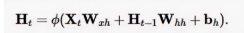Regarding the calculation of RNN parameters, the PPT does not explain it very clearly, as it only contains images without text. At the same time, the textbook version by Qizhi Yao does not provide any exercises related to RNN parameter calculation, and the final exam may only test based on the descriptions in the images, which should not be too difficult.
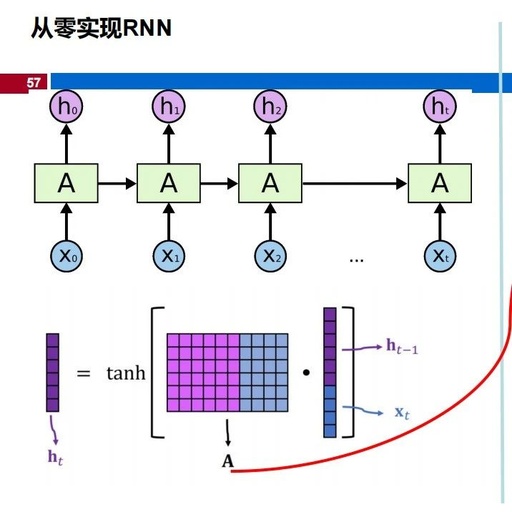
In class, the main reference should be the following 2 pages of the PPT:
Below is an interpretation of the content on these two pages of the PPT:
First, it should be stated that the various subscripts of the variables in this part are a bit messy, so when you look at them, focus on what they represent. During the exam, they should also explain what each quantity means, and it is unlikely that they will ask you to memorize the subscripts.
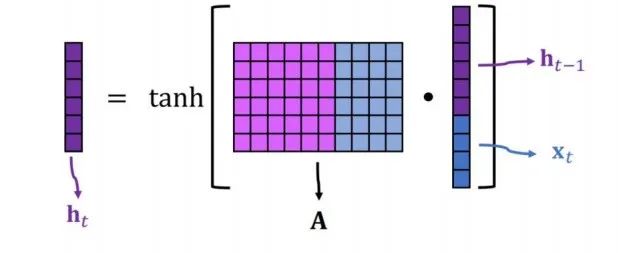
In this formula, H represents the activation output of the current neuron;
Φ represents any activation function of the neuron (which can be Sigmoid, Tanh, or ReLU);
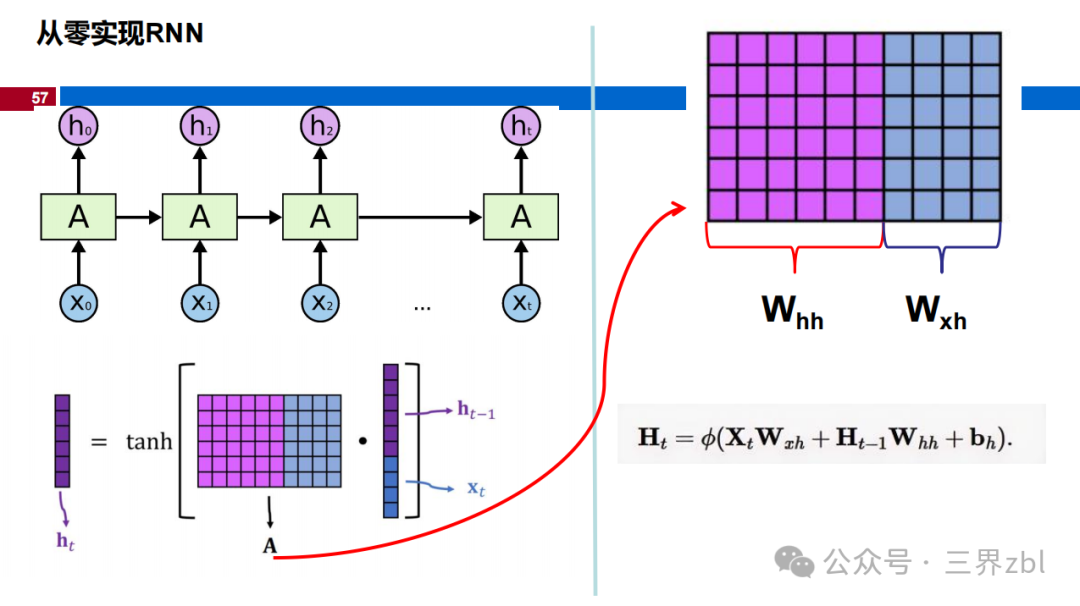
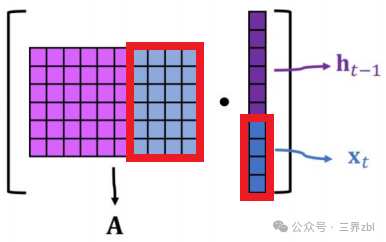
XtWxh represents the product of the input signal X at the current time step (or layer) and the weight matrix Wxh. Here, Xt is an input vector, and Wxh is a weight matrix, and their product represents the result of the input signal after being adjusted by the weights. You can see the deep blue part in the grid diagram (highlighted in red in the image below), which expresses this part of the variable.
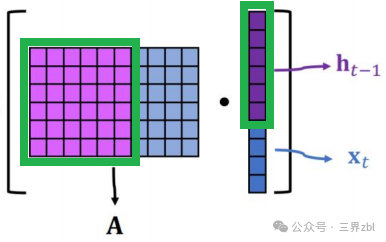
H_{t-1}W_hh represents the product of the hidden state H_{t-1} from the previous time step (or layer) and the weight matrix W_hh. This part reflects the recurrent connection in the neural network, meaning that the output of the current neuron will be influenced by the hidden state from the previous time step (or layer). You can see the purple part in the grid diagram (highlighted in green in the image below), which expresses this part of the variable.
b_h represents the bias term. The bias term is a constant used to adjust the output of the neuron. It can be viewed as an additional input whose value is always 1, but the corresponding weight (i.e., bias weight) is learnable.
You may notice the tanh in the image below; tanh is one of the activation functions. In RNNs, Sigmoid, Tanh, and ReLU (Rectified Linear Unit) can all be used as activation functions. The activation function will affect the results of the RNN, but it will not affect the number of parameters in the RNN.
So we can summarize that:
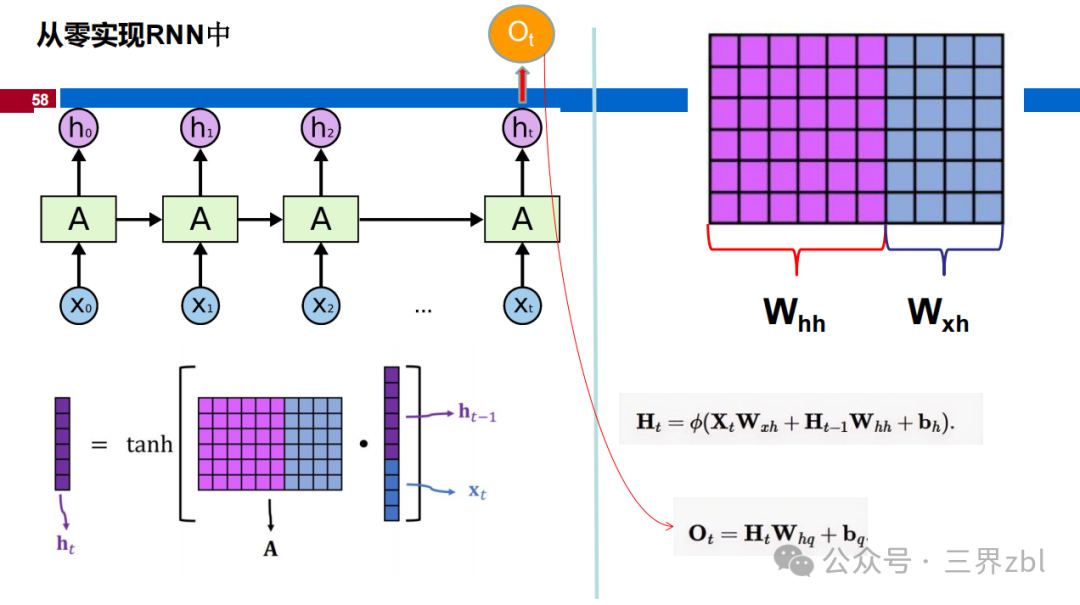
For an RNN with an input sequence length of T, an input layer with m neurons, a hidden layer with n neurons, and an output layer with p neurons. If we consider the bias term, then
Below is an example problem:
Assuming we have a simple RNN (Recurrent Neural Network) with an input layer of 10 neurons, a hidden layer of 20 neurons, and an output layer of 5 neurons. Each neuron uses ReLU as the activation function, and we do not consider the bias term. Please answer:
1. What is the size of the input weight matrix W_xh?
2. What is the size of the weight matrix W_hh from hidden state to hidden state?
3. What is the size of the weight matrix W_hy from hidden layer to output layer?
The size of the input weight matrix W_xh is (20,10). Because the hidden layer has 20 neurons, each neuron is connected to the 10 neurons in the input layer.
The size of the weight matrix W_hh from hidden state to hidden state is (20,20). Because the hidden layer has 20 neurons, each neuron is connected to the 20 neurons in the hidden layer (including itself).
The size of the weight matrix W_hy from hidden layer to output layer is (5,20). Because the output layer has 5 neurons, each neuron is connected to the 20 neurons in the hidden layer.