This article will cover the essence of Softmax in terms of its principle and applications, helping you understand the Softmax function in one go.
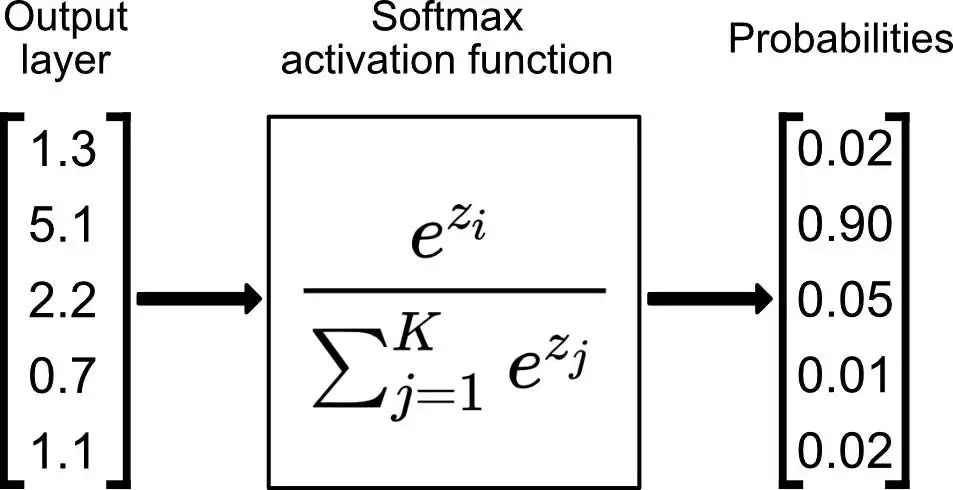
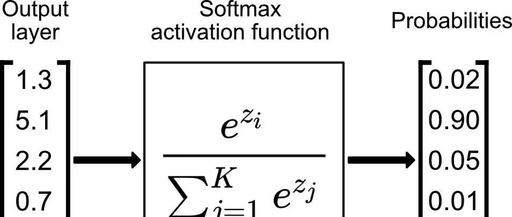
Softmax Activation Function
1. Essence of Softmax Essence

In the field of machine learning, classification problems are generally considered supervised learning. The goal of classification is to determine which known sample class a new sample belongs to based on certain features of known samples.
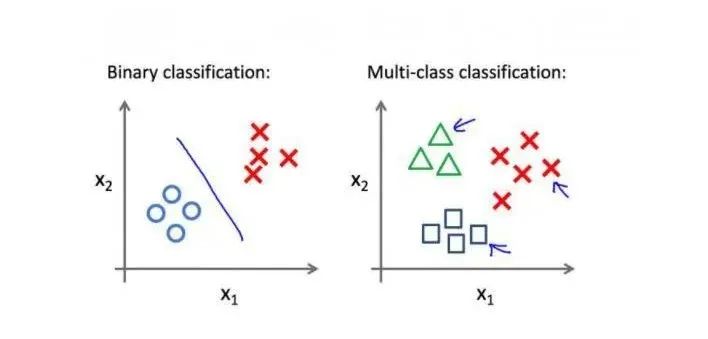
Classification problems can be divided into binary classification and multi-class classification based on the number of categories.
-
Binary Classification: Indicates there are two categories in the classification task. In binary classification, we typically use common algorithms such as logistic regression, support vector machines, etc.
-
Multi-class Classification: Indicates there are multiple categories in the classification task. In multi-class classification, we can use common algorithms such as decision trees, random forests, etc.
Understanding Classification Problems in Detail:Neural Network Algorithms – Understanding Regression and Classification
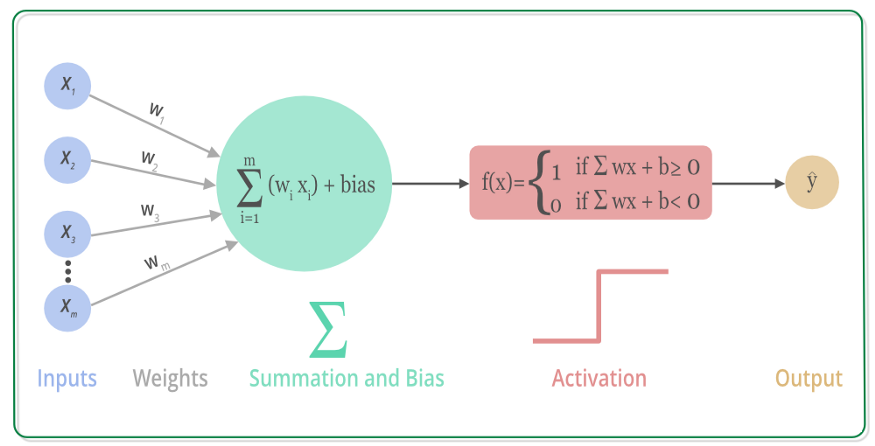
Activation Function: A function added to artificial neural networks to help the network learn complex patterns in data.
Activation functions introduce non-linear elements into neural networks, enabling the network to approximate complex non-linear functions and thus solve a wider range of problems.
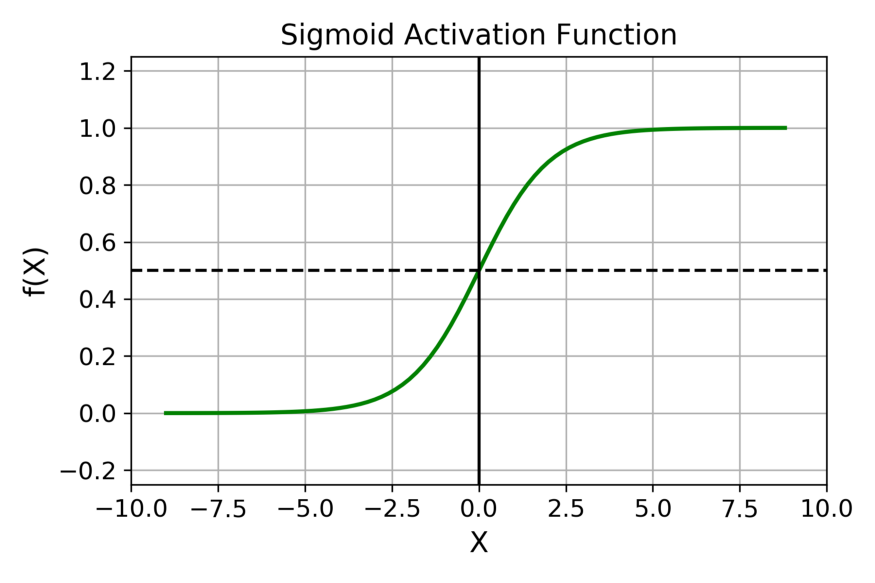
For binary classification problems, Sigmoid is a commonly used activation function that maps any real number to the interval (0, 1), where values can naturally be interpreted as probabilities.
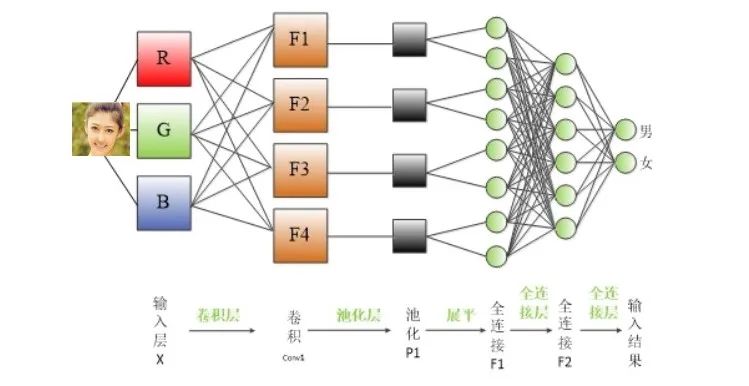
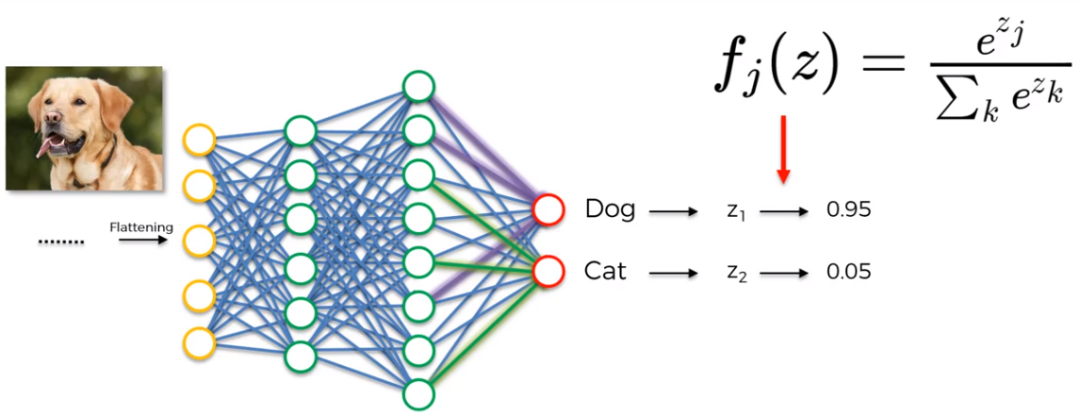
For multi-class problems, Softmax is a very important tool. It can convert a vector into a set of probability values, with the sum of these probabilities equal to 1.

Learn More About Activation Functions:Understand AI – Four Common Activation Functions: Sigmoid, Tanh, ReLU, and Softmax
2. Principle of Softmax Principle
Principle of Neural Networks: Calculate predicted values through forward propagation, measure the gap between predicted values and true values through loss functions, compute gradients and update parameters through backpropagation, and introduce non-linear factors through activation functions.
-
Forward Propagation: Data flows from the input layer through the hidden layers to the output layer, with each layer performing linear transformations through weights and biases, and obtaining non-linear outputs through activation functions.
-
Activation Function: Introduces non-linearity to neural networks, enhancing the model’s expressive power.
-
Loss Function: Measures the gap between predicted values and true values, such as mean squared error for regression and cross-entropy for classification.
-
Backpropagation: Calculates the gradients of parameters layer by layer from the output layer to the input layer based on the gradient information of the loss function, updating parameters to minimize the loss function value.
-
Gradient Descent: An optimization algorithm that updates network parameters based on calculated gradients at a certain learning rate, gradually approaching the optimal solution.
Learn More About Gradient Descent:Neural Network Algorithms – Understanding Gradient Descent
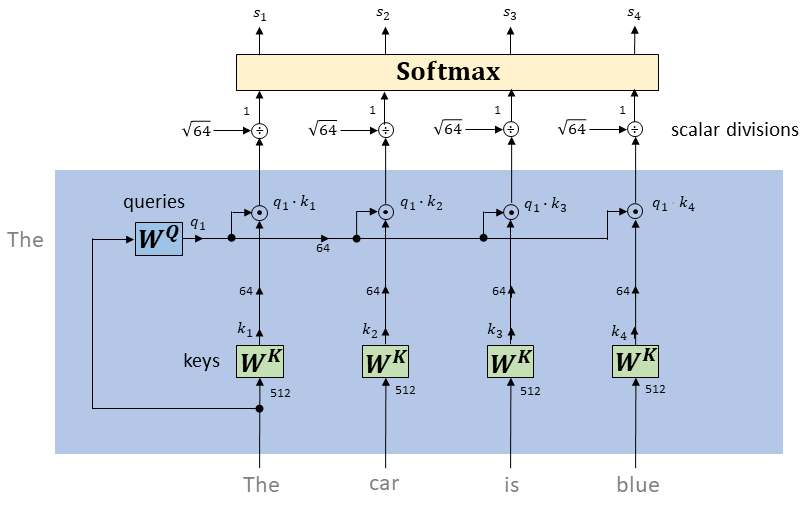
Mathematical Principle of Softmax: For a given real-valued vector, it first calculates the exponent (e to the power) of each element, then the ratio of each element’s exponent to the total exponent of all elements forms the output of the softmax function. This computation not only keeps the output values between 0 and 1 but also ensures that the sum of all output values equals 1.
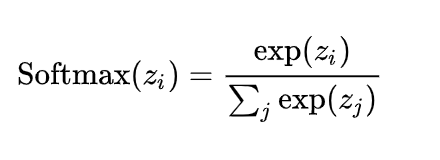
3. Applications of Softmax