us where to focus but also enhances the representation of the focus points. The goal is to use the attention mechanism to increase expressiveness, focusing on important features and suppressing unnecessary ones. To emphasize meaningful features in both spatial and channel dimensions, the authors sequentially apply channel and spatial attention modules to learn what to focus on and where to focus. Additionally, understanding what information to emphasize or suppress also aids in the flow of information within the network.The main network architecture is quite simple, consisting of a channel attention module and a spatial attention module, where CBAM integrates the channel attention module and the spatial attention module in succession.
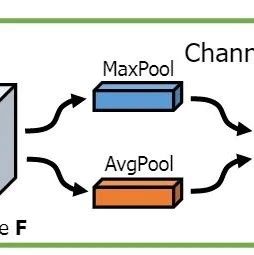
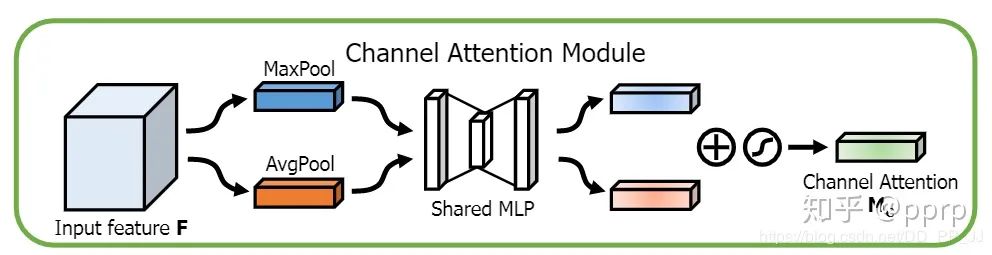
2.1 Channel Attention Mechanism
The channel attention mechanism is implemented as shown in the figure above:
The core part, Shared MLP, uses 1×1 convolutions to extract information. It is important to note that the bias needs to be manually set to False.
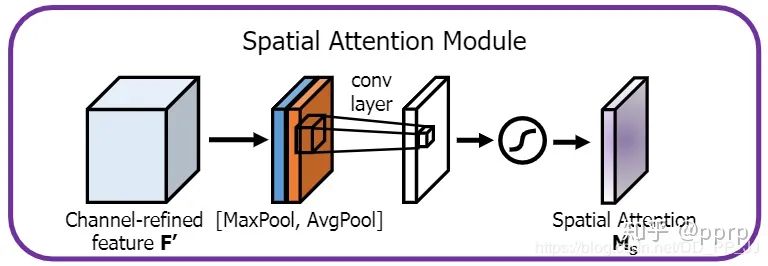
2.2 Spatial Attention Mechanism
The spatial attention mechanism is implemented as shown in the figure above:
class SpatialAttention(nn.Module): def __init__(self, kernel_size=7): super(SpatialAttention, self).__init__() assert kernel_size in (3,7), "kernel size must be 3 or 7" padding = 3 if kernel_size == 7 else 1 self.conv = nn.Conv2d(2,1,kernel_size, padding=padding, bias=False) self.sigmoid = nn.Sigmoid() def forward(self, x): avgout = torch.mean(x, dim=1, keepdim=True) maxout, _ = torch.max(x, dim=1, keepdim=True) x = torch.cat([avgout, maxout], dim=1) x = self.conv(x) return self.sigmoid(x)
This part is also simple; it computes the average and maximum along the channel dimension, merges them into a convolution layer with 2 channels, and then applies a convolution to obtain a spatial attention with 1 channel.
2.3 Convolutional Bottleneck Attention Module
class BasicBlock(nn.Module): expansion = 1 def __init__(self, inplanes, planes, stride=1, downsample=None): super(BasicBlock, self).__init__() self.conv1 = conv3x3(inplanes, planes, stride) self.bn1 = nn.BatchNorm2d(planes) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(planes, planes) self.bn2 = nn.BatchNorm2d(planes) self.ca = ChannelAttention(planes) self.sa = SpatialAttention() self.downsample = downsample self.stride = stride def forward(self, x): residual = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.ca(out) * out # Broadcasting mechanism out = self.sa(out) * out # Broadcasting mechanism if self.downsample is not None: residual = self.downsample(x) out += residual out = self.relu(out) return out
Finally, a class is used to integrate the two modules, and after obtaining the channel and spatial attention, the broadcasting mechanism is applied to refine the information in the original feature map, ultimately obtaining the refined feature map. The above code treats modules in ResNet, and in practical applications, the following modules can be integrated into the network:
class cbam(nn.Module): def __init__(self, planes): self.ca = ChannelAttention(planes) # planes is the number of channels in the feature map self.sa = SpatialAttention() def forward(self, x): x = self.ca(out) * x # Broadcasting mechanism x = self.sa(out) * x # Broadcasting mechanism
3. When Can It Be Used?
The authors who proposed CBAM mainly conducted experiments on classification networks and object detection networks, proving that the CBAM module is indeed effective.Taking ResNet as an example, the paper provides a schematic diagram of the transformation, as shown in the figure below:This means that the CBAM module is added to each block in ResNet, with training data sourced from the benchmark ImageNet-1K. The detection uses Faster R-CNN, with backbones chosen as ResNet34, ResNet50, WideResNet18, ResNeXt50, etc., and comparisons were made with SE, among others.Ablation Experiment: Ablation experiments generally control variables to see which parts of the model contribute most to its improvement. It is divided into three parts:
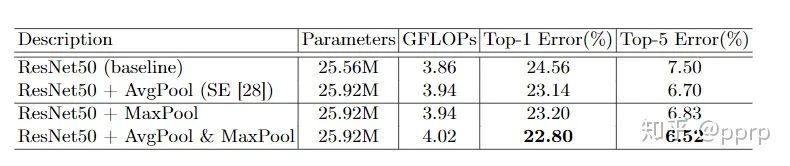
How to calculate channel attention more effectively?
It can be seen that using avgpool and maxpool can better reduce the error rate, with about a 1-2% improvement. This combination, known as dual pooling, provides more detailed information, which is beneficial for improving model performance.
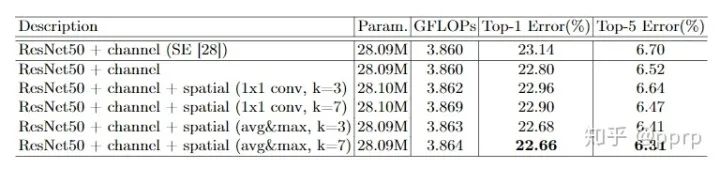
How to calculate spatial attention more effectively?
Here, the spatial attention mechanism parameters also consist of avg and max, along with a convolution parameter kernel_size(k). From the above experiments, it can be seen that using both channel average and maximum, with kernel size set to 7, yields the best results.
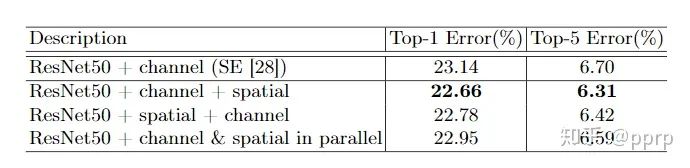
How to organize these two parts?
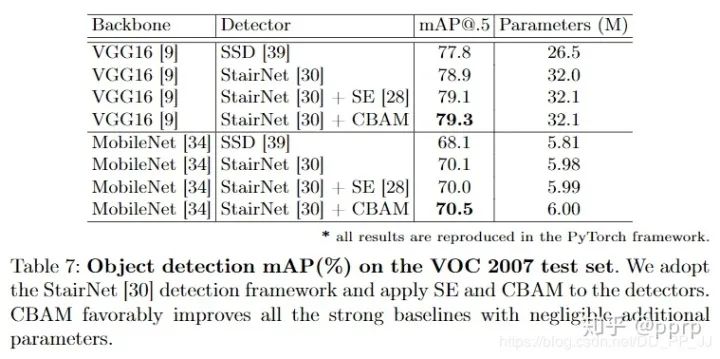
It can be seen that a comparison was also made with the SE module in SENet, where using CBAM exceeded the performance of SE. Additionally, sequential and parallel tests were conducted, revealing that performing channel attention first followed by spatial attention yields the best results, thus forming the final composition of the CBAM module.In the MSCOCO dataset, models using ResNet50 and ResNet101 as backbones and Faster R-CNN as detectors were tested, as shown in the figure below:In the VOC2007 dataset, StairNet was used for testing, as shown in the figure below:It seems that the official code for the object detection part is not provided. The role of CBAM is to refine the allocation and processing of information, so it is speculated that the CBAM module is added before the classifier in the backbone. Any researchers interested are welcome to leave comments.